scrapy介绍
名词介绍:
- 引擎(engine)
scrapy的核心,负责模块之间的衔接 - 调度器(scheduler)
存放我们要爬取的URL地址,可以看成一个URL容器,它决定着我们下一步要去爬取哪个URL - 爬虫(spider)
主程序吧,大部分代码在这里写,主要负责解析response中的数据解析,拿到我们想要的数据 - 管道(pipeline)
数据存放的地方,管道可以有多个,按照优先级来,数越小,优先级越高 - 下载器(download)
负责发送request请求,将结果直接打包成可以解析的数据,交给爬虫
scrapy工作流程:
- 爬虫(spider)从其实url构造成requests对象传递给调度器
- 引擎(engine)从调度器中获取到request对象交给下载器
- 由下载器(downloader)获取到页面源代码,在交给引擎
- 引擎将获取到的原码交给spider ,spider对数据进行解析(parse)并返还给引擎
使用方法:
1.在终端里移动到项目所在地址
scrapy startproject 【项目名字】 # 使用scrapy创建项目
2.cd到刚才的项目里面,创建目标
scrapy genspider 【名字】【目标URL】
项目实战
主程序里面:
import scrapy
class Game4399Spider(scrapy.Spider):
name = "game4399"
allowed_domains = ["4399.com"]
start_urls = ["http://4399.com/flash"]
def parse(self, response):
lis = response.xpath('//ul[@class="n-game cf"]/li')
for li in lis:
name = li.xpath('./a/b/text()').extract_first()
link = 'http://www.4399.com' + li.xpath('./a/@href').extract_first()
dic = {
"name": name,
"link": link,
}
yield dic
setting里面把不需要的日志取消显示,只显示错误信息就够用了,把这行加上去
LOG_LEVEL = 'ERROR'
还要在里面打开项目管道,scrapy默认是关闭的,找到这几行代码,取消注释即可
ITEM_PIPELINES = {
"game.pipelines.GamePipeline": 300,
"game.pipelines.NewPipeline": 200,
}
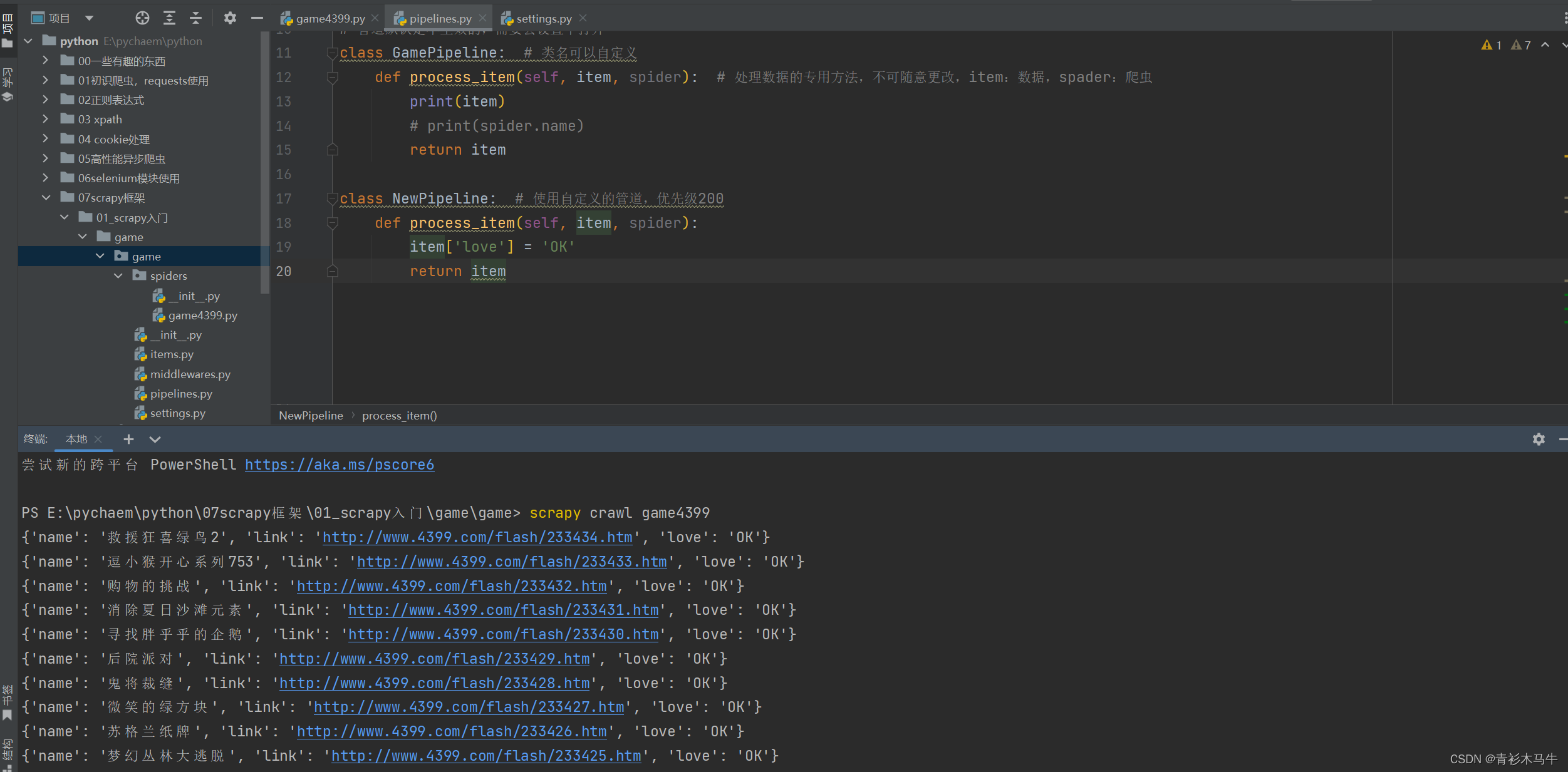
pipelines里面的代码:
class GamePipeline:
def process_item(self, item, spider):
return item
class NewPipeline:
def process_item(self, item, spider):
item['love'] = 'OK'
return item
最后执行scrapy crawl [项目名字]
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)