数据容量单位: 1 byte = 8 bits 1 kilobyte (KB) = 1024 bytes 1 megabyte (MB) = 1024 KB 1 gigabyte (GB) = 1024 MB 1 terabyte (TB) = 1024 GB 1 petabyte (PB) = 1024 TB 1 exabyte (EB) = 1024 PB 1 zettabyte (ZB) = 1024 EB 1 yottabyte (YB) = 1024 ZB
. 当前大数据技术的基础是由谷歌首先提出的
. 智能健康手环的应用开发,体现了传感器的数据采集技术的应用。
. Linux 发行版本:Ubuntu、Centos、RedHat Enterprise Linux Mac 不是 Linux 发行版本
. 数据产生方式经历了从传统模式到数字化模式、离线数据到在线数据、单一数据到多样化数据、结构化数据到非结构化数据、个人数据到群体数据的变革。
. 大数据的特征通常被总结为4V:数据量(Volume)、数据处理速度(Velocity)、数据多样性(Variety)和数据真实性(Veracity)。
. 大数据构成:
. 大数据相关环节:
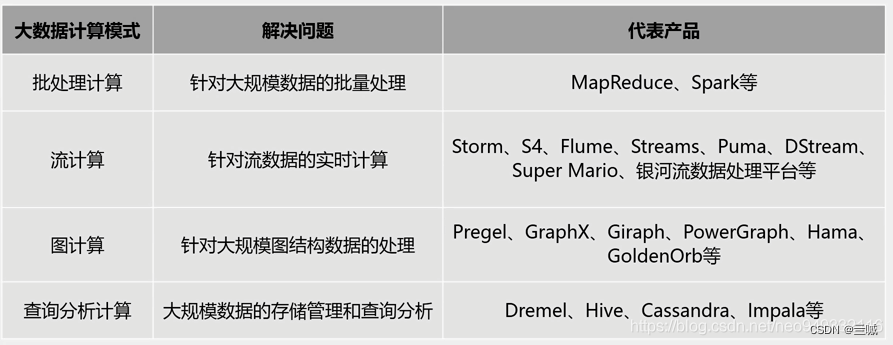
. 大数据计算模式:
. 大数据产业链环节包括以下几个方面:
. 大数据与云计算、物联网的关系: 大数据、云计算、物联网是当前信息技术发展的三大趋势,之间存在紧密的关系和互相促进作用。
. Hadoop运行模式有3种: 本地模式、伪分布、全分布
. Doug Cutting是Hadoop的作者之一
. start-dfs.sh 是启动Hadoop分布式文件系统(HDFS)的命令,该命令会启动HDFS的各个组件,包括NameNode、DataNode、SecondaryNameNode等。
. Hadoop具有以下几个特性:
. Hadoop的核心组件:
. 5个常用的Hadoop生态系统组件:
. Hadoop安装步骤:
. HDFS中的Block默认保存3份
. HDFS 中负责存储数据的进程是 DataNode NameNode 是 HDFS 的管理节点,负责管理文件系统的命名空间和客户端对文件的访问。 SecondaryNameNode 是 NameNode 的备份节点,定期合并和压缩 NameNode 的编辑日志文件,以减少NameNode 的内存占用。 JobTracker 是 MapReduce 的管理节点,负责调度和监控 MapReduce 任务的执行。
. 在CentOS中,可以使用jps命令来查看当前Java进程 使用ps命令结合grep命令来查看Java进程,命令为:ps -ef | grep java。 hostname命令用于查看主机名 source命令用于执行脚本文件。
. HDFS有两类节点:
. HDFS的主要特点包括:
. HDFS的数据管理策略:
. MapReduce 程序并不只能用Java编写。 Map/Reduce 打包运行的命令:hadoop jar <MapReduce程序的jar包路径> <主类名> [参数列表]
. Map/Reduce 主要思想: 分而治之是 MapReduce 的核心思想。
. MapReduce 的主要优点包括:
. WordCount 程序的 MapReduce 执行流程如下:
. YARN(Yet Another Resource Negotiator)是 Hadoop 2.x 中的一个重要组件,它是一种资源管理器和任务调度器,用于管理 Hadoop 集群中的资源和应用程序。YARN 的主要作用是将计算资源(CPU、内存等)与数据存储(HDFS)分离,实现更加灵活和高效的资源管理和任务调度。 YARN 的主要作用包括:
. YARN 相关的 Java 进程有两个:
. YARN 相关的配置文件主要包括: 这些配置文件通常位于 Hadoop 的安装目录下的 /etc/hadoop 目录中,用户可以根据实际需求进行修改和调整。在修改配置文件后,需要重新启动 YARN 集群,使配置生效。
. Hive 优点:
. Hive 与传统关系数据库的对比:
. Hive 的运行机制:
. Hive 内部表与外部表的区别:
. HBase 底层数据存储依赖于 Hadoop 分布式文件系统(HDFS),数据计算依赖于 Hadoop 计算引擎,如MapReduce 和 Spark。服务协调依赖于 ZooKeeper 协调服务。
. HBase 特点:
. HBase 和关系数据库的比较:
. 比较 HBase 和 Hive 异同: 相同:HBase 与 Hive 都是架构在 hadoop 之上的,都是用 HDFS 作为底层存储。 不同:
. NoSQL数据库的兴起是多种因素综合作用的结果,包括数据量和并发量的增加,非结构化数据的需求,云计算和大数据技术的发展以及系统架构的变化等。
. NoSQL 数据库和关系型数据库的不同:
. NoSQL 数据库类型及代表作品:
. Sqoop 的主要功能: Sqoop 是一个用于在 Apache Hadoop 和关系型数据库之间进行数据传输的工具,主要用于将关系型数据库中的数据导入到 Hadoop 中进行处理,或者将 Hadoop 中的数据导出到关系型数据库中进行分析和查询。
. 任务调度系统的主要作用如下: 任务调度系统是一种用于管理和调度计算机系统中各种任务的软件系统。它可以帮助用户在一定的时间范围内自动地执行预定的任务,并且可以对任务的执行情况进行监控和管理。
. 数据可视化是将数据以图表、地图、仪表盘等形式呈现出来的过程,主要意义:
. 可视化工具:
. Spark 是一个基于内存的分布式计算框架,主要特点:
. Spark是一个分布式计算框架,核心组件:
. 常见的流计算框架包括:
. 数据采集方法可以根据数据来源、数据类型和采集方式等不同角度进行分类,以下是常见的数据采集方法:
. Flume简介: Apache Flume 是一个可靠、可用、分布式、高可扩展的海量日志采集、聚合和传输系统,适用于大规模数据采集场景。Flume 的核心思想是将数据从源头采集到目的地,具有高效、可靠、可扩展、灵活等特点,可以支持各种类型的数据源和数据目的地。 Flume 的核心组件包括:
. Kafka 简介: Apache Kafka 是一种高吞吐量、低延迟、分布式的消息队列系统,适用于大规模数据处理和分布式系统中的数据流转场景。Kafka 最初是由 LinkedIn 公司开发的,目前已经成为 Apache 软件基金会的顶级项目之一。 Kafka 的特性包括:
. Kettle 简介: Kettle(也称为Pentaho Data Integration)是一款开源的 ETL 工具,提供了一套可视化的图形界面,可以方便地进行数据抽取、转换和加载等操作。Kettle 可以连接各种类型的数据源,包括关系型数据库、非关系型数据库、文件等,并支持多种数据格式的处理,如 CSV、XML、JSON 等。 Kettle 的主要功能: