最近开发的爬虫调度系统是由Flask框架提供接口,在Flask中启动Scrapy项目,开发期间遇到了几个问题,网上找找,自己也琢磨了好久,终于顺利解决。问题如下:
一、Scrapy、crawl指令找不到
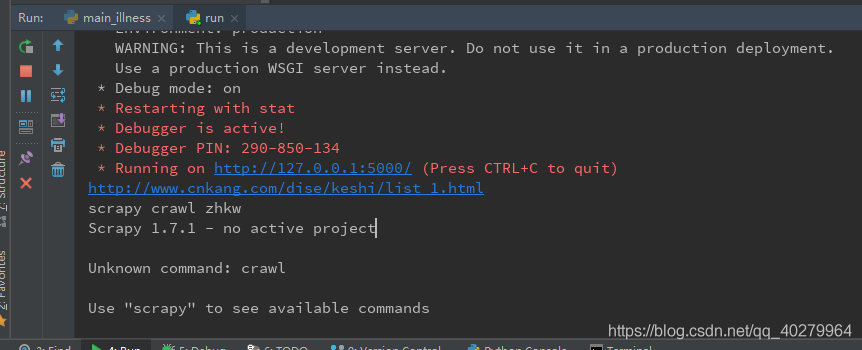
问题描述:
先看一下我的项目结构,如下:
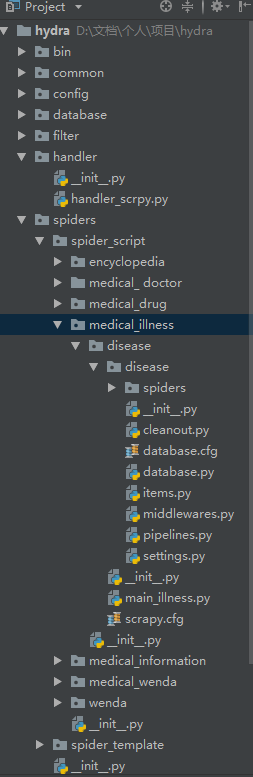
hydra是Flask项目目录,medical_illness下是Scrapy项目,handler_scrpy是接口文件。
现在要做的就是接口文件收到指令,然后启动scrapy项目,在scrapy项目下的main_illess.py文件是启动spider的,我在接口文件引入了这个文件,然后去运行它,就会报如上错误
Scrapy 1.7.1 - no active project
Unknown command: crawl Use "scrapy" to see
解决思路:
这是因为,在handler_scrpy中启动main_illess.py时当前工作目录是在Flask项目下:
D:\文档\个人\项目\hydra
并不在scrapy项目目录下,所以报了如上错误。在main_illess.py中做如下修改:
import os
from scrapy import cmdline
from filter.filter_change_path import set_new_path
from .disease import spiders
def start_crawl(spider_name):
b = 'scrapy crawl '
c = b + spider_name
# 获取spiders文件所在的目录,并将工作目录切换到spider所在目录下
set_new_path(os.path.dirname(spiders.__file__))
cmdline.execute(c.split())
切换后的工作空间:
D:\文档\个人\项目\hydra\spiders\spider_script\medical_illness\disease\disease\spiders
重点是注释部分,获得导入的spidres所在目录(即scrapy所在目录),然后见工作空间切换到scrapy目录,然后最后一句执行爬虫,启动完爬虫以后需要将工作目录再切换回去(为什么要用到进程,在第二个问题中会讲到):
# 启动scrapy项目文件
def start_crawler_threads(topic_name, rules, start_url):
# 通过start_url得到spider名字
spider_name = get_spider(start_url)
# 获得当前工作目录(根目录)
old_path = os.getcwd()
# 在进程中启动爬虫
crawl_threads = Process(target=main_illness.start_crawl, args=(spider_name ,))
crawl_threads.start()
# 启动完线程以后交给工作目录还原
set_old_path(old_path)
set_old_path()、set_new_path()方法所在文件定义如下:
import os
"""
更改与还原工作目录
"""
def set_new_path(path):
os.chdir(path)
def set_old_path(path):
os.chdir(path)
到此就解决找不到scrapy和crawl的问题了。
二、ValueError: signal only works in main thread
ERROR:tornado.application:Exception in callback (<zmq.sugar.socket.Socket object at 0x7f44c4d698d0>, <function wrap.<locals>.null_wrapper at 0x7f44c4d02378>)
Traceback (most recent call last):
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/tornado/ioloop.py", line 888, in start
handler_func(fd_obj, events)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/tornado/stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 450, in _handle_events
self._handle_recv()
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 480, in _handle_recv
self._run_callback(callback, msg)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 432, in _run_callback
callback(*args, **kwargs)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/tornado/stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 283, in dispatcher
return self.dispatch_shell(stream, msg)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 233, in dispatch_shell
self.pre_handler_hook()
File "/mnt/home2/zxm/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 248, in pre_handler_hook
self.saved_sigint_handler = signal(SIGINT, default_int_handler)
File "/mnt/home2/zxm/anaconda3/lib/python3.6/signal.py", line 47, in signal
handler = _signal.signal(_enum_to_int(signalnum), _enum_to_int(handler))
ValueError: signal only works in main thread
问题描述:
在我成功解决工作空间的问题之后这个问题就紧接着来了,导致以上错误的几个原因,我google了一下,网上也有反映这个错误的,但是按照他们的方法并不能解决我的问题,于是根据这个错误提示,大胆猜测——
解决思路:
“signal仅适用于主线程”,是不是因为在Flask中起动scrapy爬虫,请求flask的接口已经占用了主线程并且阻塞等待爬虫运行,所以再启动Scrapy时就会报ValueError: signal only works in main thread
根据这个思路,再启动Scrapy时,创建一个新的进程,让Scrapy在此进程中的主线程中运行,如下:
# 启动scrapy项目文件
def start_crawler_threads(topic_name, rules, start_url):
# 通过start_url得到spider名字
spider_name = get_spider(start_url)
# 获得当前工作目录(根目录)
old_path = os.getcwd()
# 在进程中启动爬虫
crawl_threads = Process(target=main_illness.start_crawl, args=(spider_name ,))
crawl_threads.start()
# 启动完线程以后交给工作目录还原
set_old_path(old_path)
使用进程后,问题解决
三、subprocess.CalledProcessError: Command '['scrapy', 'crawl', 'zhkw', '-o', 'output.json']' returned non-zero exit status 2.
问题描述:
这个问题是在出现问题二之后,我采用的一个解决方法时报的错,使用subprocess子进程启动爬虫,尝试解决ValueError: signal only works in main thread
问题分析:
用subprocess来启动scrapy思路是可行的,只不过在这里并没有执行成功,是因为这是在更改工作空间之前,所以会报错。但是使用此方法会有一个缺陷,虽然再子进程中启动了scrapy但是爬虫依然在阻塞,接口就会一直处于阻塞状态,所以建议使用多进程解决。
具体关于阻塞在问题四中会详细介绍
四、接口调用爬虫就会阻塞
问题描述:
由于本项目是由Flask提供接口来启动爬虫,但是爬虫往往都是运行时间很长,接口肯定是不能一直在等待爬虫运行完才结束
解决思路:
我们都知道进程和线程都是异步执行的,最开始我的解决办法就是使用多线程来启动每个爬虫,然后启动线程之后直接返回,爬虫在线程中继续运行。但是后来遇到了问题二,所以就结合问题二使用多进程来启动爬虫。
以上就是对Flask结合Scrapy中遇到的问题的解决,大家看了还有不清楚的地方,可以私信或者评论,我都会尽力解答。
另外,由于本人技术有限,此博客有何不对的地方欢迎大家指正,谢谢。