这个我会!先上图
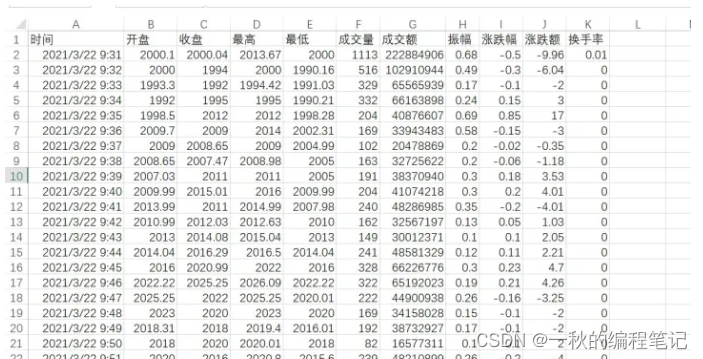
这篇回答中,我将向你展示两种不同的代码版本(加强版和一般版)
代码运行环境说明(非常重要)
Python版本要求
Python 3
需要安装的库
efinance
库的安装方法是:打开 cmd(命令提示符或者其他终端工具),输入以下代码
pip install efinance
输入完毕,按 Enter 键执行代码,等待 successfully 出现即可
代码展示
加强版代码
这一部分基于我开发的 python 库 efinance
根据股票代码获取最新第一个交易日的分钟数据
# 导入 efinance 如果没有安装则需要通过执行命令: pip install efinance 来安装
import efinance as ef
# 股票代码
stock_code = '600519'
# 数据间隔时间为 1 分钟
freq = 1
# 获取最新一个交易日的分钟级别股票行情数据
df = ef.stock.get_quote_history(stock_code, klt=freq)
# 将数据存储到 csv 文件中
df.to_csv(f'{stock_code}.csv', encoding='utf-8-sig', index=None)
print(f'股票: {stock_code} 的行情数据已存储到文件: {stock_code}.csv 中!')
根据股票名称获取最新第一个交易日的分钟数据(支持A股、美股、港股)
# 导入 efinance 如果没有安装则需要通过执行命令: pip install efinance 来安装
import efinance as ef
# 股票名称
stock_code = '微软'
# 数据间隔时间为 1 分钟
freq = 1
# 获取最新一个交易日的分钟级别股票行情数据
df = ef.stock.get_quote_history(stock_code, klt=freq)
# 将数据存储到 csv 文件中
df.to_csv(f'{stock_code}.csv', encoding='utf-8-sig', index=None)
print(f'股票: {stock_code} 的行情数据已存储到文件: {stock_code}.csv 中!')
每间隔 1 分钟获取一次单只股票分钟行情数据
# 导入 efinance 如果没有安装则需要通过执行命令: pip install efinance 来安装
import efinance as ef
import time
from datetime import datetime
# 股票代码
stock_code = '600519'
# 数据间隔时间为 1 分钟
freq = 1
status = {stock_code: 0}
while 1:
# 获取最新一个交易日的分钟级别股票行情数据
df = ef.stock.get_quote_history(
stock_code, klt=freq)
# 现在的时间
now = str(datetime.today()).split('.')[0]
# 将数据存储到 csv 文件中
df.to_csv(f'{stock_code}.csv', encoding='utf-8-sig', index=None)
print(f'已在 {now}, 将股票: {stock_code} 的行情数据存储到文件: {stock_code}.csv 中!')
if len(df) == status[stock_code]:
print(f'{stock_code} 已收盘')
break
status[stock_code] = len(df)
print('暂停 60 秒')
time.sleep(60)
print('-'*10)
print('全部股票已收盘')
每间隔 1 分钟获取一次多只股票分钟行情数据# 导入 efinance 如果没有安装则需要通过执行命令: pip
install efinance 来安装
import efinance as ef
import time
from datetime import datetime
# 股票代码或者名称列表
stock_codes = ['600519', '腾讯', 'AAPL']
# 数据间隔时间为 1 分钟
freq = 1
status = {stock_code: 0 for stock_code in stock_codes}
while len(stock_codes) != 0:
for stock_code in stock_codes.copy():
# 现在的时间
now = str(datetime.today()).split('.')[0]
# 获取最新一个交易日的分钟级别股票行情数据
df = ef.stock.get_quote_history(stock_code, klt=freq)
# 将数据存储到 csv 文件中
df.to_csv(f'{stock_code}.csv', encoding='utf-8-sig', index=None)
print(f'已在 {now}, 将股票: {stock_code} 的行情数据存储到文件: {stock_code}.csv 中!')
if len(df) == status[stock_code]:
# 移除已经收盘的股票代码
stock_codes.remove(stock_code)
print(f'股票 {stock_code} 已收盘!')
status[stock_code] = len(df)
if len(stock_codes) != 0:
print('暂停 60 秒')
time.sleep(60)
print('-'*10)
print('全部股票已收盘')
每间隔 1 分钟获取一次多只股票分钟行情数据(高速版)# 导入 efinance 如果没有安装则需要通过执行
命令: pip install efinance 来安装
from typing import Dict
import efinance as ef
import pandas as pd
import time
from datetime import datetime
# 股票代码或者名称列表
stock_codes = ['600519', '腾讯', 'AAPL']
# 数据间隔时间为 1 分钟
freq = 1
status = {stock_code: 0 for stock_code in stock_codes}
while len(stock_codes) != 0:
# 获取最新一个交易日的分钟级别股票行情数据
stocks_df: Dict[str, pd.DataFrame] = ef.stock.get_quote_history(
stock_codes, klt=freq)
for stock_code, df in stocks_df.items():
# 现在的时间
now = str(datetime.today()).split('.')[0]
# 将数据存储到 csv 文件中
df.to_csv(f'{stock_code}.csv', encoding='utf-8-sig', index=None)
print(f'已在 {now}, 将股票: {stock_code} 的行情数据存储到文件: {stock_code}.csv 中!')
if len(df) == status[stock_code]:
# 移除已经收盘的股票代码
stock_codes.remove(stock_code)
print(f'股票 {stock_code} 已收盘!')
status[stock_code] = len(df)
if len(stock_codes) != 0:
print('暂停 60 秒')
time.sleep(60)
print('-'*10)
print('全部股票已收盘')
以上演示了如何使用我开发的 python 库来获取最新一个交易日内股票的分钟级股票数据
下面是更加底层的版本(功能比较少,仅支持 A 股)
一般版
获取当日分钟线数据
from urllib.parse import urlencode
import pandas as pd
import requests
def gen_eastmoney_code(rawcode: str) -> str:
'''
生成东方财富专用的secid
Parameters
----------
rawcode : 6 位股票代码
Parameters
----------
str : 按东方财富格式生成的字符串
'''
if rawcode[0] != '6':
return f'0.{rawcode}'
return f'1.{rawcode}'
def get_k_history(code: str, beg: str = '16000101', end: str = '20500101', klt: int = 1, fqt: int = 1) -> pd.DataFrame:
'''
功能获取k线数据
Parameters
----------
code : 6 位股票代码
beg: 开始日期 例如 20200101
end: 结束日期 例如 20200201
klt: k线间距 默认为 101 即日k
klt:1 1 分钟
klt:5 5 分钟
klt:101 日
klt:102 周
fqt: 复权方式
不复权 : 0
前复权 : 1
后复权 : 2
Return
------
DateFrame : 包含股票k线数据
'''
EastmoneyKlines = {
'f51': '时间',
'f52': '开盘',
'f53': '收盘',
'f54': '最高',
'f55': '最低',
'f56': '成交量',
'f57': '成交额',
'f58': '振幅',
'f59': '涨跌幅',
'f60': '涨跌额',
'f61': '换手率',
}
EastmoneyHeaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
}
fields = list(EastmoneyKlines.keys())
columns = list(EastmoneyKlines.values())
fields2 = ",".join(fields)
secid = gen_eastmoney_code(code)
params = (
('fields1', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13'),
('fields2', fields2),
('beg', beg),
('end', end),
('rtntype', '6'),
('secid', secid),
('klt', f'{klt}'),
('fqt', f'{fqt}'),
)
base_url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get'
url = base_url+'?'+urlencode(params)
json_response = requests.get(
url, headers=EastmoneyHeaders).json()
data = json_response['data']
# code = data['code']
# 股票名称
# name = data['name']
klines = data['klines']
rows = []
for _kline in klines:
kline = _kline.split(',')
rows.append(kline)
df = pd.DataFrame(rows, columns=columns)
return df
if __name__ == "__main__":
# 股票代码
code = '600519'
# 根据股票代码、开始日期、结束日期获取指定股票代码指定日期区间的k线数据
df = get_k_history(code)
# 保存k线数据到表格里面
df.to_csv(f'{code}.csv', encoding='utf-8-sig', index=None)
print(f'股票代码:{code} 的 k线数据已保存到代码目录下的 {code}.csv 文件中')
获取当日分钟线数据(每分钟运行一次,直到收盘)from urllib.parse import urlencode
import pandas as pd
import requests
import time
def gen_eastmoney_code(rawcode: str) -> str:
'''
生成东方财富专用的secid
Parameters
----------
rawcode : 6 位股票代码
Parameters
----------
str : 按东方财富格式生成的字符串
'''
if rawcode[0] != '6':
return f'0.{rawcode}'
return f'1.{rawcode}'
def get_k_history(code: str, beg: str = '16000101', end: str = '20500101', klt: int = 1, fqt: int = 1) -> pd.DataFrame:
'''
功能获取k线数据
Parameters
----------
code : 6 位股票代码
beg: 开始日期 例如 20200101
end: 结束日期 例如 20200201
klt: k线间距 默认为 101 即日k
klt:1 1 分钟
klt:5 5 分钟
klt:101 日
klt:102 周
fqt: 复权方式
不复权 : 0
前复权 : 1
后复权 : 2
Return
------
DateFrame : 包含股票k线数据
'''
EastmoneyKlines = {
'f51': '时间',
'f52': '开盘',
'f53': '收盘',
'f54': '最高',
'f55': '最低',
'f56': '成交量',
'f57': '成交额',
'f58': '振幅',
'f59': '涨跌幅',
'f60': '涨跌额',
'f61': '换手率',
}
EastmoneyHeaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
}
fields = list(EastmoneyKlines.keys())
columns = list(EastmoneyKlines.values())
fields2 = ",".join(fields)
secid = gen_eastmoney_code(code)
params = (
('fields1', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13'),
('fields2', fields2),
('beg', beg),
('end', end),
('rtntype', '6'),
('secid', secid),
('klt', f'{klt}'),
('fqt', f'{fqt}'),
)
base_url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get'
url = base_url+'?'+urlencode(params)
json_response = requests.get(
url, headers=EastmoneyHeaders).json()
data = json_response['data']
# code = data['code']
# 股票名称
# name = data['name']
klines = data['klines']
rows = []
for _kline in klines:
kline = _kline.split(',')
rows.append(kline)
df = pd.DataFrame(rows, columns=columns)
return df
if __name__ == "__main__":
# 重复 1000 次
for _ in range(1000):
# 股票代码
code = '600519'
# 根据股票代码、开始日期、结束日期获取指定股票代码指定日期区间的k线数据
df = get_k_history(code)
# 保存k线数据到表格里面
df.to_csv(f'{code}.csv', encoding='utf-8-sig', index=None)
print(f'股票代码:{code} 的 k线数据已保存到代码目录下的 {code}.csv 文件中')
time.sleep(60)
# 240 行说明收盘了,结束
if len(df) >= 240:
break
零基础Python学习资源及经验总结
如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,我也为大家整理了一份【最新全套Python学习资料】一定对你有用!
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的!
1、学习时间相对较短,学习内容更全面更集中
2、可以找到适合自己的学习方案
这份资料包含:Python安装包+激活码、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等教程,带你从零开始系统性的学好Python!
点击免费领取《CSDN大礼包》:
最新全套【Python入门到进阶资料 & 实战源码 & 安装工具】 https://mp.weixin.qq.com/s/9IuSexhanYZ1TMAF1MZIhw
https://mp.weixin.qq.com/s/9IuSexhanYZ1TMAF1MZIhw
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python课程视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。
五、Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、互联网企业面试真题
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传至CSDN官方,朋友们如果需要可以点击下方链接费获取【保证100%免费】
点击免费领取《CSDN大礼包》:
最新全套【Python入门到进阶资料 & 实战源码 & 安装工具】https://mp.weixin.qq.com/s/9IuSexhanYZ1TMAF1MZIhw
以上全套资料已经为大家打包准备好了,希望对正在学习Python的你有所帮助!
如果你觉得这篇文章有帮助,可以点个赞呀~
我会坚持每天更新Python相关干货,分享自己的学习经验帮助想学习Python的朋友们少走弯路!