一个人要是长时间一直做一件事,思维容易固化。
就像那些从太空回来的宇航员,吃饭时容易丢开拿在手里的勺子。当勺子掉在地上时,哦,我已经回到地球了^_^。
所以,适当尝试新鲜事物,既是对大脑的放松,也是开阔思路的好机会,好方法。
那这次,博主尝试的新事物是什么呢?我们知道,大、物、移、智、云是近些年比较火的技术,具体来讲就是大数据、物联网、移动5G、人工智能、云计算。每一个都显得高大上。
所以,博主决定在其中选择一个来学习学习。其实,这些技术并不是割裂的,而是有内在的本质联系的,具体可参考博主的另一篇博文
一文将大数据、云计算、物联网、5G(移动网)、人工智能等最新技术串起来_wwwyuewww的专栏-CSDN博客
那么,选择哪一个方向来尝试一下呢?
这不,一年一度的诗词大会又开始了。

现在人工智能技术非常火,很多人就想着,要是让AI来写诗,会是什么样的。还有人真的做了这件事。
这里,博主就不尝试那么复杂的了,能力和时间都不允许。我们来个简单的,选择大数据方向,来分析分析唐诗三百首里,各个汉字出现的频率。
需要补充说明一下,就唐诗三百首而言,说实话,还不至于用大数据技术,简单写个程序就可以搞定。但是,如果有更多的数据,那么使用大数据技术,还是可以提升效率的。
好了,闲话少说,我们简单看看怎么做。我们使用Hadoop完成数据分析。
整个过程分为三个部分
第一部分 先作为分布式文件系统来使用
1 下载安装Hadoop。这里,我用了老版本2.8
因为Hadoop依赖Java,需要准备Java环境,导出Java环境变量
解压Hadoop安装包,然后在/etc/profile文件中导出Hadoop环境变量
同时,在Hadoop env中也导出Java环境变量
2 按照官方示例,格式化分布式文件系统,启动HDFS
Hadoop namenode -format
hdfs namenode -format
上述两个命令都可以,不过后续都推荐第二个命令
关停之前的服务
stop dfs 和yarn
重启服务
start dfs 和 yarn
使用jps命令查看java进程
23232 Jps
20977 ResourceManager
20373 NameNode
20806 SecondaryNameNode
21147 NodeManager
20571 DataNode
为啥要查看java进程呢,因为一个基本的Hadoop集群中的节点主要有:
NameNode:负责协调集群中的数据存储
DataNode:存储被拆分的数据块
JobTracker:协调数据计算任务
TaskTracker:负责执行由JobTracker指派的任务
SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
要确定上述关键节点进程成功运行,否则,不利于后续错误的排除判断:倒地是程序问题还是环境问题。所以,最好检查一下。
实际中,发现缺少DataNode,将java JDK版本从10切换到8
删除/root/hadoop目录下的日志和临时文件(目录由配置文件中指定),重新启动服务,问题解决
但也有说《重新格式化名称节点之前需要清空DFS下的名称和数据文件夹以解决数据节点无法启动的问题。》可能不是JDK版本的问题
相对之前输出,也没有an illegal错误提示了,这个应该是java版本的原因
但是还是仍然有如下错误
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
其实把native目录下的库拷贝到上一层lib目录下,即可通过检测
但是会提示snappy库没有,这个需要下载源代码,编译安装
3 用命令方式,测试HDFS文件系统
查看目录
Hadoop fs -ls /
创建一个新的目录,创建后可以在web界面查看当前操作的结果。web界面的端口为50070
hdfs dfs -mkdir /user
对于文件系统操作命令,可以用Hadoop fs 和hdfs dfs两个命令,根据网上资料,第一个命令可以操作更多格式的文件系统,不止hdfs文件系统
命令的基本使用可以这样理解,将Hadoop fs看做一个整体,带选项,比如 -ls -mkdir等,然后指定操作目录即可。
注意,这里的目录是针对的hdfs分布式文件系统,不是电脑本地目录
本地和hdfs文件系统中文件相互拷贝命令选项如下:
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
第二部分,作为数据分析平台使用
4 执行一个MapReduce任务
创建一个input 和output 文件目录
将Hadoop配置文件拷贝到input目录,作为分析的源文件
执行grep 任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar grep /user/input /user/output 'dfs[a-z.]+'
提示无法连接8032端口
修改yarn的配置文件,增加如下内容,
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
提示无法连接master:8032,意思貌似无法解析该地址
修改配置文件,将master替换为localhost
再次执行任务,提示
mapreduce.Job: Task Id : attempt_1578829933099_0001_m_000005_0, Status : FAILED
该问题同样在java版本退回到JDK8后未再出现,map-reduce任务通过。之前许多错误可能是java版本不兼容导致。
通过8088端口可以查看这类任务的执行情况及执行日志
第一次执行提示output目录已存在错误,修改为
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar grep /user/input /user/output/grepresult 'dfs[a-z.]+'
执行成功。将执行结果拷贝到本地
hdfs dfs -copyToLocal /user/output/ test/
查看本地中的执行结果,跟在本地单独执行命令检查,结果基本一致
root@ubuntu:/home/work/hadoop-2.8.5/test/output/grepresult# cat part-r-00000
1 dfs.replication
1 dfs.permissions
1 dfs.name.dir
1 dfs.data.dir
本地单独命令执行结果
root@ubuntu:/home/work/hadoop-2.8.5/etc/hadoop# cat hdfs-site.xml | grep dfs[a-z.]
<name>dfs.name.dir</name>
<name>dfs.data.dir</name>
<name>dfs.replication</name>
<name>dfs.permissions</name>
第三部分,通过Java编程,使用Hadoop提供的接口,执行MapReduce任务,完成古诗分析
5 编写MapReduce任务,分析古诗
现在可以编写程序,来进行分析统计了。程序很简单,读入古诗的每一个字符,然后统计它们出现的频率。
我们使用Windows环境的idea来编辑和编译Java库。
参考网上的例子,主要有三个文件,分别是WordCountDriver.java,WordCountMapper.java以及WordCountReducer.java。



第一个是框架文件,将后两个管理起来,第二是做Map操作,第三个是做Reduce操作。
具体统计操作写的很简陋,没有做过多的处理。
最后编译生成一个jar库HadoopApi.jar。
6 上传待分析古诗文件
我们将从网络下载的含有唐诗三百首的文本文件传到HDFS中。古诗格式如下图所示。

7 执行分析程序,进行分析
hadoop jar /home/share/com/HadoopApi.jar com.xxx.hadoop.Test.WordCountDriver
8 将分析结果从Hadoop的分布式文件系统中拷贝出来
分析结果是一个文本文件,打开可以看到如下图所示

如前所述,这里没有对结果排序。所以,对这个数据,还需要再处理一次。
我们将数据拷贝到Excel中,进行一下排序,结果就出来了,如下图所示:
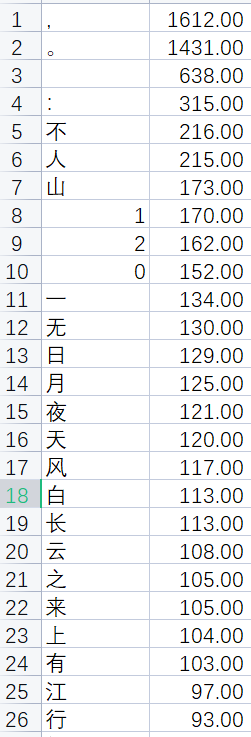
可以看到,最高频字是“不”,其次是“人”,再次是“山”。有没有出乎你的意料?
如果我们统计所有的古诗,就可以得到古人写诗最喜欢用的字了。
后记:
不得不说,兴趣才是最好的老师。当你想要做感兴趣的事情时,主动学习就不是什么困难的事情了。