文章目录
- 1.概述
- 2.Metadata/Metastore的作用
- 3 Metastore三种配置方式
- 3.1 Hive配置参数说明
-
- 3.2 内嵌模式(Embedded)
- 3.2.1 hive-site.xml配置说明
- 3.2.2 hive-site.xml配置样例
- 3.2.3 启动方式
- 3.2.4 缺点
- 3.3 本地模式(Local)
- 3.3.1 hive-site.xml配置说明
- 3.3.2 hive-site.xml配置样例
- 3.3.3 启动方式
- 3.3.4 缺点
- 3.3.5 备注
- 3.4 远程模式(Remote)
- 3.4.1 服务端hive-site.xml配置说明
- 3.4.2 服务端hive-site.xml配置样例
- 3.4.3 客户端hive-site.xml配置说明
- 3.4.4 客户端hive-site.xml配置样例
- 3.4.5 启动方式
- 3.4.5.1 服务端启动方式
- 3.4.5.2 客户端启动方式
- 4 客户端
- 4.1 第一代客户端Hive Client
- 4.2 第二代客户端Hive Beeline Client
- 5 元数据表
- 5.1 TBLS(表的表头信息)表解释
- 5.2 DBS(表db信息)表解释
- 5.3 SDS(表存储格式相关内容)表解释
- 5.4 columns\_v2(表字段详情)表解释
- 5.5 table\_params(表附属信息)表解释
- 5.6 元数据接口详解
- 5.6.1 接口详解
-
- 6 HiveServer2
- 6.1 hive-site.xml配置说明
- 6.2 hive-site.xml配置样例
- 6.3 启动方式
- 6.4 测试
- 6.5 安全鉴权
- 7 Hive内置服务
- 7.1 hiveserver
- 7.2 hwi
- 7.3 cli
1.概述
Hive是最合适数据仓库应用程序的,其可以维护海量数据,而且可以对数据进行挖掘,然后形成意见和报告等。下图即是Hive与Hadoop交互的架构图:
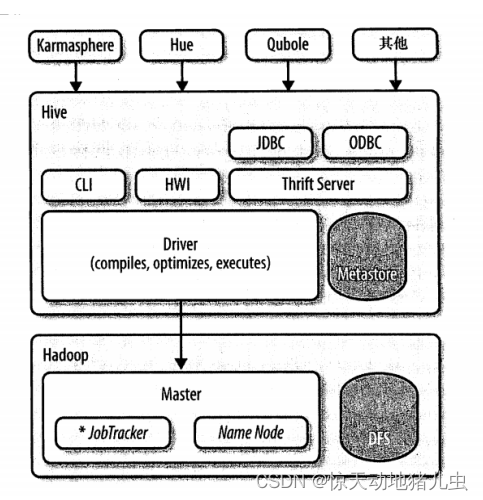
Hive的发行版本中附带的模块有CLI,HWI(Hive的简单网页见面)以及通过JDBC,ODBC和Thrift服务器进行编程访问的几个模块。
另外基于Hive的发行版本一些厂商有额外的封装,如Karmasphere发布的一个商业产品、Cloudera提供的开源的Hue项目、以及Qubole提供的"Hive即服务"方式等.
- Driver(驱动模块):所有的命令和查询都会进入到Driver,通过该模块对输入进行解析编译,对需求的计算进行优化,然后启动多个MapReduce任务(job)来执行。当启动MapReduce任务时,HIve本身不会生成Java代码。而是通过一个表示“job执行计划”的xml文件驱动内置的Mapper和Reducer模块。
- Metastore(元数据存储)是一个独立的关系型数据库(通常是一个MySQL实例),其中保存则Hive的表模式和其他系统元数据。
2.Metadata/Metastore的作用
Metadata即元数据,包含用Hive创建的database、tabel等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。
3 Metastore三种配置方式
由于元数据不断地修改、更新,所以Hive元数据不适合存储在HDFS中,一般存在RDBMS中。
3.1 Hive配置参数说明
3.1.1 基本配置参数
请参见配置Hive下的hivemetstore -site.xml文档。
| Configuration Parameter | Description |
|---|
| javax.jdo.option.ConnectionURL | 用于包含元数据的数据存储的JDBC连接字符串 |
| javax.jdo.option.ConnectionDriverName | 包含元数据的数据存储的JDBC驱动程序类名 |
| hive.metastore.uris | Hive连接到这些uri中的一个,向远端Metastore(以逗号分隔的uri列表)发送元数据请求。 |
| hive.metastore.local | 本地或远端metastore(从Hive 0.10移除:如果hive.metastore.uri为空,则假设本地模式为远端模式) |
| hive.metastore.warehouse.dir | 本机表的默认位置的URI |
Hive metastore是无状态的,因此可以有多个实例来实现高可用性。使用hive.metastore.uri可以指定多个远程元数据连接。Hive会默认使用列表中的第一个,但会在连接失败时随机选择一个,并尝试重新连接。
3.1.2 其他配置参数
以下metastore配置参数是从旧文档中继承下来的,没有保证它们仍然存在。Hive当前的配置选项请参见HiveConf Java类,Metastore和Hive Metastore安全部分的语言手册的Hive配置属性的用户友好的描述Metastore参数。
| Configuration Parameter | Description | Default Value |
|---|
| hive.metastore.metadb.dir | 文件存储元数据基目录的位置。(在0.4.0中HIVE-143删除了该功能。) | |
| hive.metastore.rawstore.impl | 实现org.apache.hadoop.hive.metastore.rawstore接口的类名。该类用于存储和检索原始元数据对象,如表、数据库。(Hive 0.8.1及以上版本) | |
| org.jpox.autoCreateSchema | 如果模式不存在,则在启动时创建必要的模式。(模式包括表、列等等。)创建一次后设置为false。 | |
| org.jpox.fixedDatastore | 数据存储模式是否固定。 | |
| datanucleus.autoStartMechanism | 是否在启动时初始化。 | |
| ive.metastore.ds.connection.url.hook | 用于检索JDO连接URL的钩子的名称。如果为空,则使用javax.jdo.option.ConnectionURL中的值作为连接URL。(Hive 0.6及以上版本) | |
| hive.metastore.ds.retry.attempts | 如果出现连接错误,重试调用备份数据存储的次数。 | 1 |
| hive.metastore.ds.retry.interval | 数据存储重试之间的毫秒数。 | 1000 |
| hive.metastore.server.min.threads | Thrift服务器池中工作线程的最小数量。 | 200 |
| hive.metastore.server.max.threads | Thrift服务器池中的最大工作线程数。 | 100000 since Hive 0.8.1 |
| hive.metastore.filter.hook | Metastore钩子类,用于在客户端进一步过滤元数据读取结果。 | (Hive 1.1.0及以上版本) |
| hive.metastore.port | Hive metastore监听端口。 | 9083 |
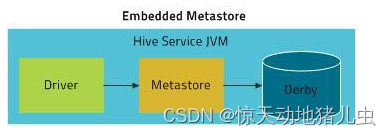
3.2 内嵌模式(Embedded)
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
3.2.1 hive-site.xml配置说明
| Config Param | Config Value | Comment |
|---|
| javax.jdo.option.ConnectionURL | jdbc:derby:;databaseName= ../build/test/junit_metastore_db;create=true | Derby数据库位于hive/trunk/build… |
| javax.jdo.option.ConnectionDriverName | org.apache.derby.jdbc.EmbeddedDriver | Derby自带了JDBC驱动类 |
| hive.metastore.warehouse.dir | file://${user.dir}/../build/ql/test/data/warehouse | 单元测试数据放在本地文件系统中 |
3.2.2 hive-site.xml配置样例
<property>
<name>hive.metastore.uris</name>
<value/>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
3.2.3 启动方式
解压hive安装包,执行bin/hive启动即可使用
3.2.4 缺点
不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。
3.3 本地模式(Local)
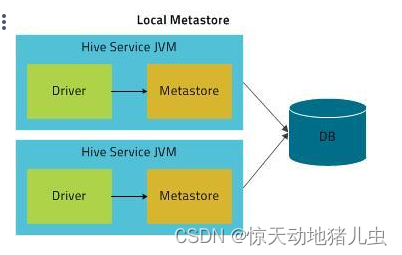
如果要支持多会话(以及多租户),需要使用一个独立的数据库,这种配置方式成为本地配置。本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.在这里我们使用MySQL。
本地模式同内嵌模式一样,不需要单独起Metastore服务,用的是跟hive在同一个进程里的Metastore服务。也就是说当你启动一个hive 服务,里面默认会帮我们启动一个Metastore服务。但是不一样的是,Metastore连接的确实另一个进程中运行的数据库,在同一台机器上或者远程机器上。
3.3.1 hive-site.xml配置说明
| Config Param | Config Value | Comment |
|---|
| javax.jdo.option.ConnectionURL | jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=true | 元数据存储在MySQL服务器中 |
| javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver | MySQL JDBC 驱动类 |
| javax.jdo.option.ConnectionUserName | <user name> | 连接MySQL服务的用户名 |
| javax.jdo.option.ConnectionPassword | <password> | 连接MySQL服务的密码 |
| hive.metastore.uris | not needed because this is local store | |
| hive.metastore.local | true | 这是本地存储(在Hive 0.10中移除,参见配置描述部分) |
| hive.metastore.warehouse.dir | <base hdfs path> | 指向HDFS中非外部Hive表的默认位置。 |
3.3.2 hive-site.xml配置样例
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExit=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value></value>
<description>指向的是运行metastore服务的主机,这是hive客户端配置,metastore服务不需要配置</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>hive表的默认存储路径,为HDFS的路径location of default database for the warehouse</description>
</property>
3.3.3 启动方式
解压hive安装包,执行bin/hive启动即可使用
3.3.4 缺点
每启动一次hive服务,都内置启动了一个metastore。
3.3.5 备注
如果选择 MySQL 作为 MetaStore 存储数据库,需要提前将MySQL的驱动包拷贝到 $HIVE_HOME/lib目录下。
JDBC 连接驱动类视情况决定选择com.mysql.cj.jdbc.Driver 还是 com.mysql.jdbc.Driver。
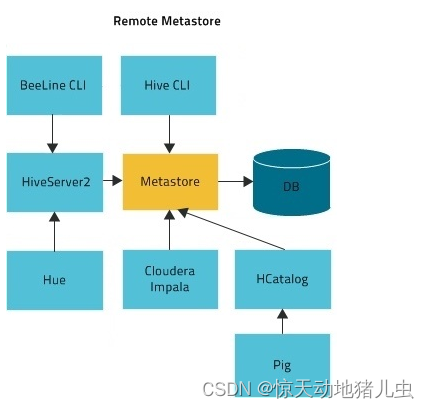
3.4 远程模式(Remote)
远程模式下,需要单独起Metastore服务,然后每个客户端都在配置文件里配置连接到该Metastore服务。MetaStore服务和Hive服务运行在不同进程中。CLI、HiveServer2、HCatalog、Impala 以及其他进程使用 Thrift API(使用 hive.metastore.uris 属性配置)与 MetaStore 服务通信。MetaStore 服务通过 JDBC 与 MetaStore 数据库进行通信(使用 javax.jdo.option.ConnectionURL 属性配置):
3.4.1 服务端hive-site.xml配置说明
| Config Param | Config Value | Comment |
|---|
| javax.jdo.option.ConnectionURL | jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=true | metadata is stored in a MySQL server |
| javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver | MySQL JDBC driver class |
| javax.jdo.option.ConnectionUserName | <user name> | user name for connecting to MySQL server |
| javax.jdo.option.ConnectionPassword | <password> | password for connecting to MySQL server |
| hive.metastore.warehouse.dir | <base hdfs path> | 默认hive表路径 |
| hive.metastore.thrift.bind.host | <host_name> | Host name to bind the metastore service to. When empty, “localhost” is used. This configuration is available Hive 4.0.0 onwards. |
从Hive 3.0.0 (Hive -16452)开始,metastore数据库存储了一个GUID,可以通过Thrift API get_metastore_db_uuid被metastore客户端查询,以识别后端数据库实例。HiveMetaStoreClient可以通过getMetastoreDbUuid()方法访问这个API。
3.4.2 服务端hive-site.xml配置样例
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_meta?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.port</name>
<value>9083</value>
</property>
3.4.3 客户端hive-site.xml配置说明
| Config Param | Config Value | Comment |
|---|
| hive.metastore.uris | thrift://<host_name>:<port> | Thrift metastore服务器的主机和端口。如果指定了hive.metastore.thrift.bind.host, host应该与该配置相同。在动态服务发现配置参数中了解更多信息。如果有多个metastore服务器,将URL之间用逗号分隔,metastore服务器URL的格式为thrift://127.0.0.1:9083。 |
| hive.metastore.local | false | Metastore是远程的。注意:从Hive 0.10开始不再需要。设置hive.metastore.uri就足够了。 |
| hive.metastore.warehouse.dir | <base hdfs path> | 指向HDFS中非外部Hive表的默认位置。 |
3.4.4 客户端hive-site.xml配置样例
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083,thrift://127.0.0.1:9084</value>
<description>指向的是运行metastore服务的主机</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
3.4.5 启动方式
远程模式的示意图如下:
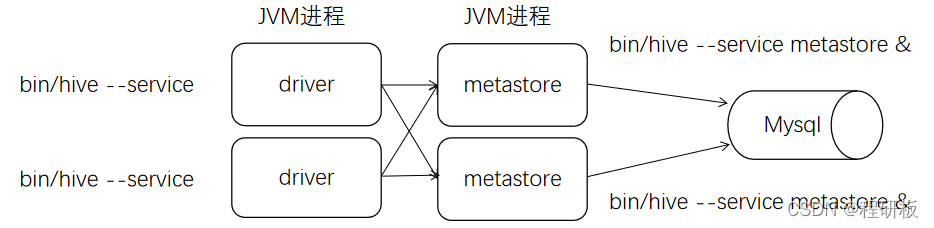
3.4.5.1 服务端启动方式
服务器端启动一个MetaStoreServer
hive --service metastore -p <port_num>
nohup hive --service metastore >/dev/null 2>&1 &
3.4.5.2 客户端启动方式
客户端利用Thrift协议通过MetaStoreServer访问元数据库。
hive
hive --service
4 客户端
一般的情况下,都采用远程模式部署Hive的Metastore服务。使用Hive自带的客户端进行连接访问。接下来,我们重点讲解下客户端。
4.1 第一代客户端Hive Client
在hive安装包的bin目录下,有hive提供的第一代客户端 bin/hive。使用该客户端可以访问hive的metastore服务。从而达到操作hive的目的。即在3.4节中介绍的客户端。
4.2 第二代客户端Hive Beeline Client
hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务。
在hive运行的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
nohup hive --service metastore &
nohup hive --service hiveserver2 &
在所要访问Hive的客户机上使用beeline客户端进行连接访问。
beeline
5 元数据表
| 表名 | 说明 | 天联健 |
|---|
| DBS | 元数据库信息。存放DB的HDFS路径信息 | DB_ID |
| TBLS | 所有hive表的基本信息 | TBL_ID ,SD_ID, DB_ID |
| TALE PARAM | 表级属性,如是否外部表,表注释等 | TBL_ID |
| COLUMNS_V2 | Hive表字段信息(字段注释,字段名,字段类型,字段序号) | CD_ID |
| SDS | 所有hive表、表分区所对应的hdfs数据目录和数据格式 | SD_ID,SERDE_ID |
| SERDES | Hive表的序列化类型 | SERDE ID |
| SERDE_PARAM | 序列化反序列化信息,如行分隔符、列分隔符、NULL 的表示字符等 | SERDE_ID |
| PARTITIONS | Hive表分区信息 | PART_ID,SD_ID,TEL_ID |
| PARTITION_KEYS | Hive分区表分区键 | TBL_ID |
| PARTITION_KEY_VALS | Hive表分区名(键值) | PRT_ID |
| SEQUENCE_TAELE | 保有Hive对象的下一个可用ID,包括数据库,表。字段, 分区等对象的下一个ID.默认ID每次+5 | SEQUENCE_NAME,NEXT_VAL |
5.1 TBLS(表的表头信息)表解释
| 英文名 | 类型 | 中文注释 |
|---|
| TBL_ID | bigint(20) | 全表唯一主键 |
| CREATE_TIME | int(11) | 表创建时间,格式是到秒的时间戳 |
| DB_ID | bigint(20) | DBS 表的id |
| LAST_ACCESS_TIME | int(11) | |
| OWNER | varchar(767) | 创建表的用户名 |
| OWNER_TYPE | varchar(10) | |
| RETENTION | int(11) | |
| SD_ID | bigint(20) | |
| TBL_NAME | varchar(256) | 表名 |
| TBL_TYPE | varchar(128) | 类型:EXTERNAL_TABLE 外部表;MANAGED_TABLE内部表;VIRTUAL_VIEW 试图 |
| VIEW_EXPANDED_TEXT | mediumtext | 如果是试图的话,试图的SQL语句 |
| VIEW_ORIGINAL_TEXT | mediumtext | |
| IS_REWRITE_ENABLED | bit(1) | |
5.2 DBS(表db信息)表解释
| 英文名 | 类型 | 中文注释 |
|---|
| DB_ID | bigint(20) | 唯一主键id |
| DESC | Varchar(4000) | |
| DB_LOCATION_URI | varchar(4000) | 表所属db的路径地址 |
| NAME | varchar(128) | 表所属db的名字 |
| OWNER_NAME | varchar (128) | 表所属账号名字 |
| OWNER_TYPE | varchar (10) | |
| CTLG_NAME | varchar(256) | |
5.3 SDS(表存储格式相关内容)表解释
| 英文名 | 类型 | 中文注释 |
|---|
| SD_ID | bigint(20) | 唯一主键id |
| CD_ID | bigint(20) | |
| INPUT_FORMAT | varchar(4000) | Input格式 |
| IS_COMPRESSED | bit(1) | |
| IS_STOREDASSUBDIRECTORIES | bit(1) | |
| location | varchar(4000) | 数据存储路径 |
| NUM_BUCKETS | Int(11) | |
| OUTPUT_FORMAT | varchar(4000) | Output格式 |
| SERDE_ID | bigint(20) | |
5.4 columns_v2(表字段详情)表解释
| 英文名 | 类型 | 中文注释 |
|---|
| CD_ID | bigint(20) | 跟sds表的cd_id关联 |
| COMMENT | varchar(4000) | 注释信息 |
| COLUMN_NAME | bit(1) | 列名 |
| TYPE_NAME | bit(1) | 列值类型 |
| INTEGER_IDX | varchar(4000) | 列在表中的顺序 |
5.5 table_params(表附属信息)表解释
| 英文名 | 类型 | 中文注释 |
|---|
| TBL_ID | bigint(20) | 跟tbls表的tbl_id关联 |
| PARAM_KEY | varchar(4000) | comment –> 表注释;EXTERNAL –> 是否是外部表;parquet.compression –> 是否压缩;transient_lastDdlTime –> 最近一次ddl时间(时间戳) |
| PARAM_VALUE | bit(1) | Key对的value值 |
5.6 元数据接口详解
5.6.1 接口详解
官方hive接口文档地址:https://hive.apache.org/javadocs/ ,在这个上面可以选择对应的hive版本之后再详细看里面的接口。
5.6.2 代码接口详解
由于接口比较多,挑选几个重要的详细说明下
getAllDatabases
getAllTables
getPartition
getSchema
getFunctions
5.6.3 代码样例
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.metastore.HiveMetaStoreClient;
import org.apache.hadoop.hive.metastore.api.FieldSchema;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.metastore.api.Table;
import org.apache.thrift.TException;
import java.util.List;
public class HiveMetastoreApi {
public static void main(String[] args) {
HiveConf hiveConf = new HiveConf();
hiveConf.addResource("hive-site.xml");
HiveMetaStoreClient client = null;
try {
client = new HiveMetaStoreClient(hiveConf);
} catch (MetaException e) {
e.printStackTrace();
}
List<String> tablesList = null;
try {
tablesList = client.getAllTables("db_name");
} catch (MetaException e) {
e.printStackTrace();
}
System.out.print("db_name 数据所有的表: ");
for (String s : tablesList) {
System.out.print(s + "\t");
}
System.out.println();
System.out.println("db_name.table_name 表信息: ");
Table table = null;
try {
table = client.getTable("db_name", "table_name");
} catch (TException e) {
e.printStackTrace();
}
List<FieldSchema> fieldSchemaList = table.getSd().getCols();
for (FieldSchema schema : fieldSchemaList) {
System.out.println("字段: " + schema.getName() + ", 类型: " + schema.getType());
}
client.close();
}
}
6 HiveServer2
beeline客户端是通过hiveserver2服务以JDBC的方式连接到hive的。此种方式也是java,Python等程序中连接hive的途径。
6.1 hive-site.xml配置说明
Hiveserver2允许在配置文件hive-site.xml中进行配置管理,具体的参数为:
hive.server2.thrift.min.worker.threads– 最小工作线程数,默认为5。
hive.server2.thrift.max.worker.threads – 最小工作线程数,默认为500。
hive.server2.thrift.port– TCP 的监听端口,默认为10000。
hive.server2.thrift.bind.host– TCP绑定的主机,默认为localhost
也可以设置环境变量HIVE_SERVER2_THRIFT_BIND_HOST和HIVE_SERVER2_THRIFT_PORT覆盖hive-site.xml设置的主机和端口号。从Hive-0.13.0开始,HiveServer2支持通过HTTP传输消息,该特性当客户端和服务器之间存在代理中介时特别有用。与HTTP传输相关的参数如下:
hive.server2.transport.mode – 默认值为binary(TCP),可选值HTTP。
hive.server2.thrift.http.port– HTTP的监听端口,默认值为10001。
hive.server2.thrift.http.path – 服务的端点名称,默认为 cliservice。
hive.server2.thrift.http.min.worker.threads– 服务池中的最小工作线程,默认为5。
hive.server2.thrift.http.max.worker.threads– 服务池中的最小工作线程,默认为500。
默认情况下,HiveServer2以提交查询的用户执行查询(true),如果hive.server2.enable.doAs设置为false,查询将以运行hiveserver2进程的用户运行。为了防止非加密模式下的内存泄露,可以通过设置下面的参数为true禁用文件系统的缓存:
fs.hdfs.impl.disable.cache – 禁用HDFS文件系统缓存,默认值为false。
fs.file.impl.disable.cache – 禁用本地文件系统缓存,默认值为false。
6.2 hive-site.xml配置样例
通过hiveServer/hiveServer2启动Thrift服务,客户端连接Thrift服务访问Hive数据库(JDBC,JAVA等连接Thrift服务访问Hive)。
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>指定 hiveserver2 连接的端口号</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-master</value>
<description>hiveserver2服务绑定的主机</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
如果为True:Hive Server会以提交用户的身份去执行语句
如果为False:会以hive server daemon的admin user来执行语句
</description>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>123456</value>
<description>Password to use against thrift client</description>
</property>
这两项配置其实是针对HiveServer2的,也就是针对服务端的,对于客户端是通过JDBC来配置主机和端口,比如jdbc:hive2://hadoop-master:10000
因此,假如hive.server2.thrift.bind.host配置为hadoop-master,而此时在hadoop-slave1上通过hive --service hiveserver2这个命令来启动的话,会提示错误:
org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address hadoop-slave1/192.168.133.162:10000.
at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:109)
at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:91)
at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:87)
at org.apache.hive.service.auth.HiveAuthFactory.getServerSocket(HiveAuthFactory.java:241)
at org.apache.hive.service.cli.thrift.ThriftBinaryCLIService.run(ThriftBinaryCLIService.java:66)
at java.lang.Thread.run(Thread.java:748)
2021-08-02 13:02:34,399 INFO [Thread-3]: server.HiveServer2 (HiveStringUtils.java:run(709)) - SHUTDOWN_MSG:
也就是无法在hadoop-slave1上创建ServerSocket。而如果把hive.server2.thrift.bind.host配置为0.0.0.0,或者不配置,那么在任何一个主机上都能顺利启动HiveServer2
6.3 启动方式
启动Thrift服务:hive --service hiveserver2
6.4 测试
测试Thrift服务:新开一个命令行窗口,执行beeline命令。此时提示需要用户密码
root@hadoop-master:~
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.9 by Apache Hive
beeline> !connect jdbc:hive2://hadoop-master:10000
Connecting to jdbc:hive2://hadoop-master:10000
Enter username for jdbc:hive2://hadoop-master:10000:
修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
重新登陆测试:
root@hadoop-master:~
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.9 by Apache Hive
beeline> !connect jdbc:hive2://hadoop-master:10000
Connecting to jdbc:hive2://hadoop-master:10000
Enter username for jdbc:hive2://hadoop-master:10000: root
Enter password for jdbc:hive2://hadoop-master:10000:
Connected to: Apache Hive (version 2.3.9)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop-master:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| testdb |
+----------------+
2 rows selected (0.812 seconds)
0: jdbc:hive2://hadoop-master:10000>
0: jdbc:hive2://hadoop-master:10000>
0: jdbc:hive2://hadoop-master:10000> !quit
Closing: 0: jdbc:hive2://hadoop-master:10000
6.5 安全鉴权
上节中为了快速验证,使用root免密码直接登录,这样在生产环境是不安全的。本节主要介绍下如何进行用户密码登录。
(待补充)
7 Hive内置服务
执行bin/hive --service help 如下:
root@hadoop-master:~
Usage ./hive <parameters> --service serviceName <service parameters>
Service List: beeline cleardanglingscratchdir cli hbaseimport hbaseschematool help hiveburninclient hiveserver2 hplsql jar lineage llap llapdump
llapstatus metastore metatool orcfiledump rcfilecat schemaTool version
Parameters parsed:
--auxpath : Auxiliary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
root@hadoop-master:~
我们可以看到上边输出项Server List,里边显示出Hive支持的服务列表,beeline cli help hiveserver2 hwi jar lineage metastore metatool orcfiledump rcfilecat 等。
下面介绍最有用的一些服务
1、cli:是Command Line Interface 的缩写,是Hive的命令行界面,用的比较多,是默认服务,直接可以在命令行里使用
2、hiveserver:这个可以让Hive以提供Thrift服务的服务器形式来运行,可以允许许多个不同语言编写的客户端进行通信,使用需要启动HiveServer服务以和客户端联系,我们可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口,在默认情况下,端口号为10000,这个可以通过以下方式来启动Hiverserver:
bin/hive --service hiveserver -p 10002
其中-p参数也是用来指定监听端口的
3、hwi:其实就是hive web interface的缩写它是hive的web借口,是hive cli的一个web替代方案
4、jar:与hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop 和Hive类的Java应用程序的简便方式
5、metastore:在默认的情况下,metastore和hive服务运行在同一个进程中,使用这个服务,可以让metastore作为一个单独的进程运行,我们可以通过METASTOE——PORT来指定监听的端口号
7.1 hiveserver
新版中此服务已经被移除,这里还是讲解下hiveServer/HiveServer2的区别。
两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,连这个和都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果(从hive0.15起就不再支持hiveserver了)。
HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,而HiveServer2却不会。既然已经存在HiveServer,为什么还需要HiveServer2呢?这是因为HiveServer不能处理多于一个客户端的并发请求,这是由于HiveServer使用的Thrift接口所导致的限制,不能通过修改HiveServer的代码修正。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供更好的支持。
| HiveServer version | Connection URL | Driver Class |
|---|
| HiveServer2 | jdbc:hive2://: | org.apache.hive.jdbc.HiveDriver |
| HiveServer | jdbc:hive://: | org.apache.hadoop.hive.jdbc.HiveDriver |
7.2 hwi
Hive 2.0 以后才支持Web UI的 bin/hive –service hwi (& 表示后台运行)
用于通过浏览器来访问hive,感觉没多大用途,浏览器访问地址是:127.0.0.1:9999/hwi
7.3 cli
Hive 命令行模式
进入hive安装目录,输入bin/hive的执行程序,或者输入hive –service cli,用于linux平台命令行查询,查询语句基本跟mysql查询语句类似
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)