目录
一、Json文件数据解析
二、Json数据包解析获取图片资源
三、Json数据包解析获取视频资源
一、Json文件数据解析

json字符串:通常类似python数据类型中的列表和字典的结合,也可能是单独的列表或者字典格式,通常可以通过json模块的函数接口转换为python数据类型,也可将python中的数据类型转换成json字符串
json文件:后端通常将数据库的文件统一以json文件的格式传给前端,而前端在对json文件数据进行加工渲染,展示在前端页面。
很多时候,我们使用爬虫从前端页面获取的数据因为经过了加工渲染而并不完整,所以我们有时候需要通过获取后端的json文件数据包来获取数据
二、Json数据包解析获取图片资源
注:本代码仅供爬虫技术学习使用,无任何商业目的
上一篇文章中的王者荣耀英雄皮肤图片获取的途径是从前端代码中的url获取,一共只有93个英雄,获取得到的数据并不完整,而这次我们可以通过网络数据包中的json文件获取数据信息,再通过爬虫下载,一共有115个英雄,是游戏目前的全部英雄


找到网络数据包中的存放英雄信息的json文件数据包,在请求头中拿到json文件的url链接,然后下载得到json文件数据包。
下载王者荣耀全英雄皮肤图片代码:
import requests
import json
import os
url = "https://pvp.qq.com/web201605/js/herolist.json"
response = requests.get(url) # 请求得到json包数据
# print(response.text)
# 此处的json文件格式是列表里面包含字典元素
heroList = json.loads(response.text)
# print(len(heroList)) # 114
for i in heroList:
id = i['ename']
name = i['cname']
print(id, name)
os.makedirs(f"./imag/{name}") # 给每个英雄的皮肤单独创建目录
# 找到英雄皮肤图片的url链接,对比观察寻找规律
cnt = 1
while True:
try:
url = f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{cnt}.jpg"
response = requests.get(url)
if response.status_code != 200:
break
with open(f"./imag/{name}/skin-{cnt}.jpg", "wb") as f:
f.write(response.content)
cnt += 1
except:
print(Exception)
break
三、Json数据包解析获取视频资源
注:本代码仅供学习爬虫技术,无任何商业目的。
1. 首先打开抖音网页,搜索刘畊宏,进入刘教练的视频主页,选择检查,
想要爬取视频,有多种方式,可以通过you-get直接通过视频的网页链接进行下载,但是you-get在面对抖音的反爬机制的时候很多时候会失效,这时我们就要找到视频文件的数据包,直接通过网络请求获取视频文件。
在PC端选择网页,并刷新,查看网络数据包,寻找存放有视频的数据包,包名并没有统一的格式,需要逐一查找,这是一个依靠运气和经验的过程,也有可能根本找不到视频数据包。
查找数据包信息可以逐一查找,也可以按 ctrl F 进行关键字搜索再逐一查找带有关键字的数据包,两种方式都依靠经验和运气。
观察response(响应)里面的信息,一般视频文件前面都有“video”标签,而图片文件的链接会以p开头或者标签为img或p,这并不绝对,需要依靠经验判断。
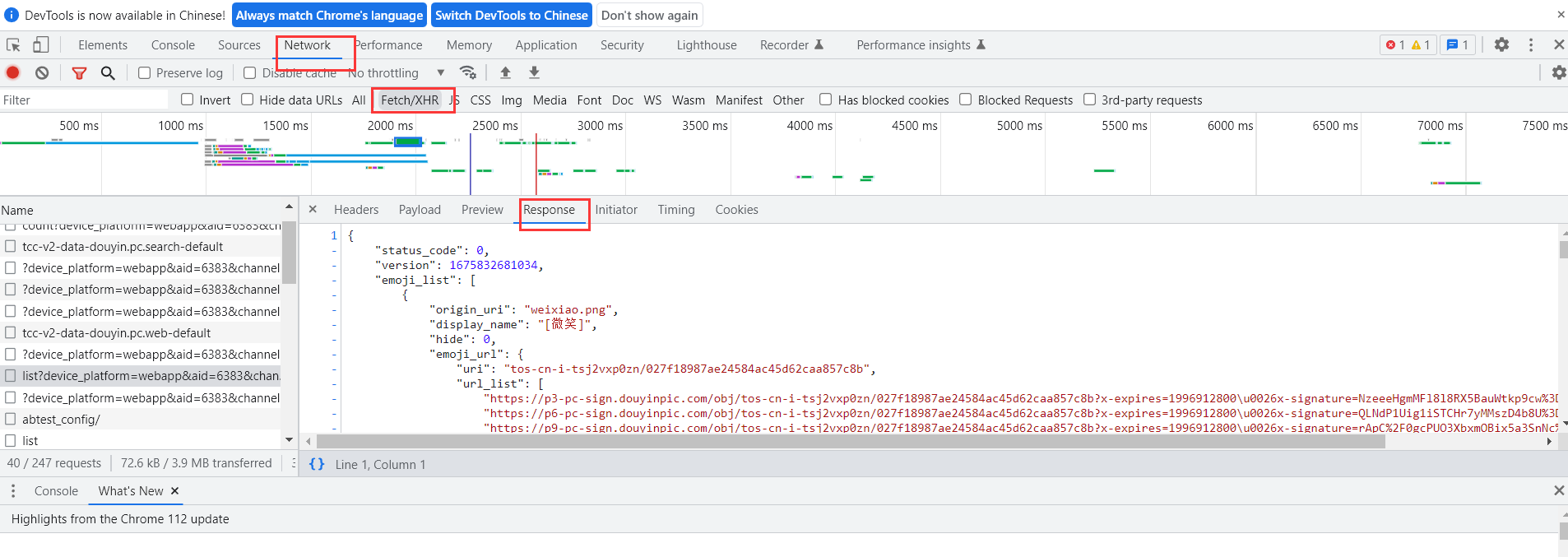
2. 通过在PC端的数据包查找,我并没有找到存放视频文件的数据包,于是我们可以查找移动端的数据包,有可能能够找到,当然在移动端页面进行查找的前提是这个网页有移动端

通过video关键字的索引,在移动端的界面下,我找到一个包含video关键字的url,这里有3个url在url_list列表里,逐一进入这三个url,发现确实是我们需要的视频资源,而且这三个url是同一个视频。
3. 分析数据包里面的数据结构,我们打开一个叫sojson的工具,百度直接搜索就能用,进入后点击json在线解析,这个工具可以帮助我们整理字符串数据,将其转换为可以缩放的格式,方便我们观察数据包的整体结构

通过观察发现我们找到的第一个包含视频链接的url_list标签在play_addr标签下面,按 ctrl F 在sojson工具中对play_addr标签进行索引,找到第一个play_addr后对其他标签进行收缩,发现play_addr标签在video标签下,video标签的上一层是aweme_list标签。
4. 对aweme_list标签进行收缩,观察到里面有18条数据,代表aweme_list里面有18条视频数据

通过观察,这个数据包的结构是最外层为字典,'awere_list'关键字的value值是列表,列表里的元素都是字典,而字典的value值可能是字符串或者嵌套列表。
5. 获取请求数据包的url,在请求头里面可以找到url,请求方式为get,获取url的时候也可以从请求头里面获得user-agent、referer、cookied......信息

6. 获得响应信息response后,将之用json模块进行加载,json.loads(response.text),得到数据包的字典格式数据,然后再通过字典的关键字获得存放有视频信息的列表,再迭代遍历列表,获得每一个视频的文件url和标题
直接对每一个视频文件的url进行网络请求,并将请求得到的数据以二进制格式写入.mp4后缀的文件中,即完成了下载,代码中存放视频的目录请自己定义
import requests
import json
import os
url = 'https://www.douyin.com/aweme/v1/web/aweme/post/?device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAASwhiL0bRi1X_zs7UhAIO2udbD1F_XKrsJMOaukl1Io4&max_cursor=1677067200000&locate_query=false&show_live_replay_strategy=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1536&screen_height=864&browser_language=zh-CN&browser_platform=Win32&browser_name=Chrome&browser_version=113.0.0.0&browser_online=true&engine_name=Blink&engine_version=113.0.0.0&os_name=Windows&os_version=10&cpu_core_num=16&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=50&webid=7201915628194022912&msToken=KLZL7g62CU1OsQ9ZN6MP7VxpOUz2EiwBk1jNRlLoINJEUePgZg-aVWpPAL3LFGL31AYMV3qWtQTlqtxvHIp63YBHJKHELw_3qq0s6kaG6OG3bfqt2cN8Xg==&X-Bogus=DFSzKwVubWXANVl8tJhgWBt/pLvt'
header = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36',
'referer': 'https://www.douyin.com/user/MS4wLjABAAAASwhiL0bRi1X_zs7UhAIO2udbD1F_XKrsJMOaukl1Io4',
'cookie': 'ttwid=1%7CSfdsymdYx1QlfjQTR3xYeFSNa9O6q4f1wFp6BtrRqxs%7C1676826682%7C30e0eb856043a47a208c80c1af10d30fc0cfcf4e270115abae592c5ec3873249; d_ticket=5bc0d2611324cd7fbfc9e0f926fec81dc0d98; n_mh=48GDnZrzh9L0L71QYQe9RHV7INgvIpqOtZbHqRblemk; LOGIN_STATUS=1; store-region=cn-zj; store-region-src=uid; my_rd=1; MONITOR_WEB_ID=685b146d-4ed6-4aa6-aca0-faab96f8cf42; douyin.com; device_web_cpu_core=16; device_web_memory_size=8; webcast_local_quality=null; strategyABtestKey=%221688567746.879%22; sso_uid_tt=6058615d39e33507497ddd539f47deeb; sso_uid_tt_ss=6058615d39e33507497ddd539f47deeb; toutiao_sso_user=b9b49cd114e343c3769792cb05950869; toutiao_sso_user_ss=b9b49cd114e343c3769792cb05950869; sid_ucp_sso_v1=1.0.0-KDFkNmJjYjBkYTc1OTdiOTNjY2EwOWVjMzA4YmQwNWM0YTcxOTA3NGQKCRDD_5WlBhjvMRoCbGYiIGI5YjQ5Y2QxMTRlMzQzYzM3Njk3OTJjYjA1OTUwODY5; ssid_ucp_sso_v1=1.0.0-KDFkNmJjYjBkYTc1OTdiOTNjY2EwOWVjMzA4YmQwNWM0YTcxOTA3NGQKCRDD_5WlBhjvMRoCbGYiIGI5YjQ5Y2QxMTRlMzQzYzM3Njk3OTJjYjA1OTUwODY5; passport_csrf_token=b36f107eb1f86486b5946c1615b05276; passport_csrf_token_default=b36f107eb1f86486b5946c1615b05276; odin_tt=8be0aee3be15b092d053ad20045320656173ff5fab52b26d527858f414c45896; sid_guard=5443fa7b2b56f9a07aee61e8f36daac1%7C1688567748%7C21600%7CWed%2C+05-Jul-2023+20%3A35%3A48+GMT; uid_tt=acd1f407a3f1d7894a1653efdd479f41; uid_tt_ss=acd1f407a3f1d7894a1653efdd479f41; sid_tt=5443fa7b2b56f9a07aee61e8f36daac1; sessionid=5443fa7b2b56f9a07aee61e8f36daac1; sessionid_ss=5443fa7b2b56f9a07aee61e8f36daac1; sid_ucp_v1=1.0.0-KDU0OGJkYTI2ZTNjMWM1NjA3Yjc3Njk1ZmM3Mjg0OWY3MTdhM2M0YmEKCBDE_5WlBhgNGgJsZiIgNTQ0M2ZhN2IyYjU2ZjlhMDdhZWU2MWU4ZjM2ZGFhYzE; ssid_ucp_v1=1.0.0-KDU0OGJkYTI2ZTNjMWM1NjA3Yjc3Njk1ZmM3Mjg0OWY3MTdhM2M0YmEKCBDE_5WlBhgNGgJsZiIgNTQ0M2ZhN2IyYjU2ZjlhMDdhZWU2MWU4ZjM2ZGFhYzE; s_v_web_id=verify_ljptn0ct_kfiNKmlP_dyZH_47Aw_Aa38_Ft8lUaobhxaE; __bd_ticket_guard_local_probe=1688567747233; __ac_nonce=064a57fc40047d7bc5fa4; __ac_signature=_02B4Z6wo00f01XnbypAAAIDA8pBRcRDkeQl5-84AADrX8ttGZsqVOhTieUZ2pt27EMIqPRl1Kli8-x0yYjBdJ7zXwvykc-U4kkF00iB1e.yTLrCY2O5q7RNkrRl3ggCX5kR8gLBBUr.jlsTD8b; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1689172548703%2C%22type%22%3Anull%7D; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWl0ZXJhdGlvbi12ZXJzaW9uIjoxLCJiZC10aWNrZXQtZ3VhcmQtY2xpZW50LWNlcnQiOiItLS0tLUJFR0lOIENFUlRJRklDQVRFLS0tLS1cbk1JSUNGakNDQWJ1Z0F3SUJBZ0lWQUtuaVp0K09XZEZtT2FNSGlCZFYycnY1TmRuK01Bb0dDQ3FHU000OUJBTUNcbk1ERXhDekFKQmdOVkJBWVRBa05PTVNJd0lBWURWUVFEREJsMGFXTnJaWFJmWjNWaGNtUmZZMkZmWldOa2MyRmZcbk1qVTJNQjRYRFRJek1EUXhOREUyTkRJeE5sb1hEVE16TURReE5UQXdOREl4Tmxvd0p6RUxNQWtHQTFVRUJoTUNcblEwNHhHREFXQmdOVkJBTU1EMkprWDNScFkydGxkRjluZFdGeVpEQlpNQk1HQnlxR1NNNDlBZ0VHQ0NxR1NNNDlcbkF3RUhBMElBQkpTVmplb1c4QTBpbmVHd3RBQ2xaTVZrS1F0djlvTDEzT0pPYUp3SVdGaEtTcUpPSkNVT3liK3pcbnFwb3grVFNNYzYxV2RtVFB4VkxPOTJOeXRrWFZ5VUdqZ2Jrd2diWXdEZ1lEVlIwUEFRSC9CQVFEQWdXZ01ERUdcbkExVWRKUVFxTUNnR0NDc0dBUVVGQndNQkJnZ3JCZ0VGQlFjREFnWUlLd1lCQlFVSEF3TUdDQ3NHQVFVRkJ3TUVcbk1Da0dBMVVkRGdRaUJDREFka0kxdHNKblV5K3ZsUGw2ZmxyWEJyT3d4eFFXWE5Pejd2MmRJcmZubWpBckJnTlZcbkhTTUVKREFpZ0NBeXBXZnFqbVJJRW8zTVRrMUFlM01VbTBkdFUzcWswWURYZVpTWGV5SkhnekFaQmdOVkhSRUVcbkVqQVFnZzUzZDNjdVpHOTFlV2x1TG1OdmJUQUtCZ2dxaGtqT1BRUURBZ05KQURCR0FpRUFzQ2ZRcUtJa05sZVFcbjdUOHg5MjFMYmhzdFJkSS9OblllVGFMS1dnNUQ0cFlDSVFDeERpZnRKMXdQMWNkWEIwWHNKck0yVXYwZGJYczVcbk1GbFdjRzBDaU5MY0d3PT1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; FORCE_LOGIN=%7B%22videoConsumedRemainSeconds%22%3A180%7D; csrf_session_id=d792449829359253fa25f0a8d9e72a59; SEARCH_RESULT_LIST_TYPE=%22single%22; home_can_add_dy_2_desktop=%221%22; msToken=EY2sJBH_qEN4ep44noUrXW_qzCkWVNvtjWaTqWkqVAZgC9JMQUoQs6kryIFMcrSdONLSkfIEAu2NXOZ2r_jocknLqOxnwDn6sucTrDTivy5oSmnYs2V9fA==; download_guide=%221%2F20230705%2F0%22; msToken=KLZL7g62CU1OsQ9ZN6MP7VxpOUz2EiwBk1jNRlLoINJEUePgZg-aVWpPAL3LFGL31AYMV3qWtQTlqtxvHIp63YBHJKHELw_3qq0s6kaG6OG3bfqt2cN8Xg==; tt_scid=IKrnsboqod05Ql8FTZwSOJiRmmThn7J2ziAKN17O5cWleCch8dPbt7lG9qxdm9ed54d6; pwa2=%220%7C0%7C1%7C0%22'
}
response = requests.get(url, headers=header)
# print(response.text)
# 通过json提取数据,通过观察可得json最外层是字典格式
data_dict = json.loads(response.text)
data_list = data_dict['aweme_list'] # data_list的每一个元素是字典
# print(len(data_list)) # 18
os.makedirs(f"./DouYin/")
for i in data_list:
v_title = i['desc']
v_url = i['video']['play_addr']['url_list'][0]
print(v_title, v_url) #通过观察可得第一个和最后一个链接是音频
res = requests.get(v_url, headers=header)
with open(f"./DouYin/{v_title}.mp4", "wb") as f:
f.write(res.content)