简介
cuBLAS库用于进行矩阵运算,它包含两套API,一个是常用到的cuBLAS API,需要用户自己分配GPU内存空间,按照规定格式填入数据,;还有一套CUBLASXT API,可以分配数据在CPU端,然后调用函数,它会自动管理内存、执行计算。既然都用cuda了,其实还是用第一套API多一点。
官方文档参考
最初,为了尽可能地兼容Fortran语言环境,cuBLAS库被设计成列优先存储的数据格式,不过C/C++是行优先的,我们比较好理解的也是行优先的格式,所以需要费点心思在数据格式上。
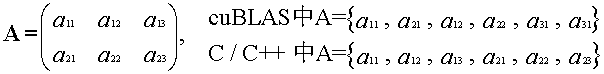
cuBLAS库新特性
现在装好cuda会自带cuBLAS库的,只要include 头文件“cublas_v2.h”就可以调用它了。相比与之前的旧库,现在的cuBLAS矩阵运算库有些新特性:
- handle更加可控,更加适用于多GPU或CPU多进程。handle是cuBLAS库上下文的句柄,可以把数据、函数等等连接在一起,就想Cuda的stream一样。现在,新版本的cuBLAS可以用简单的函数创建句柄,然后把它绑定到不同的函数、数据上去;非常方便。
- 所有的函数都可以返回错误标识符cublasStatus_t了。可以更加方便调试,发现代码的具体错误原因。
- 函数cublasAlloc() and cublasFree()被摒弃了。
cuBLAS代码热身
官方手册在结束introduction后就来了一段简单的代码。
cublasSetMatrix()
先看个函数cublasSetMatrix():
cublasSetMatrix(int rows, int cols, int elemSize, const void *A,
int lda, void *B, int ldb)
这个函数可以把CPU上的矩阵A拷贝到GPU上的矩阵B,两个矩阵都是列优先存储的格式。lda是A的leading dimension ,既然是列优先,那么就是A的行数(A的一列有多少个元素);ldb同理。
cublasGetMatrix()作用与之相反。
cudaMalloc()
分配GPU内存的函数
float* devPtrA;
cudaStat = cudaMalloc ((void**)&devPtrA, M*N*sizeof(*a));
为什么第一个参数是二级指针呢?
因为devPtrA是一个CPU上的指针,我现在分配了一块GPU内存空间,假设这个空间的首地址是 #0024,我想要修改devPtrA的值怎么办呢?C语言的基础告诉我们,函数想要修改一个变量的值,就得把他的指针穿进去,而不是仅仅作为形参传过去。所以这里是二级指针,因为我要把一级指针的值修改为 #0024。
cublasSscal()
传入矩阵x,总大小为n,每隔incx个数,就乘以alpha。
cublasSscal(cublasHandle_t handle, int n,const float *alpha,
float *x, int incx)
很简单的函数,纯粹为了演示。
源代码
来看一下:
//Example. Application Using C and CUBLAS: 0-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#define M 6 //6行
#define N 5 //5列
#define IDX2C(i,j,ld) (((j)*(ld))+(i))
/*一个把坐标(i, j)转化为cublas数据格式坐标的函数;
假设一个点位于第i行第j列,每一列的长度为ld,
则计算出来的列优先坐标就是 j*ld+i */
static __inline__ void modify (cublasHandle_t handle, float *m, int ldm, int n, int p, int q, float alpha, float beta){
cublasSscal (handle, n-q, &alpha, &m[IDX2C(p,q,ldm)], ldm);
cublasSscal (handle, ldm-p, &beta, &m[IDX2C(p,q,ldm)], 1);
}
int main (void){
cudaError_t cudaStat;
cublasStatus_t stat;
cublasHandle_t handle; //管理一个cublas上下文的句柄
int i, j;
float* devPtrA;
float* a = 0;
a = (float *)malloc (M * N * sizeof (*a));
if (!a) {
printf ("host memory allocation failed");
return EXIT_FAILURE;
}
for (j = 0; j < N; j++) {
for (i = 0; i < M; i++) {
a[IDX2C(i,j,M)] = (float)(i * M + j + 1);
}
}
cudaStat = cudaMalloc ((void**)&devPtrA, M*N*sizeof(*a));
if (cudaStat != cudaSuccess) {
printf ("device memory allocation failed");
return EXIT_FAILURE;
}
stat = cublasCreate(&handle);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("CUBLAS initialization failed\n");
return EXIT_FAILURE;
}
stat = cublasSetMatrix (M, N, sizeof(*a), a, M, devPtrA, M);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("data download failed");
cudaFree (devPtrA);
cublasDestroy(handle);
return EXIT_FAILURE;
}
modify (handle, devPtrA, M, N, 1, 2, 16.0f, 12.0f);
stat = cublasGetMatrix (M, N, sizeof(*a), devPtrA, M, a, M);
if (stat != CUBLAS_STATUS_SUCCESS) {
printf ("data upload failed");
cudaFree (devPtrA);
cublasDestroy(handle);
return EXIT_FAILURE;
}
cudaFree (devPtrA);
cublasDestroy(handle);
for (j = 0; j < N; j++) {
for (i = 0; i < M; i++) {
printf ("%7.0f", a[IDX2C(i,j,M)]);
}
printf ("\n");
}
free(a);
return EXIT_SUCCESS;
}
cuBLAS 辅助函数
上下文管理
使用cuBLAS库函数,必须初始化一个句柄来管理cuBLAS上下文。函数为cublasCreate(),销毁的函数为cublasDestroy()。这些操作全部需要显式的定义,这样用户同时创建多个handle,绑定到不同的GPU上去,执行不同的运算,这样多个handle之间的计算工作就可以互不影响。
cublasCreate(cublasHandle_t *handle)
官方手册建议尽可能少的创建handle,并且在运行任何cuBLAS库函数之前创建好handle。handle会和当前的device(当前的GPU显卡)绑定,如果有多块GPU,你可以为每一块GPU创建一个handle。或者只有一个GPU,你也可以创建多个handle与之绑定。
cublasDestroy(cublasHandle_t handle)
销毁handle时,会隐性调用同步阻塞函数cublasDeviceSynchronize()。
复制矩阵
cublasSetVector(int n, int elemSize,
const void *x, int incx, void *y, int incy)
类似与前面的cublasSetMatrix(),这个函数也是把数据从CPU复制到GPU。CPU上包含n个元素的向量x,数据复制到GPU矩阵y上,每个元素的字节数为elemSize,incx是x的主维的长度,如果是列优先格式,那么就是x的行数,incy同理。
数据类型标示
大多数用于计算的cuBLAS函数名字里都包含数据类型信息,表明这个函数专门用于处理float、double还是什么数据类型的。

cuBLAS 运算函数
这部分函数被官方分为了3个等级,Level-1、Level-2、Level-3处理的情境逐渐变得复杂,功能变得强大。Level-1里求最大最小值,求和,旋转等等。Level-3就全是矩阵与矩阵间运算的函数了,矩阵相乘就在这里面。
矩阵相乘
下面是Level-3函数cublasSgemm(),处理float数,还有cublasDgemm()也是矩阵相乘,处理的是double。
cublasStatus_t cublasSgemm(cublasHandle_t handle,
cublasOperation_t transa, cublasOperation_t transb,
int m, int n, int k,
const float *alpha,
const float *A, int lda,
const float *B, int ldb,
const float *beta,
float *C, int ldc)
函数求:
C
=
α
∗
A
∗
B
+
β
∗
C
C=\alpha *A*B+\beta *C
C=α∗A∗B+β∗C,令
α
=
1
\alpha = 1
α=1,
β
=
0
\beta = 0
β=0,就可以求A*B。
第二、三个参数cublasOperation_t类型,可以等于CUBLAS_OP_T表示需要转置后运算,或者不需要CUBLAS_OP_N;
m: A有多少行;
n: B有多少列;
k: A的列数,也是B的行数;
其他的不用多说了,都提到过。注意还是列优先。