作者视频讲解:https://www.bilibili.com/video/av40510835/
源码地址:https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
论文地址:https://arxiv.org/abs/1611.08050
源码讲解博客地址
pytorch代码地址1:https://github.com/Hzzone/pytorch-openpose
pytorch代码地址2:https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation
pytorch2讲解博客:https://www.cnblogs.com/demian/p/8988396.html
亮点: 文章提出了一种可以高效的检测多人2D姿态的方法,使用bottom-up的方法,最图像中的目标数量不敏感,能够同时获得高的速度和精度。
方法: 使用无参数的表达方法—— Part Affinity Fields (PAFs) 关系亲和场,来学习图像中每个个体的关节之间的关系。
整体过程: bottom-up,将全局语义进行编码,大量的bottom-up分析过程保证率速度和精度的平衡。
学习过程: 利用两个相同的分支同时学习关键部位的位置和关系
1、Introduction
人体2D姿态估计是一个对人体关键部位或关键点的定位问题,主要研究如何寻找一个个体的关键部位。
估计一个图像中的多人姿态,尤其是复杂场景的时候,是非常有挑战性的。
- 首先,每个图像中包含的人数量是未知的,且这些人可能以任何可能的姿态或尺度出现。
- 其次,人体间有复杂的相互关系,比如接触、遮挡、关节连接等,导致关节之间的关系难以建立
- 一般方法的运行速度和图像中的目标个数有很大的关系,难以做到实时
Top-down方法:
过程:使用人体检测器,并对每个检测使用单人姿态估计(single-person pose estimation)。
不足:
- top-down方法借助已有的方法来实现单人姿态估计,但是对前期的检测依赖很大,如果一个人体检测器没有检测出人体,比如人体距离很近,则没有办法弥补。
- 这种方法的运行时间和图像内的目标个数呈正比,计算量很大
Bottom-up方法:
不会直接使用从别的body或别的person来的全局语义信息。
前期的bottom-up方法并没有在效率上做提高,因为最后的全局推理需要很大的开销。
- Pishchulin等人提出的种子工作,提出了一种联合了标签部分检测候选以及将它们联系到个体上的自底向上的方法。然而,在一个全连接图上解决整数线性规划问题是一个NP难问题,并且其平均处理时间大约需要几小时。
- Insafutdinov等人结合基于ResNet的有效的部分检测器以及图像从属成对分数(image-dependent pairwise scores)构建模型,极大的提高了运行效率,但是这个方法对每张图片的处理时间仍然需要几分钟,这是受限于部分检测器的数量。
- 成对表现(pairwise representations)在[11]中使用了,其很难做精确的回归,因此需要独立的逻辑回归
现有的bottom-up方法都是先检测身体部位的关键点,然后再连接这些关键点得到人的姿态骨架。
该文章为了快速的把这些点连到一起,提出的亲和关系场,来实现快速的关键点连接。
该文章提出了一种适合于多人姿态估计的高效的方法,且在多个公开数据集上取得了SOTA的效果。
贡献点:
- 首次提出了利用亲和关系场(PAFs)得到关系得分的bottom-up表达方法,用一系列的2D向量场对图像域中的肢体的位置和方向进行编码。
-
文章证明了同时推导这些检测表示以及全局信息联系编码有效的允许了使用一个贪婪解析步骤去实现高质量的结果,而只需要少量的计算花销

2、Method
图2展示了该文章所提出方法的整体pipline:
- 输入:大小为 wxh 的彩色图像(Fig2(a))
- 输出:图像中每个人的结构关键点(Fig2(e))

第一步:前馈网络同时预测下面两者
-
① 一系列的身体部件位置的2D置信响应图 S (2(b))
-
② 一系列部件关系的 2D 向量场 L (2©),是对部件间的联系等级进行编码
S
=
(
S
1
,
S
2
,
.
.
.
,
S
J
)
S=(S_1, S_2, ... ,S_J)
S=(S1,S2,...,SJ),有 J 个置信响应图(confidence map),每个部件(part)一个
L
=
(
L
1
,
L
2
,
.
.
.
,
L
C
)
L=(L_1, L_2, ... ,L_C)
L=(L1,L2,...,LC),有C个向量场,每个肢体(limb)一个,
L
C
L_C
LC中的每个图像位置编码一个2D向量。如图1所示,在亲和场中的每个像素,都会用一个2D向量来对其进行编码,编码其位置和方向,也就是每个箭头就是一个向量。
备注:一个部件对儿构成一个limb
第二步:通过一系列的推理(Fig2(d)),解析置信响应图和affinity fields ,输出图像中每个人体的2D关键点。
2.1 Simultaneous Detection and Association
本文的方法如图3所示,同时预测两个东西,来实现关键点到关键点的编码:
- 检测置信图,有米黄色的 top branch 来预测
- 亲和场,由蓝色的 bottom branch 来预测
每个branch都是一个迭代预测的结构,是参考 CPMs 的结构的,这个结构利用连续的 stage来精细化预测结果,并且每个stage输出有中间监督,避免了梯度消失现象的发生。

处理过程:
- 首先,用卷积网络对输入图像进行特征提取(文中用的VGG-19的前10层初始化并fine-tune),产生一系列特征图F,输入每个brach的第一个stage。
- 第一个stage,网络产生一系列的检测置信图
S
1
=
ρ
1
(
F
)
S^1=\rho^1(F)
S1=ρ1(F),和一系列亲和场
L
1
=
ϕ
1
(
F
)
L^1=\phi^1(F)
L1=ϕ1(F)。其中,
ρ
1
\rho^1
ρ1和
ϕ
1
\phi^1
ϕ1分别是 stage=1推理阶段的CNN。
- 之后的stage,这两个branch中的每一个分支的前一个stage的输出结合起来,再和 original image features F一起,被concat 起来,用来预测更精细的输出:
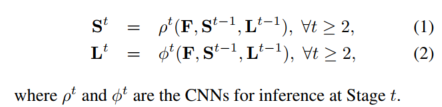
图4是不同stage预测输出的精细程度对比。

贯穿各个阶段的(第一行)右手腕的置信图以及右前臂PAFs(第二行)。虽然在早先阶段中有着左右身体部位和肢体的混淆,但是通过在后续的全局推理中,评估结果得到了改善,如上图圈出的区域。
为了引导网络迭代的在第一个branch预测关键点的置信图,在第二个branch预测PAFs。每个分支一个loss函数。
Loss函数: L2 损失
特别地: 文中动态的调整了 loss函数,来解决实际的问题,也就是考虑到一些数据集中没有完全的标注所有的人体。所以每个分支的loss函数如下:

其中
S
j
∗
S_j^∗
Sj∗是真实的部位置信度图,
L
c
∗
L_c^*
Lc∗是真实的部位联系向量域,
W
W
W是一个二进制编码,当在图像的位置
p
p
p处缺少标注时,
W
(
p
)
=
0
W(p)=0
W(p)=0。该编码用来避免惩罚在训练过程中的正确的积极预测。每一个阶段的中间监督通过定期补充梯度的方式而被用来解决梯度消失问题。整体的目标函数如下:
总体的loss函数:
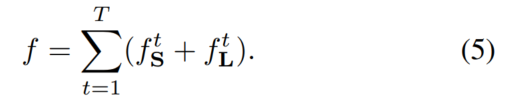
2.2 Confidence Maps for part detection
为了在训练过程中评估上述
f
S
f_S
fS,作者从标注的 2D 关键点中生成了真实的置信响应图 confidence maps
S
∗
S^*
S∗。
每个置信图(confidence map)都代表一个关键点在每个像素位置上出现的置信度(belief)
- 如果图中只有单个person出现,则每个可见的关键点对应的 confidence map 都只有一个峰值点。
- 如果图中有多个person出现,对于每个 person k,都会有一个 peak 对应每个可见的关键点 j。
首先对每个 person k 都生成一个 confidence map
S
j
,
k
∗
S_{j,k}^*
Sj,k∗,
x
j
,
k
x_{j,k}
xj,k 代表图中第 k 个person 的第 j 个关键点。则在
S
j
,
k
∗
S_{j,k}^*
Sj,k∗ 的位置 p 上的值定义为:
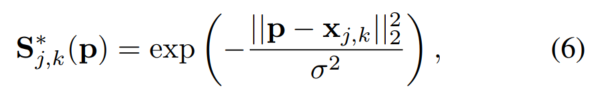
其中,
δ
\delta
δ 标准差,能控制峰值的延展范围,
x
j
,
k
x_{j,k}
xj,k 是均值,
网络预测得到的真实的 confidence map 是对单个confidence map利用 max 操作之后得到的集合:
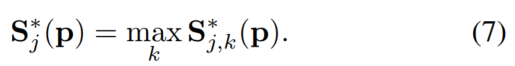
使用 max 操作而非均值操作,这样可以保留靠近 peak 附近值的不同性,如图所示,在测试时,预测 confidence map(如图4第一行所示),并且利用非极大值抑制操作得到候选部位(body parts candidates)。

2.3 Part Affinity Fields for Part Association

给定一系列检测到的身体部位(如图5a的红色点和蓝色点所示),如何在人数未知的情况下,将这些点联系起来得到姿态估计?
需要对每个部位对儿(pair of parts)关系的置信度量,也就是他们属于同一个人的置信。
如何做?
度量相关性的一个可能的方法是检测形成每个“肢体”的关键点的“midpoint”,并检查该midpoint在候选关键点中间的作用(incidence)。,如图5b所示。
这样做的问题:
当人很聚集的时候,这些 midpoints 可能会是是错误的关联(如图5b的绿色线)
这个问题出现的原因:这个表达方式有两个受限点
- 仅仅编码了每个 limb 的位置,没有编码方向
- 将肢体的支撑区域缩小到了一个点
为了解决这个问题,文中提出了一种新的特征表达方式:part affinity fields,同时保留肢体区域的位置的方向信息(Fig5c)
part affinity 是对每个 limb 的一个2D 向量场,如Fig1d,对每个特定肢体区域的每个点,该 2D 向量会对每个点从 limb 的一个 part 到另一个 part 的方向进行编码,如图所示,每个类别的 limb 都有对应的 affinity field 来连接着两个有关系的body parts。
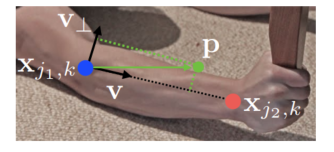
单个 limb 如图所示,令
x
j
1
,
k
x_{j_1,k}
xj1,k 和
x
j
2
,
k
x_{j_2,k}
xj2,k 分别表示第 k 个人的第 c 个limb 的 body parts
j
1
j_1
j1 和
j
2
j_2
j2 的真实位置。如果一个点 p 在这个 limb 上,则在位置
L
c
,
k
∗
(
p
)
L_{c,k}^*(p)
Lc,k∗(p) 上的值是一个从
j
1
j_1
j1 指向
j
2
j_2
j2 的单位向量,其他点的值都是0。
为了在训练的过程中评价公式(5)中的
f
L
f_L
fL,定义在位置 p 上的实际(groundtruth)的 part affinity vector field 为
K
c
,
k
∗
K_{c,k}^*
Kc,k∗,

此处,v 是 limb 方向上的单位向量,公式如下:
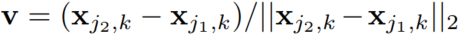
在 limb 上的点的集合被定义为在线段距离阈值内的点集,也就是这些点 p 都:
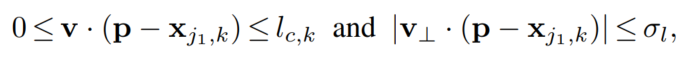
其中,limb 的宽度
ρ
l
\rho_l
ρl 是像素上的距离,limb 的长度是
l
c
,
k
=
∣
∣
x
j
2
,
k
−
x
j
1
,
k
∣
∣
l_{c,k}=||x_{j_2,k}-x_{j_1,k}||
lc,k=∣∣xj2,k−xj1,k∣∣,
v
⊥
v_{\perp}
v⊥ 是垂直于
v
v
v 的向量。
实际的 part affinity field 是一个图像中的所有的 people 的 affinity filed 的均值。
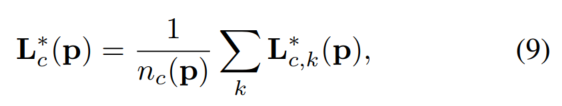
其中,
n
p
n_p
np 是所有 k 个人在点 p 上的非零向量的个数,也就是在一个像素点上有相互遮挡的不同人的limb的均值。
测试阶段,作通过计算对应 PAF 的线段积分来度量所有候选部位的关系,沿着线段来将候选部位的位置结合起来。也就是说,作者度量预测的 PAF 和候选 limb 是否是一致的,这可以通过将检测的身体部位结合起来来形成。
评估两个关键点之间的相关性:
对应两个候选部位位置:
d
j
1
d_{j_1}
dj1 和
d
j
2
d_{j_2}
dj2,简化预测位置的 affinity field,
L
c
L_c
Lc 沿着线段来度量置信度
计算两个关键点连线向量和两个关键点连线上各个像素的PAF向量之间的点积的积分作为两个关键点之间的相关性:
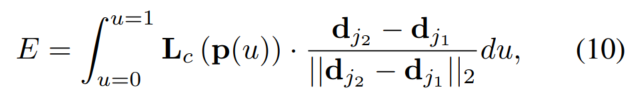
其中,
p
(
u
)
p(u)
p(u) 是插入两个身体部位
d
j
1
d_{j_1}
dj1 和
d
j
2
d_{j_2}
dj2 中的点的位置。
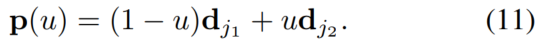
实际中,作者利用间距为 u 的等间距求和,来近似该积分
2.4 Multi-person parsing using PAFs
作者在检测得到的 confidence map 上使用非极大值抑制来得到一系列离散的候选部位位置。
对于每个位置,由于可能多人存在或误检,可能都会有多个候选者(如图6b)。
这些候选部位能够定义大量的可能 limbs
作者使用 PAF 上的线积分的方法来计算每个候选 limb 的得分,如公式10所示。
寻找最优解析的问题是一个已知为NP-Hard的k维匹配问题(fig6c),本文中,作者提出了一个贪婪的松弛方法,同一获得了高质量的匹配结果。
作者推测原因是:pair-wise 的关系得分隐藏的对全局语义信息进行了编码,由于 PFA 网络的大感受野。

图6:图匹配 (a)检测到part的原始图像 (b)k-分割图 (c)树形结构 (d)二分图
作者首先对多个人获得一系列的身体部位检测候选集合
D
J
D_J
DJ,且
D
J
=
d
j
m
:
j
∈
{
1...
J
}
,
m
∈
{
1...
N
j
}
D_J={d_j^m: j\in \{1...J\}, m \in \{1...N_j\}}
DJ=djm:j∈{1...J},m∈{1...Nj},
N
j
N_j
Nj 是第 j 个part的候选数量,
d
j
m
d_j^m
djm 是第 m 个检测的候选 part 的位置。
这些检测的候选part仍然需要和同一人体的其他 part 相联系,也就是说需要寻找到那些被检测出来的且实际上相连在一起的limb。
定义一个变量
Z
=
{
z
j
1
j
2
m
n
}
Z=\{z_{j_1j_2}^{mn}\}
Z={zj1j2mn},且
j
1
,
j
2
∈
{
1...
J
}
,
m
∈
{
1...
N
j
1
}
,
n
∈
{
1...
N
j
2
}
j_1,j_2 \in \{1...J\},m\in \{1...N_{j_1}\}, n\in \{1...N_{j_2}\}
j1,j2∈{1...J},m∈{1...Nj1},n∈{1...Nj2}。
加上对于第c个limb的一个单独的 part 对儿
j
1
,
j
2
j_1, j_2
j1,j2(如脖子和右臀),则找到它俩之间关系的问题就简化成了一个最大权值二分图匹配问题[32],如图5b所示,在这个图匹配问题中,图的节点就是检测得到的候选 part
D
j
1
D_{j_1}
Dj1 和
D
j
2
D_{j_2}
Dj2,图的边是这两个 part 的可能的连接关系。此外,使用公式(10)为每个边赋权值。
二分图中的匹配是这样选择的边的子集,没有量过边共享一个节点。
作者的目标是为选择的那个边找到最大权值的匹配:
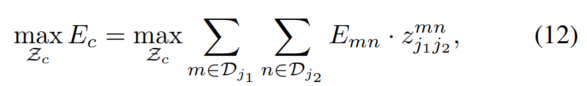
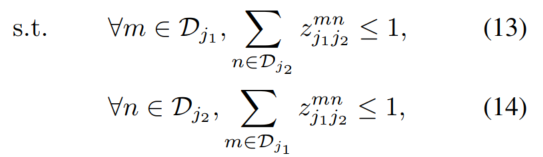
其中:
-
E
c
E_c
Ec 是从 c 类的limb中匹配的整体权重。
-
Z
c
Z_c
Zc 是
Z
Z
Z 的针对 c 类 limb 的子集
-
E
m
n
E_{mn}
Emn 是 part
d
j
1
m
d_{j_1}^m
dj1m 和
d
j
2
m
d_{j_2}^m
dj2m 的 part affinity,公式10定义的
公式13、14强化了一件事:没有两个边能共享一个节点,也就是说,没有两个不同类别的 limb 能够共享一个 part。
作者使用Hungarian algorithm [14] 来得到最优匹配。
涉及到寻找多个人的全身姿态时,定义
Z
Z
Z 是一个
K
−
d
i
m
e
n
s
i
o
n
a
l
K-dimensional
K−dimensional 的匹配问题。
该问题是一个 NP-Hard 问题,存在许多松弛。
本文中,作者使用了两个松弛条件来进行优化:
- 其一,作者选择最小数量的 edges 来得到人体姿态的生成树骨架,而不是使用完整的图,如图6c所示。
- 其二,作者进一步将匹配问题分解成了一系列二分图匹配的子问题,并且发现了相邻的树节点间的匹配是独立的,如图6d所示。
经过试验发现,最小的贪婪的推理可以很好的近似全局解,原因在于,相邻节点的关系可以很明确的用 PAFs来解释, 但是在内部,非相邻的节点间的关系是在CNN中隐藏的,CNN中可以包含这些关系的原因在于 CNN 训练的时候有一个大的感受野,并且,从不相邻节点产生的 PAFs 同一会影响预测的 PAF。
利用这两个松弛,优化问题被简化为如下表达:
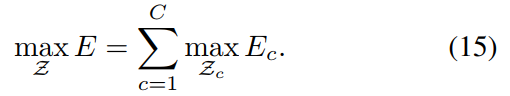
所以,对每个类别的 limb 得到其与 limb 的候选关系是独立的(使用公式12-14)
得到所有的limb 关系候选之后,可以将这些连接关系聚合起来,共享相同部位的检测候选结果。
文章的树结构优化策略比全连通图的优化策略快好感数量级。
二分图匹配问题:
当图中存在多个手肘和手腕时,如果确定是否属于同一个人?
文章中将关键点作为图的顶点,关键点之间的相关性PAF作为图的边,则将多人检测问题就可以转化为二分图匹配问题,并用匈牙利算法求得相连关键点最优匹配:
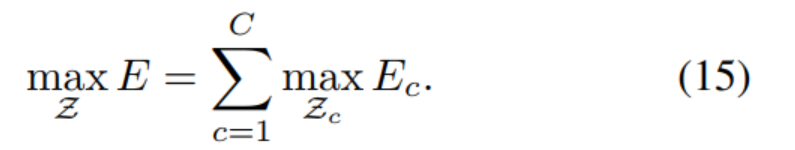
二分图匹配:
二分图:图的一种特例,包含两个点群 X,Y,同一个点群内无边,不同点群之间有边。
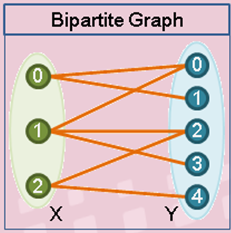
二分匹配:二分图上进行匹配,一个点群中的点只与另一个点群中的点进行唯一匹配,即任意两条边没有公共顶点
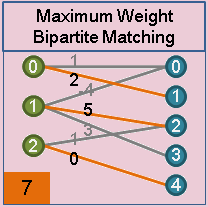
最大匹配:匹配边数最多
完美匹配:所有点都是匹配点
最大权重匹配:所有匹配边权重之和最大
求解最大匹配方法:匈牙利算法
3、 Results
测试数据集:
- MPII human multi-person dataset
- COCO 2016
3.1 MPII