一、 Node管理
1.1 Node的隔离与恢复
某些情况下需要将Node隔离,使其脱离kubernetes调度范围。可以使用YAML文件或者kubectl命令进行调整。
1. 使用YAML文件
# unschedule_node.yaml
apiVersion: v1
kind: Node
metadata:
name: k8s-node-1
labels:
kubernetes.io/hostname: k8s-node-1
spce:
unschedulable: true
执行kubectl replace命令,完成对Node状态的修改:
kubectl replace -f unschedule_node.yaml
需要将某个node重新纳入集群范围的时候,将 unschedulable 的值该为false,再次执行 kubectl replace命令,就能恢复对该Node的调度了。
2. 使用 kubectl patch命令
也可以直接使用kubectl patch命令实现Node隔离调度的效果,不使用配置文件
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# 改为false 恢复调度
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":false}}'
3. 使用kubect cordon 和 uncordon 命令
使用 kubectl 子命令 cordon 和 uncordon 也可以实现 Node 隔离调度和恢复调度
# 隔离调度
kubectl cordon k8s-node-1
# 恢复调度
kubectl uncordon k8s-node-1
注意: 某个Node 脱离调度范围时,其上运行的Pod不会自动停止,需要对其手动停止
1.2 Node 的扩容
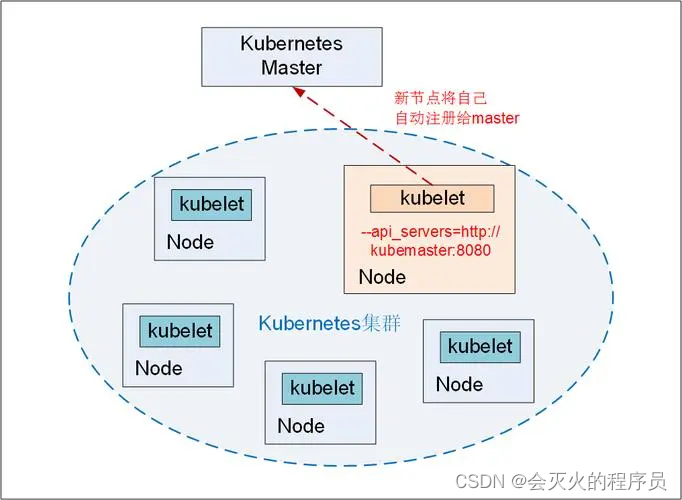
Kubernetes 集群中,加入一个新的Node 有以下几步:
- 在新的node上安装 docker、 kubelet 和 kube-proxy
- 配置kubelet 和 kube-proxy 服务的启动参数,将 master url 指定为当前kubernetes 集群master的地址
- 启动安装的服务,新节点将自己自动注册给master
二、 更新资源对象的Label
Label (标签)是可灵活定义的对象属性,可以通过 kubectl label 命令 进行增加、删除、修改标签
# 给已经创建的 Pod "redis-master-bobr0" 添加label "role=backend"
kubectl label pod redis-master-bobr0 role=backend
# 查看 pod的 label
kubectl get pods -Lrole
# 删除label 只需要在命令最后指定label的key名并与一个减号相连即可
kubectl label pod redis-master-bobr0 role-
# 修改Label,需要增加 --overwrite 参数
kubectl label pod redis-master-bobr0 rolo=master --overwrite
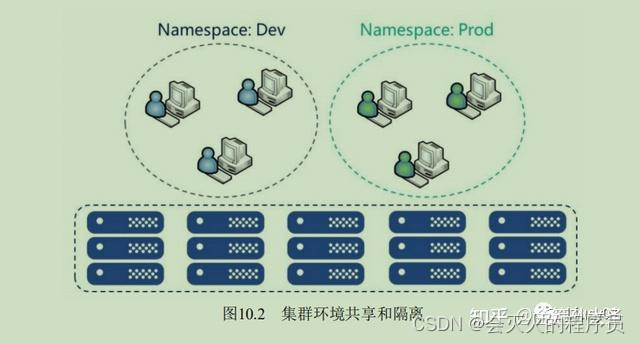
三、 Namespace: 集群环境共享与隔离
Kubernetes 通过 Namespace(命名空间)和Context 的设置对不同的工作组进行区分,使得它们既可以共享同一个kubernetes 集群的服务,也可以互不干扰。
3.1 创建Namespace
通过YAML创建不同的命名空间,可参考以下方式创建不同命名空间
# namespace-development.yaml
apiVersion: v1
kind: Namespace
metadata:
name: development
使用kubectl create命令完成命名空间的创建
kubectl create -f namespace-development.yaml
3.2 定义Context
命名空间创建之后,可以给命名空间定义Context,即运行环境。运行环境属于某个特定的命名空间。
通过 kubectl config set-context命令定义Context,并将其置于已经创建好的命名空间
kubectl config set-cluster kubernetes-cluster --server=http://192.168.1.128:8080
# 给3.1定义的namespace设置context
kubectl config set-context ctx-dev --namespace=development --cluster=kubernetes-cluster --user=dev
# 通过 kubectl config view 命令查看
kubectl config view
通过 kubectl config 命令在${HOME}/.kube 目录下生成一个名为config 的文件,内容即为 kubectl config view 显示的内容,也可以手动修改该内容来设置Context
3.3 设置工作组在特定Context中工作
可以通过kubectl config use-context <context_name> 命令设置当前运行环境。
# 将当前运行环境设置为ctx-dev,设置之后所有的操作都将在 development命名空间中完成
kubectl config use-context ctx-dev
四、 Kubernetes 资源管理
kubernetes 集群里的节点提供的资源主要是计算资源,计算资源是可计量的能被申请、分配和使用的基础资源,这使之区别于api资源。计算资源主要包括CPU、GPU和Memory。GPU暂不考虑。
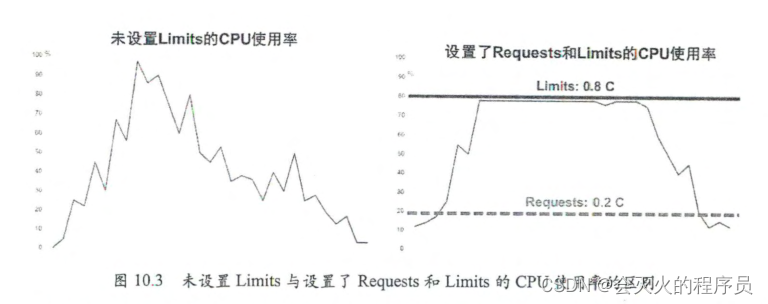
默认情况下定义pod时没有限制所占的cpu和内存,这样当集群计算资源不是很充足时,比如某个Pod负载突然加大,就会使某个节点的资源严重不足。为了防止系统挂掉,节点会杀掉某些用户进程来释放资源。若操作系统崩溃,则每个pod都可能成为牺牲品。
Kubernetes 有一套完备的资源配额限制及应对的Pod 服务等级机制。
- 可以全面限制一个应用及其中Pod所能占用的资源配额,具体包括三种方式
- 定义每个pod上资源配额相关的参数,比如CPU/Memory Request/Limit
- 自动为每个没有定义资源配额的Pod添加资源配额模板
- 从总量上限制一个租户(应用)所能使用的资源配额的 ResourceQuota
- 允许集群的资源被超额分配,以提高集群的资源利用率,同时允许用户根据业务的优先级,为 不同的Pod定义响应的服务保障等级(QoS)。可以将QoS理解为“活命优先级”,当系统资源不足时,低等级的Pod会被操作系统自我清理,以确保高等级Pod的稳定运行。
CPU与Memory是一个动态的量,是一个范围,跟它的负载有关。通过以下四个参数进行设置
- spec.container[].resources.requests.cpu: 容器初始要求的CPU数量
- spec.container[].resources.limit.memory: 容器所能使用的最大CPU数量
- spec.container[].resources.requests.memory: 容器初始要求的内存数量
- spec.container[].resources.limit.memory: 容器所能使用的最大内存数量
limit对应资源量的上限,即最多允许使用的上限资源量。
- CPU是可压缩的,进程无论如何都不可能上限
-
Memory是不可压缩的资源,如果设置的小了,则进程在业务繁忙时试图请求超过Limit 限制的Memory时会被操作系统“杀掉”。 因此,limit的设置需要结合进程的实际需求谨慎设置。
-
如果不设置CPU或者Memory的limit,Pod就会处于一种不稳定的状态。比如Pod的Memory Request 为1GB,Node A 空闲Memory为 1.2GB,Pod A 被调度在Node A 上。当Pod的负载增加,需要1.5GB时,Node A 剩余内存不足,所需资源超出了系统资源范畴,Pod A 在这种情况下会被Kubernetes “杀掉”
4.1 计算资源管理
4.1.1 详解 Requests 和 Limits 参数
对于CPU 和内存而言,== Pod 的Requests 或 Limits 指该 Pod 中所有容器的 Requests 或 Limits 的和==(没有设置则按0 或者集群配置的默认值来计算)
1. CPU
CPU的Requests 和 Limits 是通过CPU 数来度量的,资源值是绝对的。比如 0.1CPU 在单核或多核机器上是一样的,都严格等于 0.1 CPU core。
2. Memory
内存的Requests 和 Limits 计量单位是字节数。使用整数或者定点整数加上国际单位制来表示内存值。国际单位制包括十进制 E、P、T、G、M、K、m,二进制包括 Ei、Pi、Ti、Gi、Mi、Ki。KiB与MiB是二进制表示字节单位,KB、MB是十进制字节单位。
Kubernetes的计算资源单位是大小写敏感的
4.1.2 基于Requests 和Limit 的Pod 调度机制
每个节点都有一个用于Pod 运行的最大容量值,调度器在调度时,首先保证调度后该节点上所有的Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大值。
4.1.3 Requests 和 Limits 的背后机制
Kubelet在启动某个容器时,会将容器的Requests和Limits值转化为响应的容器启动参数给容器执行器,下面以docker为例。
1.spec.container[].resources.requests.cpu
将此值转化为core数(比如分配100m 转化为 0.1) ,然后再 乘以1024,再将这个结果作为–cpu-shares参数的值传递给 docker run 命令。
在docker中,–cpu-shares 是一个相对权重值,决定了在资源竞争时docker分配给容器的资源比例。比如两个容器的CPU Requests 分别设置为1 和 2 ,那么启动参数 --cpu-shares 值分别为1024 和 2048, 在主机CPU资源竞争时,会尝试按照 1:2 的配比将 CPU 分配个两个容器。
对Kubernetes来说这个参数是绝对值,用于调度和管理,对docker而言是相对值,主要用于设置资源分配比例。
2.pec.container[].resources.limit.memory
此值会被转化为 millicor 数(比如配置的1 会被转化为1000,100m被转化为100),将此值乘以100000,再除以1000,然后将结果值作为–cpu-quota参数传给 docker run命令。
docker run 命令另一个参数 –cpu-period 默认设为100000,表示docker重新计量和分配CPU的使用时间间隔为1000000us(100 ms)
–cpu-quota 和 --cpu-period 共同配合完成CPU限制。比如CPU Limits为 0.1,则计算最后 --cpu-quota值为 0.1 * 1000 * 100000 / 1000 = 100000; --cpu-period 值为100000。 表示docker 在 100ms内最多给该容器分配 10ms × core 的计算资源用量。 10 / 100 = 0.1,结果与kubernetes 配置的意义一致。
从kubernetes 1.2版本开始,kubelet默认启动参数–cpu-cfs-quota值为true,表示kubelet强制要求所有Pod都必须配置Limits
3.spec.container[].resources.requests.memory
只作为kubernetes 管理和调度的依据,不会传参给docker
4.spec.container[].resources.limit.memory
此值直接转换为Bytes 整数,值作为 --memory 参数传递给docker run 命令。
如果容器运行过程中内存超出Limits值,则可能被“杀死”。
4.1.4 计算资源使用监控情况
Pod 的资源用量会被作为Pod的状态信息上报给master。如果配置了Heapster来监控集群性能,可以从Heapster中查看Pod的资源用量信息。
4.1.5 计算资源常见问题分析
-
Pod状态为Pending,错误信息为FailedSheduling
调度器找不到合适的Node,Pod一致处于为调度状态。可以通过以下方式查看时间的信息
# fronted为pod的名字
kubectl describe pod fronted | grep -A 3 Events
如果出现 Failed for reason PodExceedsFreeCPU and posssibly others 的错误,可以采用以下解决方法:
- 添加更多的节点到集群中
- 停止不必要的Pod,释放资源
- 检查Pod配置,错误的配置可能导致Pod永远无法被调度执行。比如Requests 值超过了节点上限。
# 可以通过以下命令查看计算资源容量和已经使用容量
kubectl describe nodes k8s-node-1
# Capacity 表示资源容量上限
# Allocated Resources 表示已分配资源量
- 容器被强制种植(Terminated)
如果容器使用的资源超过了它配置的Limits,就可能被强制终止,可以使用以下命令确认容器是否因为这个原因被终止:
kubectl describe pod simmemleak-hra99
# 可以在kubectl get pod 命令时添加 -o go-template==... 格式来读取已终止容器之前的状态信息
kubectl get po -o go-template='{{range.status.containerStatuses}}{{"Container Name:"}}{{.name}}{{"\r\n:astState: "}}{{.lastState}}{{end}}' simmemleak-hra99
# OOM Killed 表示内存溢出(Out of Memory)
4.1.6 对大内存页(Huge Page)资源的支持
计算机发展早期,程序员直接对内存物理地址编程,自己管理内存,所以很容易内存溢出导致操作系统崩溃。后来将硬件和软件(操作系统)结合,推出虚拟地址和内存页概念,以及CPU的逻辑内存地址与物理内存(条)地址的映射关系。
现在操作系统中,内存以Page(页或者称为Block)为单位进行管理,不以字节为单位。典型Page大小为4KB,申请1MB内存,需要分配256个Page,1GB对应26万多个Page。
为了实现快速内存寻址,CPU内部以硬件方式实现了一个高性能的内存地址映射缓存表,来保存逻辑内存地址与物理内存的对应关系。TLB的条目有限,若目标地址不在TLB的缓存中或缓存记录失效,需要切换到低速的以软件方式实现的内存地址映射表进行寻址,将大大降低CPU运算速度。提高TLB效率的最佳办法就是将内存页增加,比如4KB改为2MB,一个进程的内存页减少,TLB的缓存命中率就会增加。
Linux操作系统使用Huge Page文件系统hugetlbfs支持巨页,可以设置Huge Page大小,比如1GB甚至2.5GB(需要硬件和操作系统支持),然后设置多少物理内存用于分配Huge Page,这样就设置了一些预先分配好的Huge Page。
# 可以将hugetlbfs文件系统挂载到/mnt/huge目录下
mkdir /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
可以将Huge Page理解为一种特殊的计算资源:拥有大内存页的资源。拥有Huge Page 资源的Node与拥有GPU资源的Node一样,属于一种新的可调度资源节点(Schedulable Resource Node),kubelet进程报告自身Huge Page资源信息到Master供集群调度。kubernetes 1.14对Linux Huge Page支持正式更新为GA稳定版本。
需要Huge Page 资源的Pod 只要给出相关Huge Page 的生命,就可以被正确调度到匹配的Node上
apiVersion: V1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- image: fedora:latest
command:
- sleep
......
volumeMounts:
- mountedPath: /hugepages
name: hugepage
resources:
limits:
hugeopages-2Mi: 100Mi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage
emptyDir:
# 需要更大的Huge,可以更改声明 medium: HugePages-<size>,如 HugePages-1Gi
medium: HugePages
对Huge Page 定义有以下几个关键点
- Huge Page需要被映射到Pod 的文件系统中
- Huge Page 申请的 request必须与limit一致
- 目前版本(1.20)的Huge Page属于Pod级别资源,未来计划成为Container级别
- 存储卷emptyDir(挂载在/hugepages目录)的后台是由Huge Page 支持的,因此应用不能使用超过request 声明的内存大小。
4.2 资源配置范围管理(LimitRange)
kubernetes 提供 LimitRange机制对Pod 和容器的Requests 和Limits 配置做进一步限制,应用场景如下:
- 集群中每个节点有2GB内存,设置禁止Pod 申请超过2GB内存
- 两个不同命名空间,nsA 需要使用8GB,nsB需要使用512MB,为每个命名空间设置不同的限制
- 每个Pod都设置为必须至少使用集群平均资源值(CPU和内存)的20%,来保证集群提供更好的资源一致性调度,从而减少资源浪费
4.3 资源服务质量管理(Resource Qos)
4.4 ResourceQuota 和 LimitRange 实践
4.5 资源配额管理( Resource Quota)
4.6 Pod 中多个容器共享进程命名空间
4.7 PID 资源管理
4.8 节点的CPU 管理策略
4.9 拓扑管理器
五、 资源紧缺时的Pod驱逐机制
5.1 驱逐时机
5.2 驱逐阈值
5.3 节点状态
5.4 节点状态的振荡
5.5 回收Node级别的资源
5.6 驱逐用户的Pod
5.7 资源最少回收量
5.8 节点资源紧缺情况下的系统行为
5.9 可调度的资源和驱逐策略实践
5.10 现阶段问题
六、 Pod Disruption Budget(主动驱逐保护)
七、 Kubernetes 集群监控
7.1 使用 Metrics Server 监控Node 和Pod 的CPU 和内存使用数据
7.2 Prometheus + Granfana 集群性能监控平台搭建
八、 Kubernetes 集群日志管理
8.1 容器应用和系统组件输出日志的各种场景
8.2 Fluentd + Elasticsearch + Kibana 日志系统部署
8.3 部署日志采集 sidecar 工具采集容器日志
九、 Kubernetes 的审计机制
十、 使用Web UI (Dashboard) 管理集群
十一、 Helm: Kubernetes 应用包管理工具
11.1 Helm 的整体架构
11.2 Helm 版本说明
11.3 Helm 的安装
11.4 Helm 的使用
11.5 Chart 说明
11.6 搭建私有Chart仓库