一、什么是预取
预取是指将内存中的指令和数据提前存放到cache(L1、L2、L3)中,从而加快处理器执行速度。
Cache预取可以通过硬件或者软件实现,也就是分为硬件预取和软件预取两类。
- 硬件预取,是通过处理器中专门的硬件来实现的,该硬件监控正在执行程序中请求的指令或数据,识别下一个程序需要的流然后预取到处理器中。
- 软件预取,是通过编译器分析代码然后在程序编译的过程中插入prefetch。这样在执行过程中在指定位置就会进行预取的动作。
本文讨论的预取指软件预取。
二、使用_mm_prefetch预取
win10下,vs2017直接#include <Windows.h>就可以使用此函数了。
函数原型如下:
void _mm_prefetch(char const *p, int sel);
从地址p处预取大小为cache line的一块数据至缓存。
参数sel指示预取方式:
- _MM_HINT_T0,预取数据到所有缓存
- _MM_HINT_T1,预取到L2,L3缓存,但是不到L1缓存
- _MM_HINT_T2,仅预取数据到L3缓存
- _MM_HINT_NTA,预取数据到非临时缓冲结构中,可以最小化对缓存的污染。
如果在CPU操作数据之前,我们就已经将数据主动加载到缓存中,那么就减少了由于缓存不命中,需要从内存取数的情况,这样就可以加速操作,获得性能上提升。使用主动缓存技术来优化内存拷贝。
我们编写一段测试代码,用来测试数据预取与不预取2种情况下的区别。
prefetchTest.cpp
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <Windows.h>
#include <emmintrin.h>
#define INT_COUNT (5*1024*1024)
inline int calculate(int input)
{
int val = (input % 99) * (input / 98);
val = val ? val : 1;
double n = sqrt(sqrt((double)(unsigned)input * 1.3));
double m = sqrt(sqrt((double)(unsigned)val * 0.9));
return (int)((double)input * (double)val * m / (n ? n : 1.1));
}
int run_withprefetch(const int *array, int size, int step, int prefetch)
{
int result = 0;
printf("run with prefetch(%d)...\n", prefetch);
for (int i = 0; i < step; i++)
{
for (int j = i; j < size; j += step)
{
int k = j + step * prefetch;
if (k < size)
{
_mm_prefetch((char*)&array[k], _MM_HINT_T0);
// _mm_clflush(&array[k]);
}
result += calculate(array[j]);
}
}
return result;
}
int run(const int *array, int size, int step)
{
int result = 0;
printf("run...\n");
for (int i = 0; i < step; i++)
{
for (int j = i; j < size; j += step)
{
result += calculate(array[j]);
}
}
return result;
}
int main()
{
int select;
scanf("%d", &select);
int* array = new int[INT_COUNT];
for (int i = 0; i < INT_COUNT; i++)
{
array[i] = i;
}
long t1 = GetTickCount();
int result;
if (select == 0)
{
result = run(array, INT_COUNT, 1024);
}
else
{
result = run_withprefetch(array, INT_COUNT, 1024, 1);
}
long t2 = GetTickCount();
std::cout << (t2 - t1) << "ms" << std::endl;
std::cout << "result:" << result << std::endl;
delete[] array;
}
编译执行,输入0表示执行不预取的计算逻辑,输出结果如下:
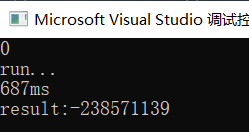
可以看到计算完毕消耗687ms。
重新执行,输入1表示执行预取计算逻辑,输出结果如下:
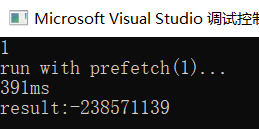
可以看到计算完毕消耗391ms,性能得到大幅提升。这就是数据预取的威力。
三、使用_mm_clflush清除cache line
win10下,vs2017直接#include <emmintrin.h>就可以使用此函数了。
函数原型如下:
void _mm_clflush(void const* p);
此函数可以手动清除p地址处cache line缓存(清除大小为line size)。
我们打开prefetchTest.cpp中“_mm_clflush(&array[k]);”代码的注释。
这样的话,就是先预取数据,然后立马反悔,清除cache line缓存,相当于是没有预取。
编译执行,输入1,输出结果如下:
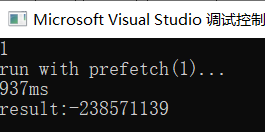
可以看到计算完毕消耗937ms。相比于不预取时的687ms,反而更加耗时了,可能是因为手动清除cache line比较影响性能吧。
四、总结
注 意,CPU对数据操作拥有绝对自由!使用预取指令只是按我们自己的想法对CPU的数据操作进行补充,有可能CPU当前并不需要我们加载到缓存的数据,这样,我们的预取指令可能会带来相反的结果,比如对于多任务系统,有可能我们冲掉了有用的缓存。不过,在多任务系统上,由于线程或进程的切换所花费的时间相对于预取操作来说太长了,所以可以忽略线程或进程切换对缓存预取的影响。
另外,数据预取只对那些内存读取是它瓶颈的程序才能起到很好的优化,毕竟只是加快了内存访问速度而已。那些对内存性能要求不高,对计算复杂度较高的程序,可能效果就不会那么明显。还有一些计算复杂度和内存性能要求都不高的程序,预取与不预取可能效果也不明显。
参考链接:
《CPU预取与性能简介》
《memory prefetch浅析》
《Intel 平台编程总结----缓存优化之数据预取》
《SSE中使用_mm_prefetch加速计算》
《clflush通过C函数使缓存行无效》
若对你有帮助,欢迎点赞、收藏、评论,你的支持就是我的最大动力!!!
同时,阿超为大家准备了丰富的学习资料,欢迎关注公众号“超哥学编程”,即可领取。
本文涉及工程代码,公众号回复:11PrefetchAndClflushTest,即可下载。
