在分类问题中,
交叉熵的本质就是【对数】似然函数的最大化
逻辑回归的损失函数的本质就是【对数】似然函数的最大化
最大似然估计讲解: https://www.jianshu.com/p/191c029ad369
参考统计学习方法笔记 P79
softmax
通过Softmax回归,将logistic的预测二分类的概率的问题推广到了n分类的概率的问题。通过公式
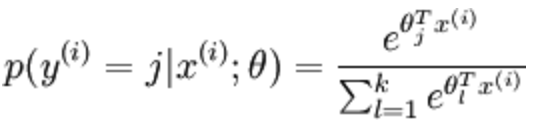
softmax损失函数-交叉熵
 (y代表我们的真实值,a代表我们softmax求出的值)
(y代表我们的真实值,a代表我们softmax求出的值)
举例十分类:对使用softmax进行mnist数据集的多分类任务时,我们使用交叉熵作为损失函数
![y_{1} = [0,1,0,0,0,0,0,0,0,0]](https://private.codecogs.com/gif.latex?y_%7B1%7D%20%3D%20%5B0%2C1%2C0%2C0%2C0%2C0%2C0%2C0%2C0%2C0%5D) (真实值为数字“1”,one-hot编码)
(真实值为数字“1”,one-hot编码)
![a_{1}=[0.2,0.7,0,0,0,0,0,0,0,0.1]](https://private.codecogs.com/gif.latex?a_%7B1%7D%3D%5B0.2%2C0.7%2C0%2C0%2C0%2C0%2C0%2C0%2C0%2C0.1%5D) (预测值是70%的概率是数字“1”,这个a值是由softmax得到的)
(预测值是70%的概率是数字“1”,这个a值是由softmax得到的)
求解Loss = -(0*ln0.2+1*ln0.7+0*ln0+0*ln0+...) 式1
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
逻辑回归模型
单分类逻辑回归模型:
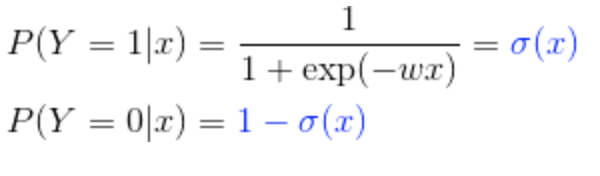
逻辑回归损失函数:
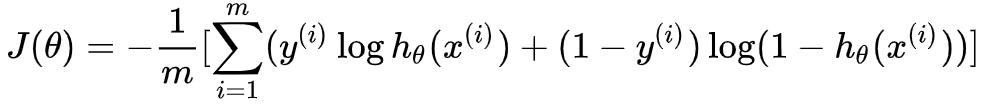
举例二分类:判断数字是0还是1(交叉熵计算)
![y_{1} =[1,0]](https://private.codecogs.com/gif.latex?y_%7B1%7D%20%3D%5B1%2C0%5D) (真实值为数字“0”,采用one-hot编码)
(真实值为数字“0”,采用one-hot编码)
![a_{1} = [0.9,0.1]](https://private.codecogs.com/gif.latex?a_%7B1%7D%20%3D%20%5B0.9%2C0.1%5D) (预测数字是“0”的概率是90%)
(预测数字是“0”的概率是90%)
Loss = -(1*ln0.9+0*ln0.1) 式2
举例二分类:判断数字是0还是1,且计算是0的概率为0.9(逻辑回归损失函数计算)
Loss = -(0*ln0.9+1*ln0.9) 式3
发现式2与式3一样,所以逻辑回归的损失函数与交叉熵一样
多分类逻辑回归模型:
设 Y ∈ {1,2,..K},则多项式逻辑斯蒂回归模型为:

统计学习方法
已知观测的数据属于二项逻辑斯蒂回归模型,求模型的参数

逻辑回归是一个判别模型,直接计算条件概率分布P(Y|X)
我们最终求的就是P(Y=1|X;theta) 即在给定X的条件下,Y是正例的概率
- P(Y=1|X;theta) = g(theta0 + theta1x1 + theta2x2 + ... +thetanxn)
- P(Y=0|X;theta) = 1 - P(Y=1|X;theta)
最大似然估计的使用场景:已知观测的数据属于某种模型,求模型的参数
计算模型(求参数)
- 使用最大似然估计,似然函数就是每个观测数据的概率密度函数的成绩
- 使用最大似然估计,引出最小化损失函数
- 最小化损失函数,引出梯度下降,求模型参数
吴恩达教学逻辑回归



