算分函数查询
相关性计算
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
[
{
"_score" : 17.850193,
"_source" : {
"name" : "虹桥如家酒店真不错",
}
},
{
"_score" : 12.259849,
"_source" : {
"name" : "外滩如家酒店真不错",
}
},
{
"_score" : 11.91091,
"_source" : {
"name" : "迪士尼如家酒店真不错",
}
}
]
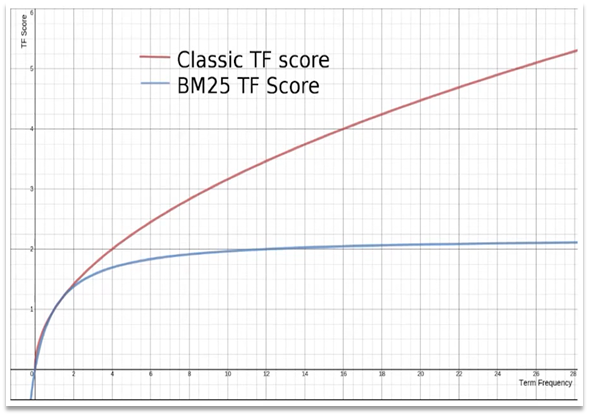
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

TF-IDF算法有一个缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
根据相关度打分是比较合理的需求,但合理的不一定是产品经理需要的。
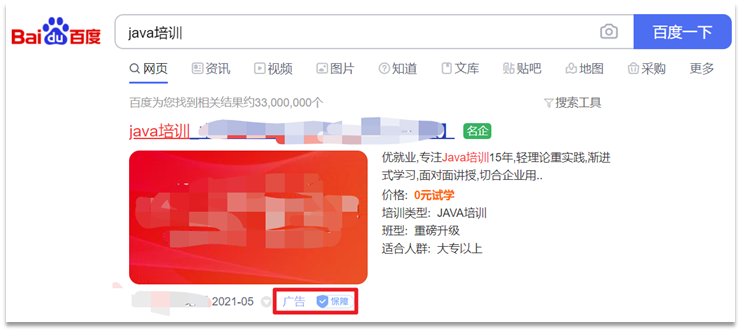
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。如图:
要想人为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
算分函数语法
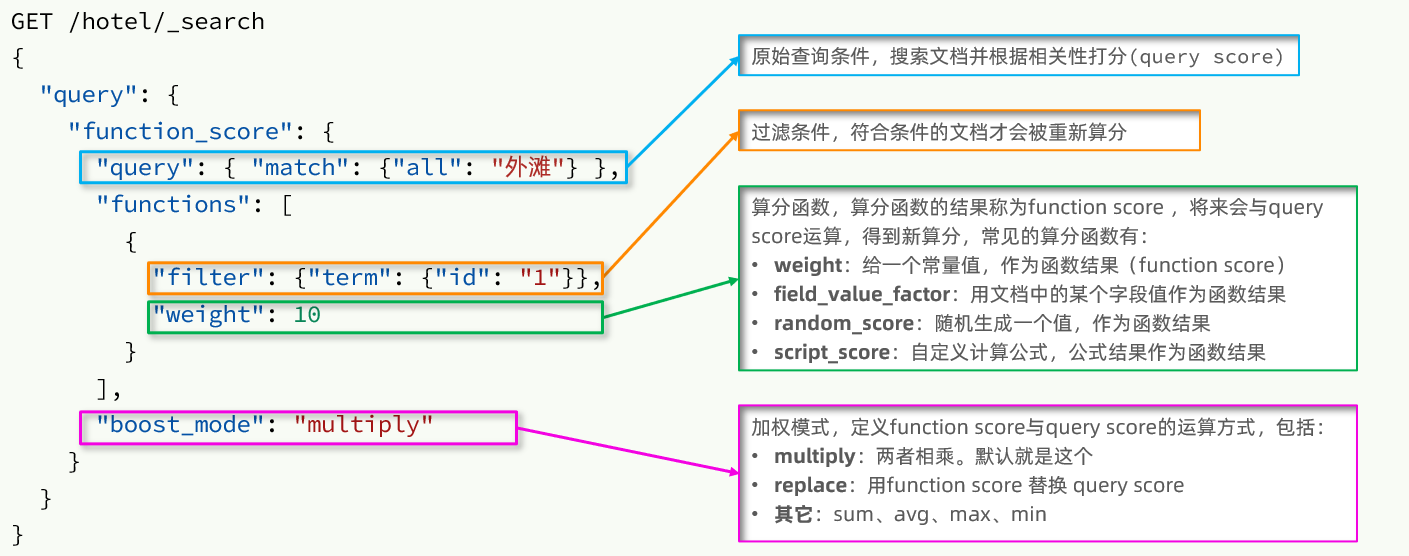
function score 查询中包含四部分内容:
-
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
-
根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
根据过滤条件,过滤出符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
算分函数示例
需求:给“如家”这个品牌的酒店排名靠前一些
翻译一下这个需求,转换为之前说的四个要点:
- 原始条件:不确定,可以任意变化
- 过滤条件:brand = “如家”
- 算分函数:可以简单粗暴,直接给固定的算分结果,weight
- 运算模式:比如求和
因此最终的DSL语句如下:
#不添加算法函数,原始检索。如家酒店的相关性得分并不高
GET /hotel/_search
{
"query": {
"match": {
"all": "北京酒店"
}
}
}
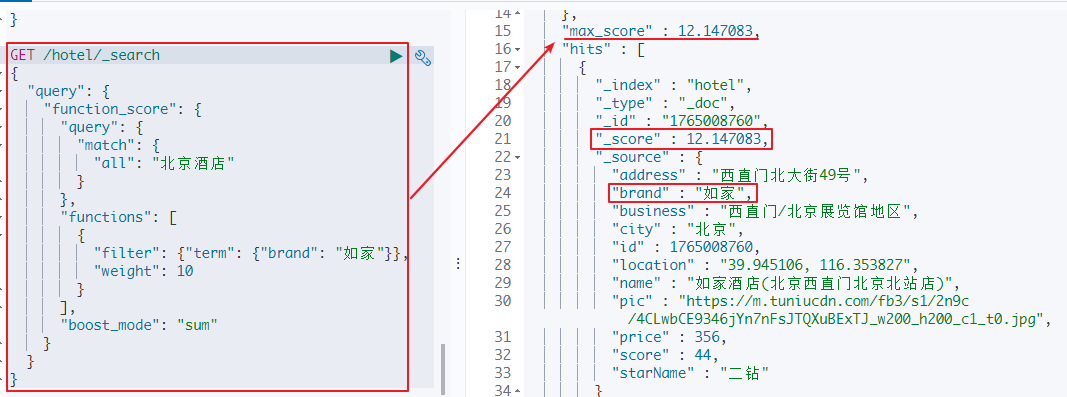
#使用算法函数,所有品牌为“如家”的酒店,在原始相关性得分基础上+10,最终相关性得分高了很多
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "北京酒店"
}
},
"functions": [
{
"filter": {"term": {"brand": "如家"}},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}
不添加算法函数,原始检索。如家酒店的相关性得分并不高
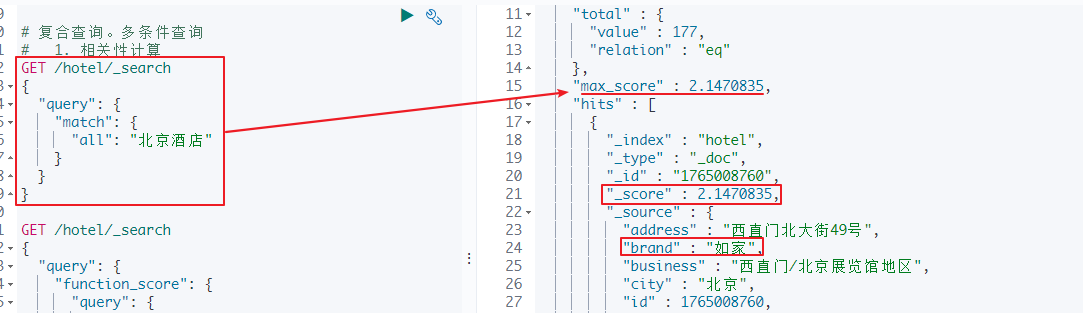
使用算法函数,所有品牌为“如家”的酒店,在原始相关性得分基础上+10,最终相关性得分高了很多
代码实例
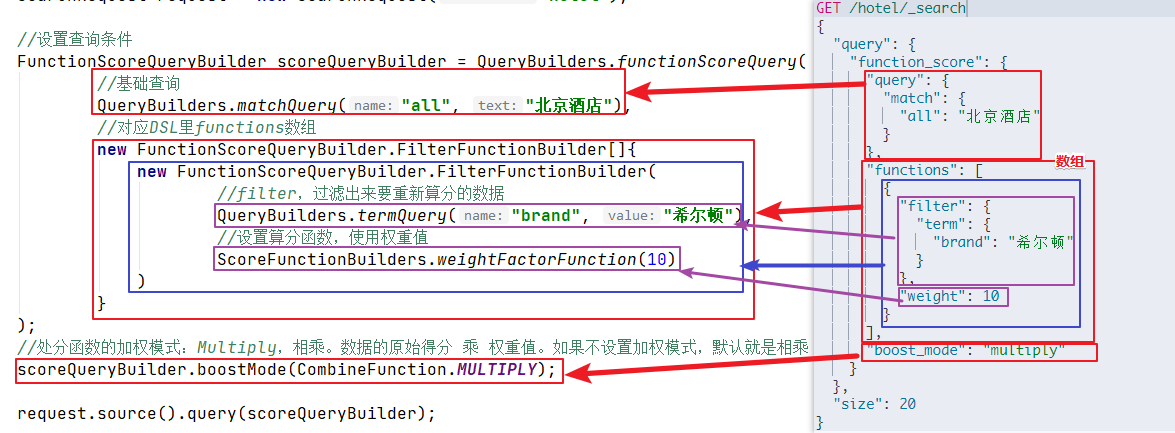
@Test
public void testFunctionScore() throws IOException {
SearchRequest request = new SearchRequest("hotel");
//设置查询条件
FunctionScoreQueryBuilder scoreQueryBuilder = QueryBuilders.functionScoreQuery(
//基础查询
QueryBuilders.matchQuery("all", "北京酒店"),
//对应DSL里functions数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//filter,过滤出来要重新算分的数据
QueryBuilders.termQuery("brand", "希尔顿"),
//设置算分函数,使用权重值
ScoreFunctionBuilders.weightFactorFunction(10)
)
}
);
//处分函数的加权模式:Multiply,相乘。数据的原始得分 乘 权重值。如果不设置加权模式,默认就是相乘
scoreQueryBuilder.boostMode(CombineFunction.MULTIPLY);
request.source().query(scoreQueryBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits result = response.getHits();
// 获取总数量
long total = result.getTotalHits().value;
System.out.println("总数量:" + total);
// 获取数据列表
SearchHit[] hits = result.getHits();
for (SearchHit hit : hits) {
//获取文档对象的原始数据
String docJson = hit.getSourceAsString();
HotelDoc doc = JSON.parseObject(docJson, HotelDoc.class);
System.out.println("查询得到的数据:" + doc);
System.out.println("匹配度得分:" + hit.getScore());
}
}