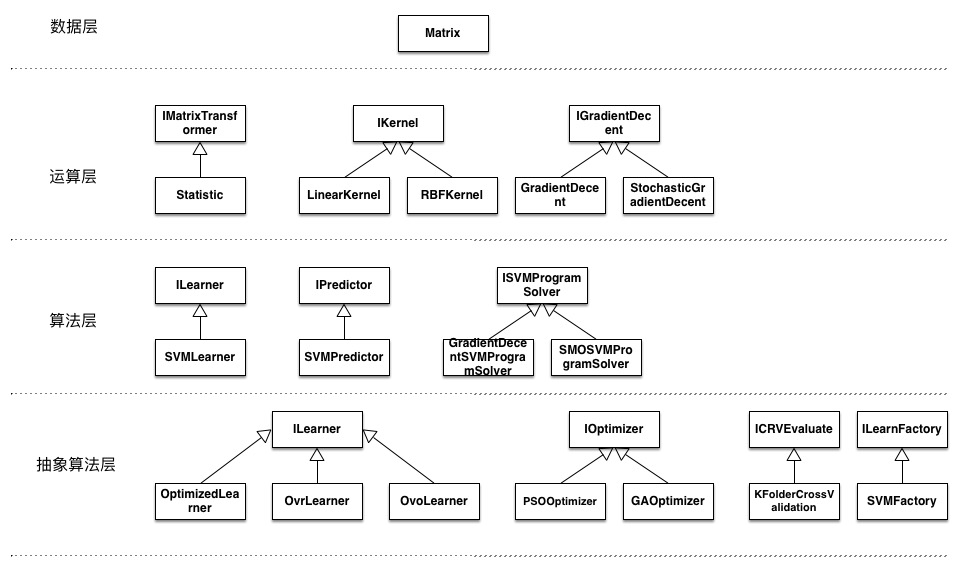
SVM实现
SVM在浅层学习时代是主流监督学习算法,在深度学习时代也往往作为最后一个预测层使用(说深度学习击败了SVM的纯属扯淡)。
SVM算法总体流程
本系列文章旨在讲解机器学习算法的工程实现方法,不在于推导数学原理。因此想深入了解原理的请移步去看《支持向量机通俗导论(理解SVM的三层境界)》:
http://www.cnblogs.com/v-July-v/archive/2012/06/01/2539022.html
对于急于求成的小伙伴,建议就看下面描述的基本过程,知其然,不必知其所以然。
按照上篇文章所规定的工程框架,所有操作尽量以矩阵为单元执行:
http://blog.csdn.net/jxt1234and2010/article/details/51926758
预测
SVM是一个监督学习算法,其训练时输入自变量矩阵X(N个m维向量)和因变量矩阵Y(这里要求Y中元素取值为两类之一:{A、B}),输出模型M。
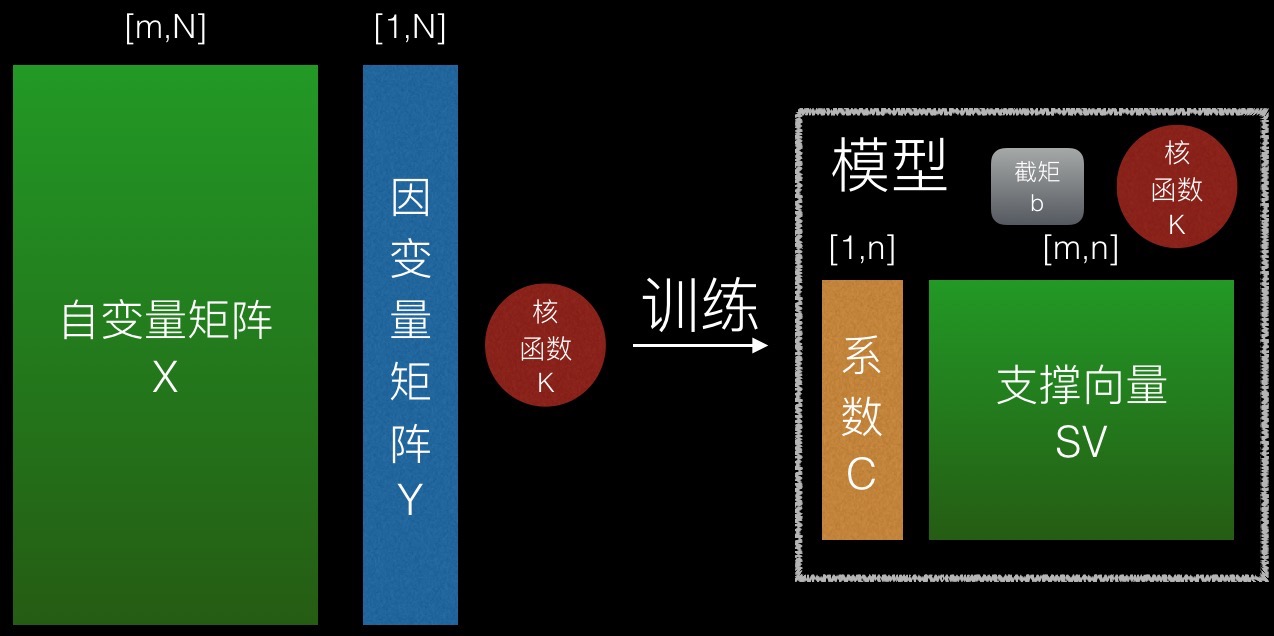
如图所示,一个SVM模型包含如下要素:
1、支撑向量集SV
一个n行m列的矩阵,表示n个m维向量。
支撑向量集是在训练过程中,挑选出自变量矩阵的有效行形成的。
2、系数C与截距b
系数矩阵为n行1列的矩阵,它与支撑向量集一一对应。
截距为一个常数。
3、核函数K
核函数为实现了如下接口的一个类
class IKernel
{
public:
virtual Matrix* vCompute(const Matrix* X1, const Matrix* X2) const = 0;
};
其中X1为 [m, n1]的矩阵,X2为[m, n2]的矩阵,输出结果为 [n2, n1] 的矩阵。
具体的核函数运算参考:
http://blog.csdn.net/xiaowei_cqu/article/details/35993729
预测时输入自变量矩阵X(待预测向量集)和模型M,输出预测值矩阵YP。
X为[m,p]的矩阵,表示p个待预测的m维向量。
YP为[1,p]的矩阵,表示p个预测值。
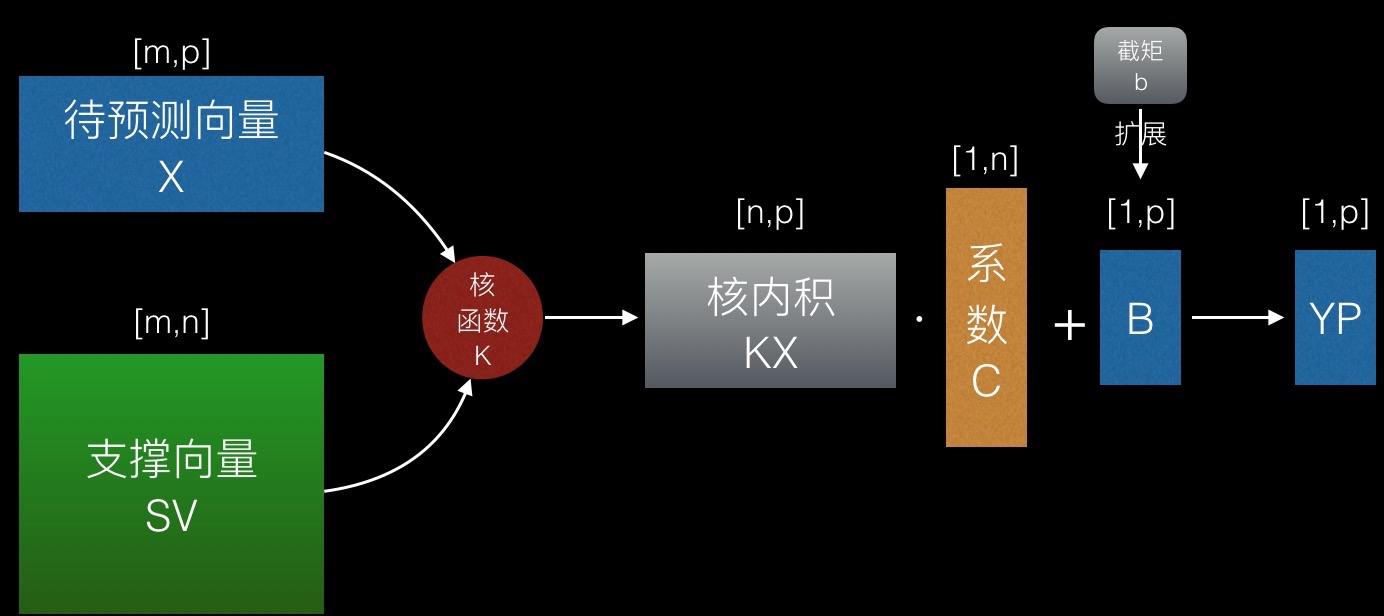
第一步,由核函数算出SV和X的核内积矩阵KX。KX(i, j)即第i个支撑向量和第j个待预测向量的核内积。
第二步,用KX和对应的系数矩阵相乘,加上截距,得到YP。
预值出来的YP只是一个实数,不表示具体类别,使用时需要对每个值作类别转化,大于0转为类别A,小于0转为类别B。
预测过程可以用一个公式简单表示:
YP=K((M.SV), X)∙(M.C)+B
训练过程
在SVM模型中,核函数是事先指定的,支撑向量是从自变量向量集中抽取的,因此训练过程主要就是计算系数矩阵和截矩。
因变量矩阵Y假定其元素只有A、B两个取值
训练之前先要预处理,将因变量矩阵Y中A转为1,B转为-1。
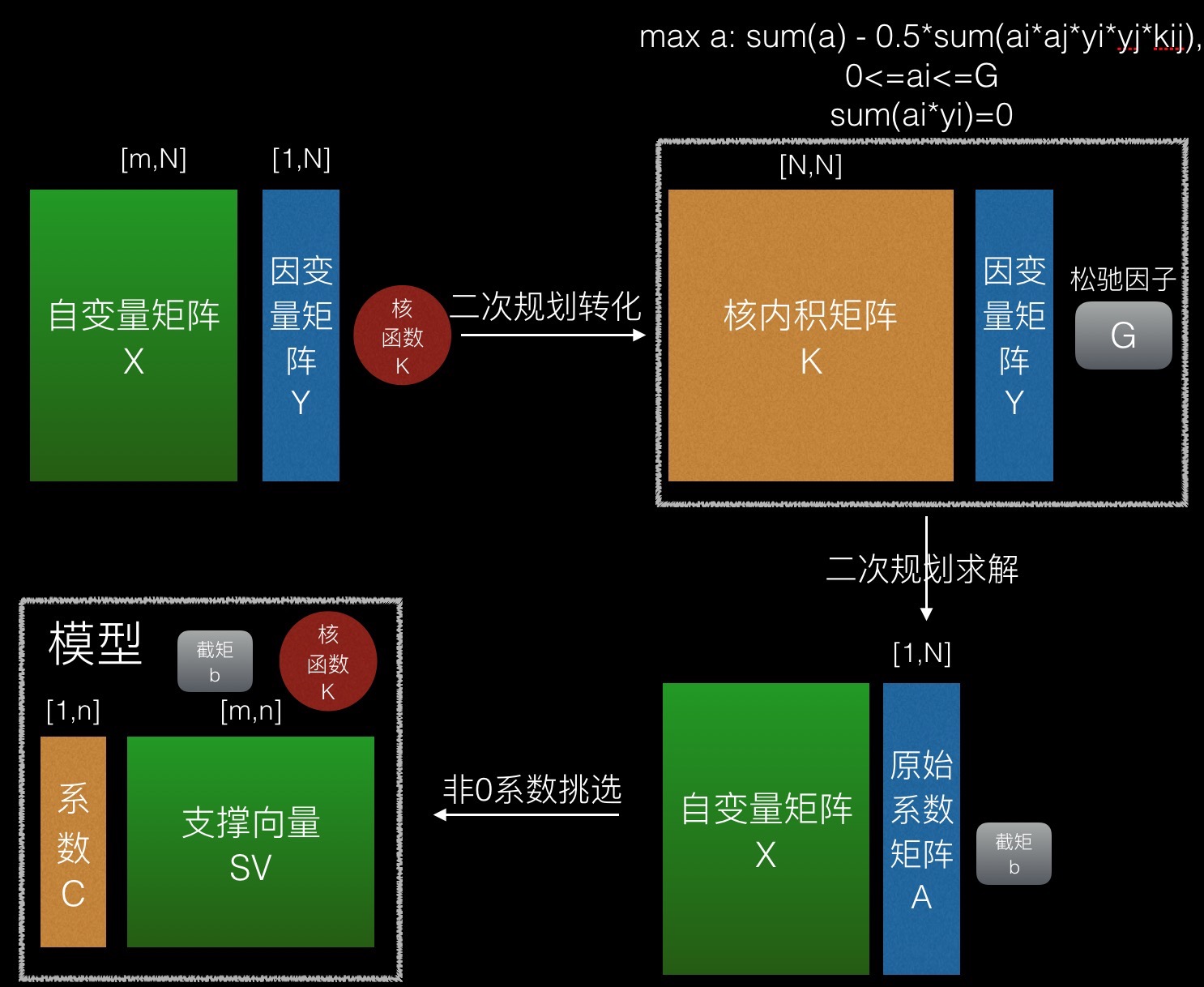
如图所示,SVM模型的创建分三步:
1、创建二次规划(主要是计算核内积矩阵)
2、解二次规划,得到截矩b和原始系数矩阵A,原始系数矩阵为[1,N]的矩阵,其系数值与自变量矩阵中的向量一一对应。
3、把原始系数矩阵中非零系数及对应的自变量矩阵中的向量挑选出来,形成系数矩阵C及其对应的支撑向量集SV。
第3步只是一个简单的挑选过程,因此经常被一带而过,往往只有自己去实现,才能记得。
熟悉SVM的朋友可以看出,按上面这个流程这个方式写出来的SVM,并没有交叉验证、核函数选择及参数调优及多分类的功能。主要是考虑到这些特性并非SVM专属,应当在算法抽象层实现,以便给其他监督学习算法共享。
基础算法实现及相应的类
训练类
SVM是一种监督学习算法,对应的训练类定义为SVMLearner
class SVMLearner
{
public:
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const;
private:
double mG;//对应松驰因子G
IKernel* mK;//核函数
ISVMProgramSolver* mSolver;//二次规划求解器
};
二次规划生成
规划描述
mina12∑i∑jyiyjkijaiaj−∑iai
0<=ai<=G,∑iaiyi=0
ai
表示系数矩阵A的第i行的值
yi
表示因变量矩阵Y的第i行的值
kij
表示核内积矩阵第i行第j列的值,即第i个自变量向量和第j个自变量向量的核内积。
G为松驰因子,事先设定。
截距b值由如下公式推断:
b=∑iyiaikik−yk,ak>0
至于,为什么是这个二次规划公式,请移步相关的原理文章看推导过程。
看完上面的结构图,我们定义如下的结构体去描述SVM创建的二次规划:
struct SVMProblem
{
Matrix* K;
Matrix* Y;
double G;
/*解的描述:系数矩阵及截矩*/
struct Answer{
Matrix* C;
double b;
};
};
这里并不定义一个通用的二次规划问题结构体,主要考虑到仅SVM算法涉及二次规划的求解,不是太有必要基于普通二次规划求解。
这个结构体中,松驰变量G需要事先设定,Y直接来源于因变量,因此,创建二次规划的过程就等同于核函数运算的过程,即求出核内积矩阵:
K=K(X,X)
核函数运算
构造二次规划问题过程中,最核心的是核函数运算,即求出所有
kij
。
核函数本身是向量间的一种内积,但为了后续优化方便,我们将核函数的接口定义为对矩阵的运算。
考虑到核函数有多种,定义相应的类:
比如线性核函数:
class LinearKernel:public IKernel
{
public:
virtual Matrix* vCompute(const Matrix* X1, const Matrix* X2) const;
};
径向基核函数:
class RBFKernel:public IKernel
{
public:
virtual Matrix* vCompute(const Matrix* X1, const Matrix* X2) const;
private:
double mGamma;
};
注意到核内积矩阵K是[N,N]的规模,当训练数据量很大时,这个矩阵是非常大的。
核函数计算还是相当好并行化实现的,不过对于不同的核函数,似乎没有一个统一的方案,只好一个个来优化了。
二次规划求解
SVM的二次规划的求解是一种凸优化问题,能求出导数表达式,因此可以用通用的优化算法梯度下降法求解。此外,由于它本身的特殊性,可以用一种更快的优化方法SMO算法。
考虑到有多种解法,在这定义一个接口:
class ISVMProgramSolver {
public:
virtual SVMProblem::Answer* vSolve(Problem*) const = 0;
};
梯度下降
定义梯度下降法解SVMProblem的类为
GradientDecentSVMProgramSolver
class GradientDecentSVMProgramSolver:public ISVMProgramSolver {
public:
virtual SVMProblem::Answer* vSolve(Problem*) const;
};
梯度下降是一种通用性质的优化算法了,有必要定义梯度下降这一优化算法抽象出来。
梯度下降简单来说就是一个公式:
θ=θ−α∇θJ
θ
为待确定的系数向量,
α
为一个系数,
∇θJ
为目标函数对系数向量的偏导。
求偏导这种工作涉及符号代数,需要加公式解析和公式树运算的模块,本工程就不做这个事情了,而是直接将梯度函数定义为一个接口,每个上层算法自行实现:
class DerivativeFunction {
public:
/*输入:初始的系数向量 coefficient,用于更新系数的样本集矩阵X
输出:系数梯度向量,与 coefficient 同长
*/
virtual Matrix* vCompute(Matrix* coefficient, Matrix* X) const = 0;
};
梯度下降算法定义为如下的接口:
其中系数矩阵 coefficient 既是输入(需要提供初始值),也是输出,X为样本集,alpha为更新速度,iteration为最高迭代次数,DerivativeFunction为梯度计算函数。
class IGradientDecent {
public:
virtual void vOptimize(Matrix* coefficient, Matrix* X, const DerivativeFunction* delta, double alpha, int iteration) const = 0;
};
其中可分两种实现方式:
/*普通梯度下降,每次用全部样本来更新梯度*/
class GradientDecent :public IGradientDecent{
public:
virtual void vOptimize(Matrix* coefficient, Matrix* X, const DerivativeFunction* delta, double alpha, int iteration) const;
};
/*随机梯度下降,每次随机抽取样本来更新梯度*/
class StochasticGradientDecent : public IGradientDecent{
public:
virtual void vOptimize(Matrix* coefficient, Matrix* X, const DerivativeFunction* delta, double alpha, int iteration) const;
};
在GradientDecentSVMProgramSolver的实现中,
定义一个 DerivativeFunction,初始化一个全为零的coefficient矩阵,然后由通用的梯度下降算法去确定系数即可。
SMO
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html
SMO是一个相对专一的优化算法,因此直接写为一个继承ISVMProgramSolver的类。
class SMOSVMProgramSolver:public ISVMProgramSolver {
public:
virtual SVMProblem::Answer* vSolve(Problem*) const;
};
预测类
定义SVM的预测类如下:
/*预测模型*/
class SVMPredictor:public IPredictor
{
public:
//获得类别值
virtual Matrix* vPredict(Matrix* X) const;
//获得各个类别的概率([0,1]区间)
virtual Matrix* vPredictProb(Matrix* X) const;
//获得各个类型的值
virtual Matrix* vGetValues() const;
//保存为树结点(后续可将树结点存成json)
virtual Node* vDump() const;
private:
double mTypeA;//A类别的值
double mTypeB;//B类别的值
std::string mKernelDescription;//核函数描述,根据此字段可以重建核函数
IKernel* mKernel;//核函数
Matrix* mSV;//支持向量
double mB;//截矩
};
抽象特性实现
讲SVM的文章,实现SVM的代码都把这些特性内嵌到SVM算法本身去了。但这个原应在一个更高的抽象层实现。现在,让我们仅仅将SVM视为一个普通的监督学习算法,实现这些特性。
交叉验证
关于交叉验证的说明参考如下文章:
http://blog.csdn.net/xywlpo/article/details/6531128
在工程中,交叉验证是一个监督学习的评价类:
/*CRV Means Cross Validate*/
class ICRVEvaluate {
public:
//ICompare为对比函数,依据预测值和真实值的差距评分,一般取为n阶矩离
class ICompare {
public:
virtual double vCompare(Matrix* Y, Matrix* YP) const;
};
virtual double vEvaluate(ILearner* learner, Matrix* X, Matrix* Y, ICompare* compare) const = 0;
};
交叉验证有若干种方式,但统一的流程都是拆分——训练——预测与结果累加,以k-folder cross-validation为例:
class KFolderCrossValidation : public ICRVEvaluate {
public:
virtual double vEvaluate(ILearner* learner, Matrix* X, Matrix* Y, ICompare* compare) const {
double sumValue = 0.0;
for (int i=0; i<mK; ++i) {
Matrix* trainSetX = splitForTrain(X, i);
Matrix* trainSetY = splitForTrain(X, i);
IPredictor* p = learner->vLearn(subSetX, subSet, Y);
delete trainSetX;
delete trainSetY;
Matrix* testSetX = splitForTest(X, i);
Matrix* predictY = p->vPredict(testSetX);
delete testSetX;
delete p;
Matrix* testSetY = splitForTest(Y, i);
sumValue += compare->vCompare(predictY, testSetY);
delete testSetY;
delete predictY;
}
return sumValue;
}
private:
int mK;//交叉验证的划分数,一般取10
};
选择了交叉验证函数之后,可以此去判定一个监督学习算法的好坏,这个就是后续参数调优中的目标函数。
核函数选择与参数调优
SVM的核函数选择与参数调优无法基于数理统计找到适合的优化方法,只能使用启发式优化算法或穷举。这种优化算法理应独自为一通用模块:
定义一个通用的启发式优化算法:
class IOptimizer{
public:
/*评价函数*/
class IEvaluate {
public:
//parameters 为[n,1]的矩阵,即一个向量,其中每个数都为[0,1]的实数
virtual double vEvaluate(Matrix* parameters) const = 0;
};
/*parameters既是输入也是输出,evaluate为评价函数*/
virtual void vOptimize(Matrix* parameters, IEvaluate* evaluate) const = 0;
};
定义一个SVMFactory,基于parameters构建SVM训练器,此处类似于抽象工厂的设计:
class ILearnerFactory{
public:
virtual ILearner* vCreate(Matrix* parameters) const = 0;
};
class SVMFactory : public ILearnerFactory{
public:
virtual ILearner* vCreate(Matrix* parameters) const;
};
这个构建过程将挑选SVMLearner中的Kernel函数和二次规划求解函数并确定G值。
针对监督学习算法的评价函数便可如此编写:
/*评价函数*/
class LearnerEvaluate:public IOptimizer::IEvaluate {
public:
virtual double vEvaluate(Matrix* parameters) const {
ILearner* l = mFactory->vCreate(parameters);
double p = mEvaluate->vEvaluate(l, mX, mY, mCompare);
delete l;
return p;
}
private:
ILearnerFactory* mFactory;
ICRVEvaluate* mEvaluate;
ICRVEvaluate::ICompare* mCompare;
Matrix* mX;
Matrix* mY;
};
实际的优化算法可使用遗传算法、粒子群等。
//遗传算法
class GAOptimizer : public IOptimizer{
public:
virtual void vOptimize(Matrix* parameters, IEvaluate* evaluate) const;
};
//粒子群算法
class PSOOptimizer : public IOptimizer{
public:
virtual void vOptimize(Matrix* parameters, IEvaluate* evaluate) const;
};
定义引入参数调优的监督学习算法类:
class OptimizedLearner:public ILearner {
public:
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const;
private:
ILearnerFactory* mFactory;
IOptimizer* mOptimizer;
int mParameterSize;
};
该类将先用参数寻优算法构造一个实际的训练器ILearner,再用该训练器得到模型。
多分类实现
SVM原理上只能进行二分类,为了支持多分类,需要将其扩展,如何扩展参考这篇文章:
http://www.cnblogs.com/CheeseZH/p/5265959.html
如上面的文章所述,有多种扩展方式,我们定义如下几个装饰类:
/*一对多法*/
class OVRLearner : public ILearner{
public:
OVRLearner(ILearner* l);
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const;
private:
ILearner* mOrigin;
};
/*一对一法*/
class OVOLearner : public ILearner{
public:
OVOLearner(ILearner* l);
virtual IPredictor* vLearn(Matrix* X, Matrix* Y) const;
private:
ILearner* mOrigin;
};
创建多分类器时,基于二分类器包裹一下即可,比如:
ILearner* origin = factory->vCreate(parameters);
ILearner* l = new OVOLearner(origin);
抽象层的各种Learner对应地需要定义各自的Predictor,不详述。
代码框架
比起上一节的决策树,SVM的代码框架明显复杂了许多,主要其中很大一部分是可复用的,独立出来以便其他算法调用: