Python
Java
PHP
IOS
Android
Nodejs
JavaScript
Html5
Windows
Ubuntu
Linux
hadoop学习笔记之分布式计算框架
2023-11-15
分布式计算框架:移动计算而不是移动数据,移动计算就是把你写好的计算
程序拷贝到不同的计算节点上运行
MapReduce适合做离线计算
Storm适合做流失计算
Spark适合做内存计算框架
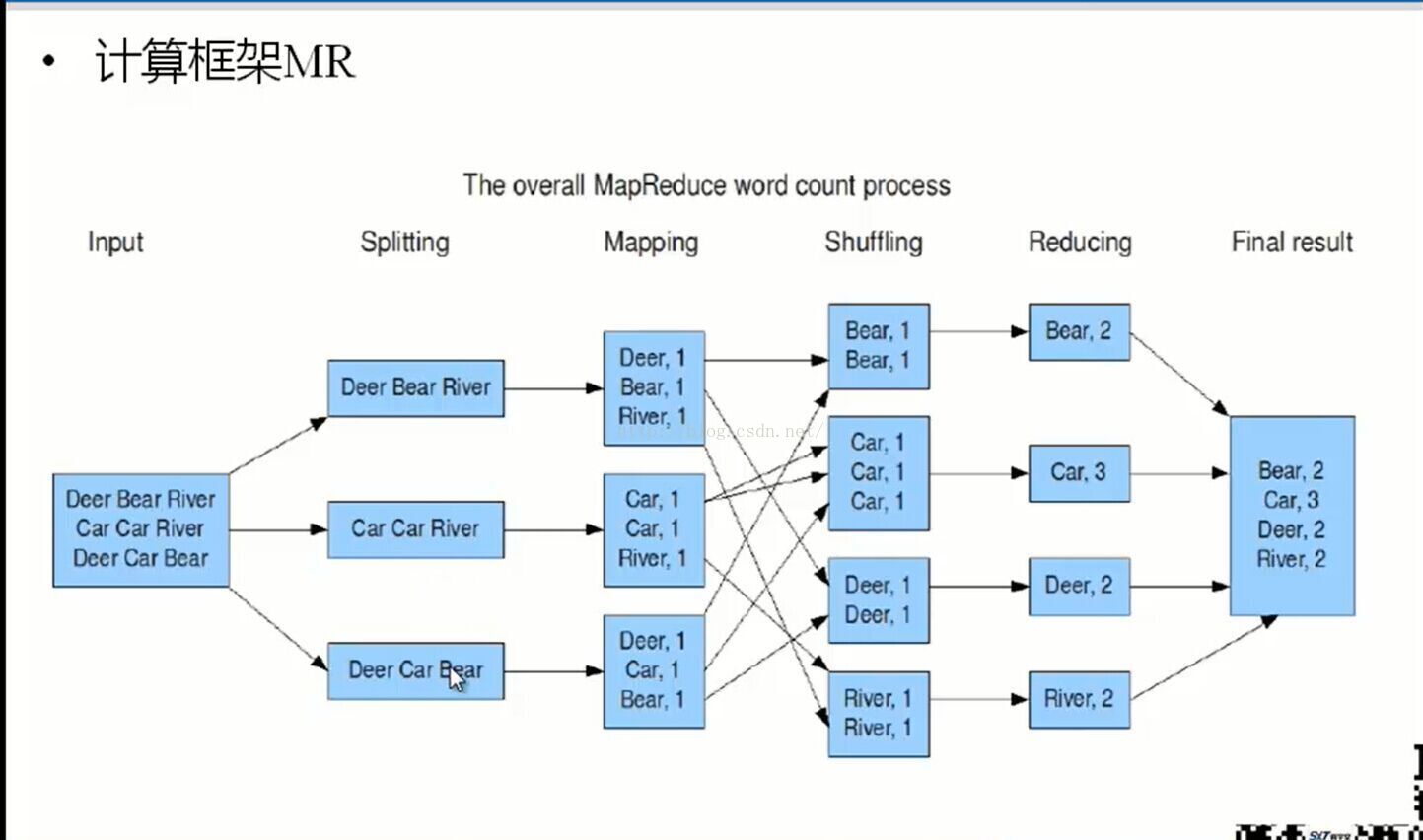
从HDFS上存储的数据作为我们MapReduce的一个输入,首先把一个文件切成片,
然后map计算 接着shuffle,接着reduce,最终把结果存储在HDFS文件系统上面。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
大数据
Hadoop
hadoop学习笔记之分布式计算框架 的相关文章
如何将Hive数据表迁移到MySql?
我想知道如何将日期从 Hive 转移到 MySQL 我看过有关如何将 Hive 数据移动到 Amazon DynamoDB 的示例 但没有看到有关如何将 Hive 数据移动到 MySQL 等 RDBMS 的示例 这是我在 DynamoDB
如何通过sparkSession向worker提交多个jar?
我使用的是火花2 2 0 下面是我在 Spark 上使用的 java 代码片段 SparkSession spark SparkSession builder appName MySQL Connection master spark ip
如何使用 Amazon 的 EMR 在 CLI 中使用自定义 jar 指定 mapred 配置和 java 选项?
我想知道如何指定mapreduce配置 例如mapred task timeout mapred min split size等等 当使用自定义 jar 运行流作业时 当我们使用 ruby 或 python 等外部脚本语言运行时 我们可以使
如何创建 HIVE 表来读取分号分隔值
我想创建一个 HIVE 表 该表将以分号分隔的值读取 但我的代码不断给出错误 有没有人有什么建议 CREATE TABLE test details Time STRING Vital STRING sID STRING PARTITION
hive - 在值范围之间将一行拆分为多行
我在下面有一张表 想按从开始列到结束列的范围拆分行 即 id 和 value 应该对开始和结束之间的每个值重复 包括两者 id value start end 1 5 1 4 2 8 5 9 所需输出 id value current
处理 oozie 工作流程中的循环
我有一个 oozie 用例 用于检查输入数据可用性并根据数据可用性触发 MapReduce 作业 所以我编写了一个 shell 脚本来检查输入数据 并在 oozie 中为其创建了一个 ssh 操作 输入数据检查的重试次数和重试间隔应该是可配
Flume将数据从MySQL迁移到Hadoop
请分享您的想法 需求是将MySQL db中的数据迁移到Hadoop HBase进行分析 数据应该实时或接近实时地迁移 Flume可以支持这个吗 有什么更好的方法 据我了解 Flume 并不是为此而设计的 Flume 基本上用于读取日志 如数
Apache hadoop 版本 2.0 与 0.23
Hadoop 的版本和发行版太多 让我很困惑 我有几个问题 Apache Hadoop 1 x 是从 0 20 205 开始的 Apache Hadoop 2 0 是从 0 22 还是 0 23 开始 根据这个blogpost http b
使用字符串数组在 Hive 表上加载 CSV 文件
我正在尝试将 CSV 文件插入 Hive 其中一个字段是 string 数组 这是 CSV 文件 48 Snacks that Power Up Weight Loss Aidan B Prince Health Fitness Trave
如何按行扩展数组值!!使用 Hive SQL
我有一个有 4 列的表 其中一列 项目 类型是 ARRAY 其他是字符串 ID items name loc id1 item1 item2 item3 item4 item5 Mike CT id2 item3 item7 item4 i
Sqoop 导出分区的 Hive 表
我在尝试导出分区的 Hive 表时遇到了一些问题 这是否完全受支持 我尝试用谷歌搜索并找到一张 JIRA 票证 sqoop export connect jdbc mysql localhost testdb table sales exp
运行 Sqoop 导入和导出时如何找到最佳映射器数量?
我正在使用 Sqoop 版本 1 4 2 和 Oracle 数据库 运行 Sqoop 命令时 例如这样 sqoop import fs
将 Spark 添加到 Oozie 共享库
默认情况下 Oozie 共享 lib 目录提供 Hive Pig 和 Map Reduce 的库 如果我想在 Oozie 上运行 Spark 作业 最好将 Spark lib jar 添加到 Oozie 的共享库 而不是将它们复制到应用程序
当我将文件存储在 HDFS 中时,它们会被复制吗?
我是 Hadoop 新手 当我使用以下方式存储 Excel 文件时hadoop fs putcommoad 它存储在HDFS中 复制因子为3 我的问题是 是否需要3份并分别存储到3个节点中 这是 HDFS 工作的漫画 https docs
更改 Hadoop 中的数据节点数量
如何改变数据节点的数量 即禁用和启用某些数据节点来测试可扩展性 说得更清楚一点 我有4个数据节点 我想一一实验1 2 3 4个数据节点的性能 是否可以只更新名称节点中的从属文件 临时停用节点的正确方法 创建一个 排除文件 这列出了您想要删除
将 Apache Zeppelin 连接到 Hive
我尝试将我的 apache zeppelin 与我的 hive 元存储连接起来 我使用 zeppelin 0 7 3 所以没有 hive 解释器 只有 jdbc 我已将 hive site xml 复制到 zeppelin conf 文件夹
在蜂巢中出现错误
当我连接到 ireport 时 如果说在 hive shell 中显示表 则会出现此错误 元数据错误 java lang RuntimeException 无法实例化 org apache hadoop hive metastore Hiv
覆盖hadoop中的log4j.properties
如何覆盖hadoop中的默认log4j properties 如果我设置 hadoop root logger WARN console 它不会在控制台上打印日志 而我想要的是它不应该在日志文件中打印 INFO 我在 jar 中添加了一个
如何强制 Spark 执行代码?
我如何强制 Spark 执行对 map 的调用 即使它认为由于其惰性求值而不需要执行它 我试过把cache 与地图调用 但这仍然没有解决问题 我的地图方法实际上将结果上传到 HDFS 所以 它并非无用 但 Spark 认为它是无用的 简短回
使用 Java API 在 Hadoop 中移动文件?
我想使用 Java API 在 HDFS 中移动文件 我想不出办法做到这一点 FileSystem 类似乎只想允许在本地文件系统之间移动 但我想将它们保留在 HDFS 中并将它们移动到那里 我错过了一些基本的东西吗 我能想到的唯一方法是从输
随机推荐
C#窗体调用地图(高德地图)-实现公交线路查询
C 窗体调用地图 高德地图 实现公交线路查询 新建C 工程 创建Windows窗体应用程序 添加WebBrowser控件 用来显示网地图页 可以把滚动条 ScrollBarsEnabled 设置成false给取消掉 更加的美观方便 使用高德
刷脸支付成为下一个主流我们拭目以待
智能刷脸支付已成为2019支付生态的风口 对于超市 便利店 企事业单位 停车场 餐厅等所有支付场景 越早加入刷脸支付 将享受越多的风口红利 刷脸支付 智慧医疗 智慧校园 智慧银行 餐饮超市酒店 无感停车场 各场景解决方案 软件定制开发 支付
谷歌面试题解析: 扔鸡蛋的正确方式是什么?
面试中 为了考察应聘者的思维方式 面试官偶尔会出一些谜题 Puzzles 比如 在谷歌 就有这样一道让人 闻风丧胆 的面试题 You work in a 100 floor building and you get 2 identical
个人网站搭建记录
个人网站地址 实际需要 云服务器 域名 网站备案 知识储备 node写一些后台接口 express mysql数据库 navicat连接数据库 mysql 常用终端命令行 https www jb51 net article 194140
hexo问题及解决
1 推荐主题 butterfly 的默认 layout 很好 尤其对于内容比较多的 blog 安装方法如下 npm install hexo renderer pug hexo renderer stylus save npm instal
QMessageBox、QColorDialog、按钮汉化显示
QMessageBox QColorDialog 按钮汉化显示 版本 Qt5 9 9 环境 QtCretator MinGW 在Qt源码目录下找到qt zh CN ts复制一份到工程目录 该文件在 G install Qt Qt5 9 9
图像仿射变换shear怎么翻译?剪切、错切、推移哪个译词好?
老猿Python博文目录 https blog csdn net LaoYuanPython 仿射变换博文传送门 带星号的为付费专栏文章 图像仿射变换原理1 齐次坐标来龙去脉详解 图像仿射变换原理2 矩阵变换 线性变换和图像线性变换矩阵 图
关于CASE WHEN造成的查询缓慢的生产问题思考
因为做的是类似SAAS的系统 关于同一个业务没会有不同的视角 有管理员 有类别分类的 有特别逻辑处理的 总而言之涉及到很多方面 再加上历史遗留问题导致导致的数据问题 这SQL写起来真的酸爽 除了简单的关联 还要考虑到一个效率问题 最近就因为
搜索引擎的发展历史
第一代搜索引擎 分类目录时代 分类目录时代的的搜索引擎会收集互联网上各个网站的站名 网址 内容提要等信息 并将它们分门别类的编排到一个网站中 用户可以在分类目录中逐级浏览并寻找相关的网站 搜狐目录 hao123等就是典型的分类目录时代的代表
如何在数据库事务提交成功后进行异步操作
原文链接 问题 业务场景 业务需求上经常会有一些边缘操作 比如主流程操作A 用户报名课程操作入库 边缘操作B 发送邮件或短信通知 业务要求 操作A操作数据库失败后 事务回滚 那么操作B不能执行 失败后也可以重新进行自调度 操作A执行成功后
css3学习以及移动端开发基本概念的思考
html height 1000px background color red media screen and width 2560px html background color blue 注意 首先必须弄清楚 我们的width hei
=> js 中箭头函数使用总结
箭头函数感性认识 箭头函数 是在es6 中添加的一种规范 x gt x x 相当于 function x return x x 箭头函数相当于 匿名函数 简化了函数的定义 语言的发展都是倾向于简洁 对人类友好的 减轻工作量的 就相当于我最钟
Zookeeper启动报错~找不到或无法加载主类
按照之前自己写的博客安装zk 在启动的时候却发现 就是启动不了 百思不得其解 额 唯一的区别就是zk的版本不一样了 最后通过查看启动日志 一般都是在zk的log路径下 查出竟然报了如下的错误 root centos 1 logs tail
博图程序需要手动同步_TIA(博图)S7-1200实战篇:模拟量标定3--SCL语言生成成FC/FB块续...
往期相关回顾 定义各变量名称传感器量程上限 HI 下限 Lo PLC接收数字量 上限 K1 下限 K2 模拟量输入 AI 然后公式是 AI K2 K1 K2 HI Lo Lo 我们已经知道传感器标定的公式 那又如何在博图SCL语言环境编写程
【精读系列】GloVe: Global Vectors for Word Representation
本论文介绍了一种基于计数统计的词向量学习方法 GloVe 作者实验说明效果优于 Word2Vec 模型 阅读完成时间 20221109 一些预备知识或者是常用知识 GloVe 模型属于 count based method 所谓 count
Flink CDC(2.0) 如何加速海量数据的实时集成?
原文 Flink CDC 如何加速海量数据的实时集成 知乎 导读 Flink CDC如何解决海量数据集成的痛点 如何加速海量数据处理 Flink CDC社区如何运营 如何参与社区贡献 今天的介绍会围绕下面四点展开 Flink CDC 技术
自媒体怎么做?综合类自媒体账号怎么做好
原创 自媒体运营中比较大众化的就是综合类 比如趣头条 搜狐号等 可以发文字内容 可以发图文内容也可以发视频 可以说是多样化的 对于创作者来说 这样的平台更加方便 但是运营其实更加难 如果只是单一类的 掌握一种运营方法还比较容易 但是这种多样
FATFS实现数据追加功能(原文不覆盖)
在对FATFS的应用中我们经常需要把采集的数据存入的文件中 用作保存 也许我们的系统是一个长期的运行过程 但是我们的数据可能不是持续采集的 所以我们这样写代码 注册一个工作区域 f mount 0 fs 打开创建一个新文件 res f op
Chrome开启自带多线程下载
在地址栏输入 chrome flags 然后在搜索框中输入 Parallel downloading 选择enabled 重启Chrome
hadoop学习笔记之分布式计算框架
分布式计算框架 移动计算而不是移动数据 移动计算就是把你写好的计算 程序拷贝到不同的计算节点上运行 MapReduce适合做离线计算 Storm适合做流失计算 Spark适合做内存计算框架 从HDFS上存储的数据作为我们MapReduce的
热门标签
▷ Linux
大数据数据倾斜问题
大数据可视乎
粘滞位
GBDT回归任务
java集成测试
分子生成优化
移动渗透测试工具
数仓建设
网络小白进阶路
服务器芯片和超算芯片
量子技术元宇宙其他
C 笔记
WTL
智能医疗
程序员转行
零基础编程
Linux快捷方式
软连接
循环相减
Bailian