1. 分析目标
本项目旨在使用聚类算法对110个城市进行分类与排序,以寻找客观真实的城市分层方法、支持业务运营与决策。
2. 数据集
数据集来源于某互联网公司,特征值标签已做脱敏处理。数据集尺寸为111行×5列,第一行为标题行,其余110行为实例。
- 第一列:城市名,将作为index不参与模型计算;
- 第二列:特征值a,以数值表现的分类变量,1代表评价最好、4代表最差;
- 第三列:特征值b,数值型变量,数值越高对业务积极影响越大;
- 第四列:特征值c,数值型变量,数值越高对业务消极影响越大;
- 第五列:特征值d,数值型变量,数值越高对业务积极影响越大。
3. 方法论
首先,由于数据集呈现分类变量与数值变量混合的特点,本次数据分析将采用以下两种算法并在分析结束后进行对比择优:
- K-means算法:需要将分类变量a转换为哑变量,使其成为数值型变量,然后通过计算欧几里得距离得出聚类结果。算法运行结束后将使用轮廓系数评价聚类效果。
- K-prototype算法:无需创建哑变量,将分别为分类变量计算汉明距离、为数值型变量计算欧几里得距离然后得出聚类结果。算法运行结束后将使用成本函数评价聚类效果。
其次,数值型变量b、c、d的量纲明显不等,为避免量纲影响距离计算中不同变量的权重,需要对变量b、c、d进行处理。由于不知道是否符合正态分布,在这里使用归一化而非标准化。
最后,由于机器无法理解业务场景,算法本身无法对不同聚类进行排序。在找到合理聚类方法后需要人工构建一个聚类评价指标以实现排序。
本项目基于python 3.7.3,使用的库包括pandas、numpy、sklearn、matplotlib、seaborn、kmodes,具体代码详见附录。
4. 预处理
预处理步骤包括:
- 使用MinMaxScaler对变量b,c,d进行归一化
- 使用get_dummies为变量a创建哑变量
处理结束后的数据集如下所示(仅展示前五行为例):
| 城市 |
a_1 |
a_2 |
a_3 |
a_4 |
a |
b |
c |
d |
| 三亚 |
0 |
0 |
1 |
0 |
3 |
0.016206 |
0.009198 |
0.00757 |
| 上海 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
| 东莞 |
0 |
0 |
1 |
0 |
3 |
0.314485 |
0.187345 |
0.299205 |
| 中山 |
0 |
0 |
0 |
1 |
4 |
0.109215 |
0.060833 |
0.057343 |
| 临沂 |
0 |
0 |
0 |
1 |
4 |
0.106044 |
0.035673 |
0.018547 |
5. 分析过程
5.1 K-means
-
参与运算的列:a_1,a_2,a_3,a_4,b,c,d
-
手肘法求解最优k值(聚类数量):k=3

-
k=3时的轮廓系数评价:
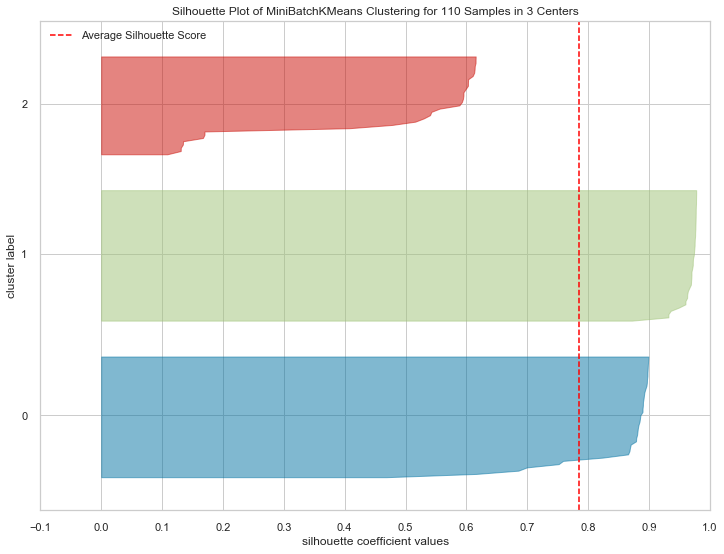

-
解读:虽然聚类间距良好,但是聚类2的轮廓系数过低,说明聚类2的聚合效果不好。在检视聚类2时发现其包含北京、上海、牡丹江、大庆等城市,有悖常规认知,说明该聚类不合理。
-
结论:k-means聚类结果不可用。
5.2 K-prototype
-
参与运算的列:a,b,c,d
-
手肘法求解最优k(使用成本函数制图):k=4
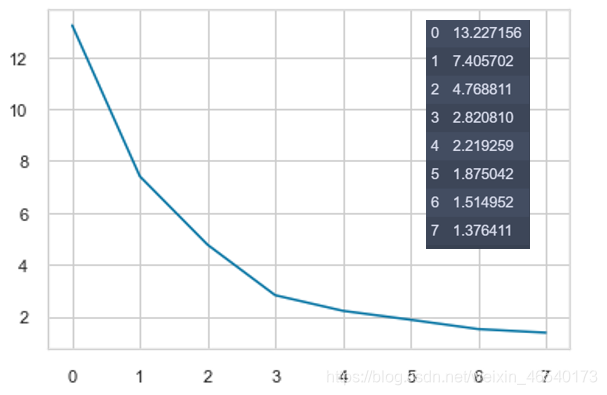
注1:python中计数从0开始计,所以横轴数值为聚类数量-1
注2:此方法结果具有随机性,有时会产生不止一个肘点,存在最优解和次优解。为确保k=3为最优解,此过程被运行了十次,最后验证最优解众数为3。
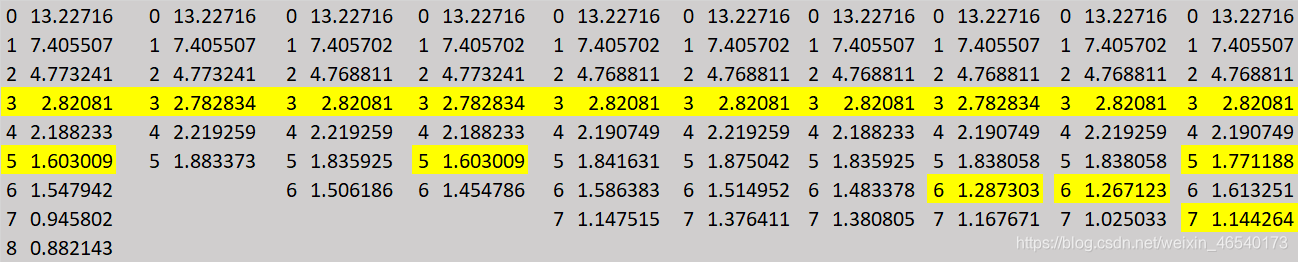
-
解读:分为四个聚类时,四个聚类所包含的城市符合一、二、三、四线城市的常规认知,说明聚类接近真实情况。
-
结论:K-prototype的聚类结果较为真实客观,可以采用。
6. 聚类排序
为实现聚类排序,首先调取了每个聚类的质点:
| |
Centroids(Min-max Scaled) |
Centroids(原数据) |
|
| Cluster |
a |
b |
c |
d |
a |
b |
c |
d |
Count |
| 0 |
4 |
0.05 |
0.02 |
0.01 |
4 |
3853.19 |
6638.98 |
56.46 |
48 |
| 1 |
2 |
0.66 |
0.52 |
0.59 |
2 |
38517.47 |
178333.07 |
3119.33 |
6 |
| 2 |
2 |
0.31 |
0.17 |
0.15 |
2 |
18678.75 |
60002.46 |
785.96 |
24 |
| 3 |
3 |
0.10 |
0.04 |
0.03 |
3 |
7053.54 |
16004.42 |
148.87 |
32 |
此处需要基于业务理解构建一个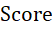 作为聚类评价指标。四个特征值的业务重要程度一致,因此需要采用等权重计算每个特征值的
作为聚类评价指标。四个特征值的业务重要程度一致,因此需要采用等权重计算每个特征值的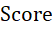 ,但是变量c对总
,但是变量c对总 的贡献为负。但是,考虑到量纲的影响,仍需使用归一化的b、c、d作为其
的贡献为负。但是,考虑到量纲的影响,仍需使用归一化的b、c、d作为其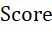 。如果将a作为数值型变量进行考量,也应当进行归一化处理,并且应注意数值越大实际上对
。如果将a作为数值型变量进行考量,也应当进行归一化处理,并且应注意数值越大实际上对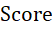 的贡献越低。综上所述,
的贡献越低。综上所述,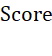 的构建方法如下:
的构建方法如下:

其中,
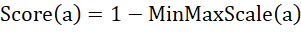



经计算,每个聚类的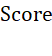 及排名如下:
及排名如下:
| Cluster |
Score |
Ranking |
| 0 |
0.04 |
4 |
| 1 |
1.40 |
1 |
| 2 |
0.95 |
2 |
| 3 |
0.42 |
3 |
经检视,聚类1、2、3、0非常接近常规认知中的一、二、三、四线城市,证明排序合理。
7. 结论
经过使用k-prototype算法和构建聚类评价指标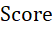 ,成功将110个城市分为四个聚类及聚类排序。同时运用评价指标
,成功将110个城市分为四个聚类及聚类排序。同时运用评价指标 ,结合归一化数据可对个体城市实现细粒度上的评价,从而得到每个聚类内部的城市排名情况或跨四个聚类的总体城市排名:
,结合归一化数据可对个体城市实现细粒度上的评价,从而得到每个聚类内部的城市排名情况或跨四个聚类的总体城市排名:
| 城市 |
a |
b |
c |
d |
cluster |
cluster_tag |
in-cluster_score |
in-cluster_ranking |
|