背景需求:
工会老师求助:如何在word里面插入4*8的框,我怎么也拉不到4*8大小(她用的是我WORD 文本框)
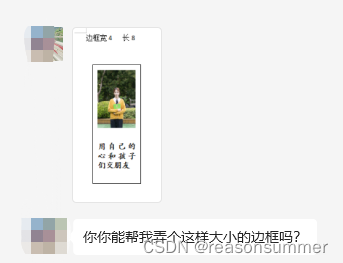
我一听,这又是要手动反复黏贴“文本框”“照片”“文字”的节奏哦
我问:你要做几个人?超过20个,我写个程序批量插图(写代码测试要费时间,如果数量少不如手动做)
工会老师:大约十几个人吧,你能直接插图?我一个个弄太麻烦了。
我说:OK,你把照片和文字发给我吧
材料准备:
全部材料路径(红框两个必备)
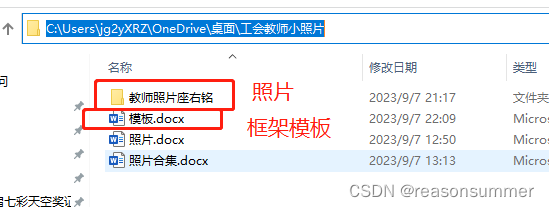
第一步:word框架


重要的事情!!!

第二步:图片下载,用“序号+名言+JPG” 方式命名照片
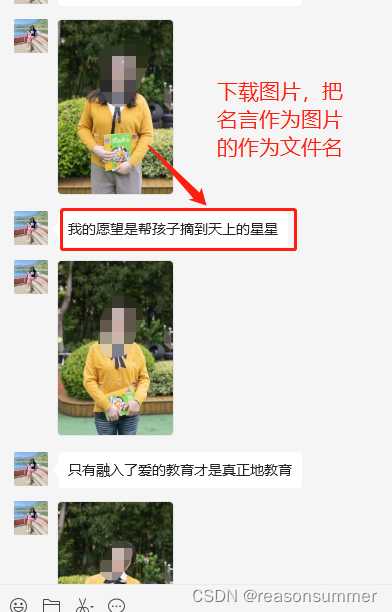
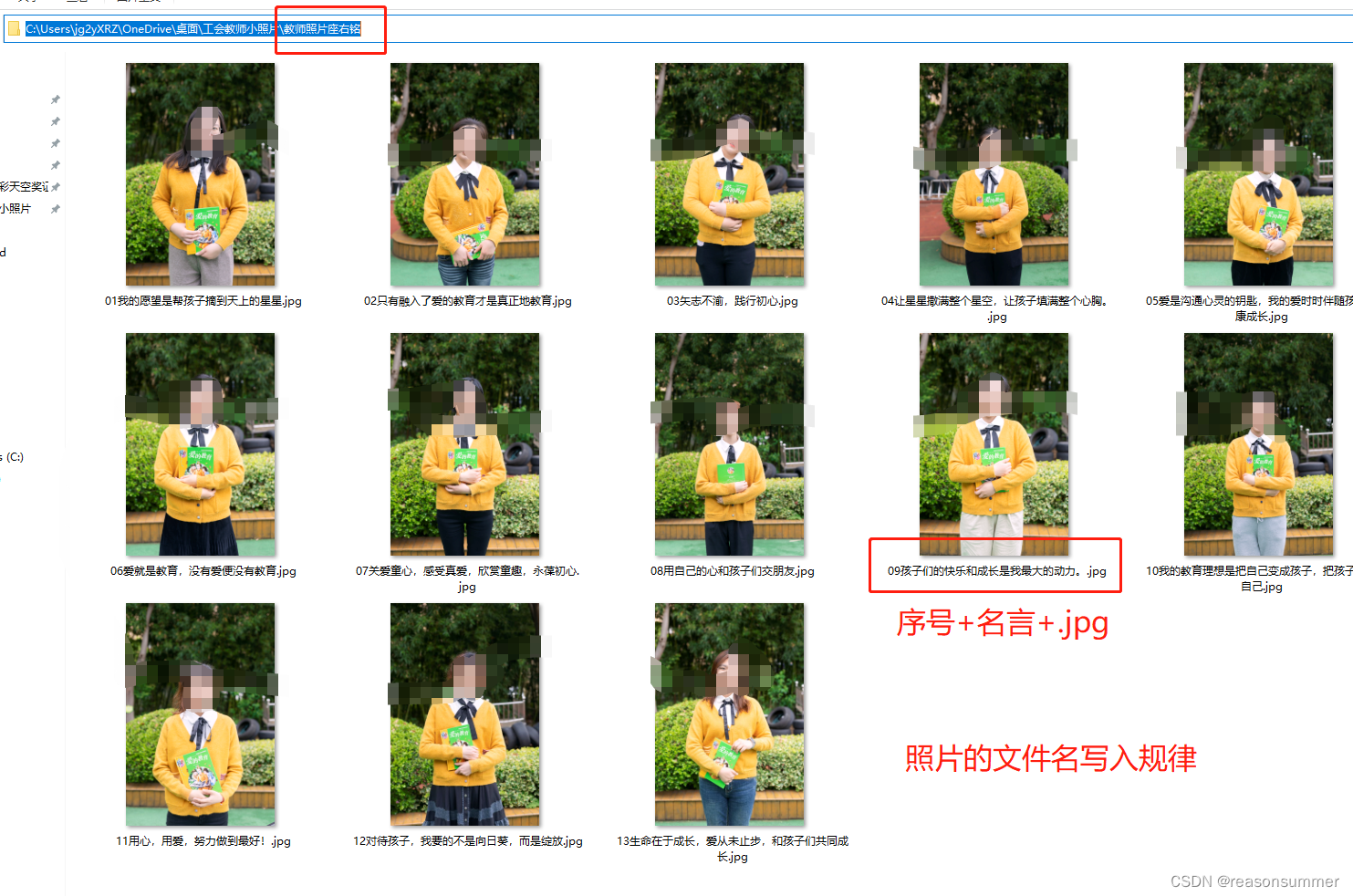
图片文件名结构——“序号”+“名言”+".jpg"
每位老师的序号和名言都不同


WORD里面表格的文字就是提取“图片名称里面的索引”2“到导引”倒数-4“中间的内容(留头,不留尾巴,尾部索引+1)

代码展示:
'''
工会小照片插入同一个WORD里
阿夏
时间:2023年9月7日)
'''
import os
from PIL import Image
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
print('----------第1步:把打照片变成小照片------------')
# 减小图片质量像素
pr=r"C:\Users\jg2yXRZ\OneDrive\桌面\工会教师小照片\教师照片座右铭"
# 新建小图文件夹
smallpath=pr[:-7]+'\\'+'教师照片座右铭(小图)'
os.mkdir(smallpath)
imgs1=os.listdir(pr)
print(imgs1)
for img1 in imgs1:
# print(img1)
if img1.endswith(".jpg"):
a=pr+'\\'+img1
# 减小图片质量像素
img = Image.open(a)
w,h = img.size
w,h = round(w * 0.2),round(h * 0.2)
# // 去掉浮点,防报错
img = img.resize((w,h), Image.ANTIALIAS)
img.save(smallpath+'\\'+img1, optimize=True, quality=85) # 9.99MB照片变成127KB
# 质量为85效果最好
print('----------第2步:读取写入小照片和文字------------')
path=[]
name=[]
imgs2=os.listdir(smallpath)
for img2 in imgs2:
if img1.endswith(".jpg"):
path.append(smallpath+'\\'+img2)
name.append(img2[2:-4])
print(path)
print(name)
# 制作零时文件夹
lspath=pr[:-7]+'\\'+'零时Word'
os.mkdir(lspath)
# 制作12个docx
for z in range(0,len(path)):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\工会教师小照片\模板.docx')
# # 制作列表
# 单元格位置3*4格
table = doc.tables[0] # 4567(8)
k=path[z]
k2=name[z]
# 写入图片
run=doc.tables[0].cell(0,0).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(k),width=Cm(3.5),height=Cm(6))
table.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
# 写入序号和生肖名称
run=table.cell(1,0).paragraphs[0].add_run(k2) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '楷体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(10) #输入字体大小默认30号 一行里(可以一页两份)
run.font.bold= True #是否加粗
run.font.color.rgb = RGBColor(0,0,0) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '楷体')#将输入语句中的中文部分字体变为华文行楷
table.cell(1,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
endlisth=lspath+'\\{}.docx'.format(z)
doc.save(endlisth)
print('----------第3步:doc 文档合并------------')
# 合并所有Word
import win32com.client as win32
import os
word = win32.gencache.EnsureDispatch('Word.Application')
#启动word对象应用
word.Visible = False
path = lspath
files = []
for filename in os.listdir(path):
filename = os.path.join(path,filename)
files.append(filename)
#新建合并后的文档(使用模板,进行12个文件夹的合并,把12个文件夹的内容贴到已有的模板(包含0.7边、四分栏))
output = word.Documents.Add(r'C:\Users\jg2yXRZ\OneDrive\桌面\工会教师小照片\模板.docx')
for file in files:
output.Application.Selection.InsertFile(file)#拼接文档
#获取合并后文档的内容
doc = output.Range(output.Content.Start, output.Content.End)
# 合并word
lspathall=pr[:-7]+'\\小照片合并打印(需手动整理).docx'
output.SaveAs(lspathall) #保存
output.Close()
print('----------第4步:删除临时文件夹------------')
import shutil
shutil.rmtree(lspath) #递归删除文件夹,即:删除非空文件夹
shutil.rmtree(smallpath)
# 合并word打开
lspathall=pr[:-7]+'\\小照片合并打印(需手动整理).docx'
终端运行(直接运行)

运行中,