1、正则表达式介绍
1、正则表达式---通常用于判断语句中,用来检查某一字符串是否满足某一格式
2、正则表达式是由普通字符与元字符组成
3、普通字符包括大小写字母、数字、标点符号及一些其他符号
4、元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
2、元字符
2.1基础正则表达式常见元字符
(支持的工具:grep、egrep、sed、awk)
| 字符 |
作用 |
| \ |
转义字符,可以把一些特殊的符号转换成普通的符号字符,还可以把一些普通字符转换成特殊功能,例:\!、\n、\$等 |
| ^ |
表示匹配字符串开始的位置,匹配行首,例: ^a、 ^# |
| $ |
表示匹配字符串末尾的位置,匹配行尾,例: word$、 #$ ;^$表示空行 |
| . |
匹配除\n之外的任意的一个字符,例: go.d、g..d |
| * |
匹配前面子表达式0次或者多次,例: goo*d、go.*d |
| .* |
表示任意长度的任一字符 |
| [my] |
表示匹配[ ]中包含的任一字符 |
| [^my] |
表示匹配除[ ]中包含的任一字符 |
| \{n\} |
匹配前面的子表达式n次,例:mo\{2\}y、'[0-9]\{ 2\ }'匹配两位及两位以上数字 |
| \{n,\} |
匹配前面的子表达式不少于n次,例: mo\{2,\}y、'[0-9]\{2,\}'匹配两位及两位以上数字 |
| \{n,m\} |
匹配前面的子表达式n到m次(m>=n),例: mo\{2,3\}y、'[0-9]\{2,3\}'匹配两位到三位数字 |
| 注: egrep(grep-E)、awk使用{n }、{n, }、{n,m}匹配时"{}”前不用加"\" |
| \w |
匹配包括下划线的任何单词字符 |
| \W |
匹配任何非单词字符。等价于"[^A-Za-z0-9_]"。 |
| \d |
匹配一个数字字符 |
| \D |
匹配一个非数字字符。等价于[^0-9]。 |
| \s |
空白符 |
| \S |
非空白符 |











2.2扩展正则表达式元字符
(支持的工具: egrep、awk、grep -E、sed -r)
| 字符 |
作用 |
| + |
表示匹配前面的子表达式1次以上 |
| ? |
表示匹配前面的子表达式0或者1次 |
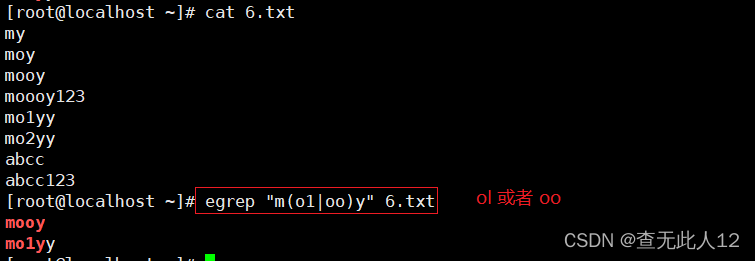
| ( ) |
将括号里的内容看成一个整体 |
| | |
以或的方式匹配字符串 |