什么是线性回归
线性回归利⽤回归⽅程(函数)对⼀个或多个⾃变量(特征值)和因变量(⽬标值)之间
关系进⾏建模的⼀种分析⽅式。一般只有一个特征值的称之为单变量回归,多个特征值的称之为多变量回归。
线性回归
线性回归可以分为两类:线性关系和非线性关系。
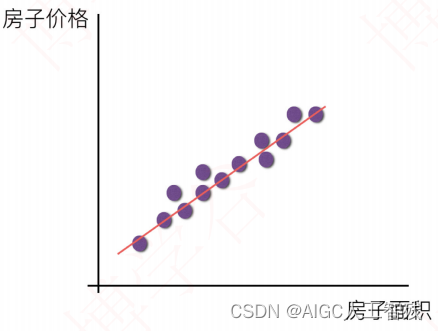
- 线性关系
线性关系是指特征值和目标值之间的关系呈现多元一次关系,例如一个特征值时,则特征值和目标值呈现直线性关系;两个特征值时,则特征值和目标值呈现平面关系。
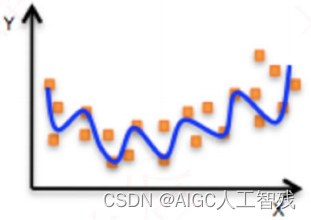
- 非线性关系
非线性关系指特征值和目标值之间的关系呈多元二次以上关系,即关系无法用直线来表达,需要用直线才能贴合。
损失函数
由算法得出的线性回归方程有会多种,那么模型是怎么选出最有的回归方程呢,那么让回归方程的值与实际值的误差最小,就是最好的回归方程,这就我们优化回归方程的函数:损失函数。
损失函数:预测的所有数值与实际数值之间差的平方的总和,又叫做最小二乘法,数学定义如下:
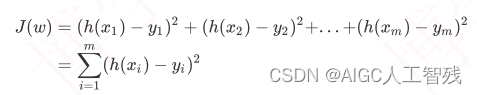
那么我们怎么求模型中的各个系数w,使得损失函数最小?在线性回归中常用到两种方法:
- 正规方程法
- 梯度下降法
1. 正规方程(LinearRegression)
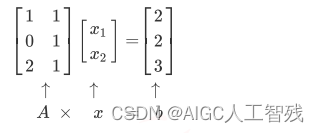
正规方程法就是数学中的求方程的未知数,将特征值、目标值和未知数w列出方程组,求解方程组,即可得到系数w,如下图的方程组。当特征值和w较少时,比较容易算出,但特征过多过于复杂时,则求解起来很麻烦,甚至求解不出答案。例如样本量较多时,更多采用梯度下降法。特征之间存在多重共线性问题时,需要使用岭回归(Ridge Regression)。
正规方程法公式如下:

X为特征矩阵,y为目标矩阵。
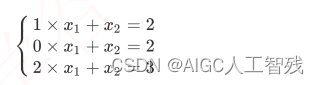
2.梯度下降法(SGDRegressor)
在求解回归方程时往往没有最优解,经常采用迭代的方法,不断沿着函数梯度的反方向更新参数,直到损失函数最小化。
梯度下降法的过程如下:
a. 随机初始化模型参数,并计算当前参数下损失函数的地图,即当前点的斜率;
b. 沿着参数朝着梯度的反方向进行一定的步长调整,使得损失函数下降;
c. 重复a和b的过程,直到损失函数达到最小值,或者设定迭代次数的限制。
梯度下降法的公式如下:
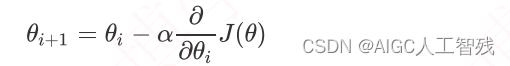
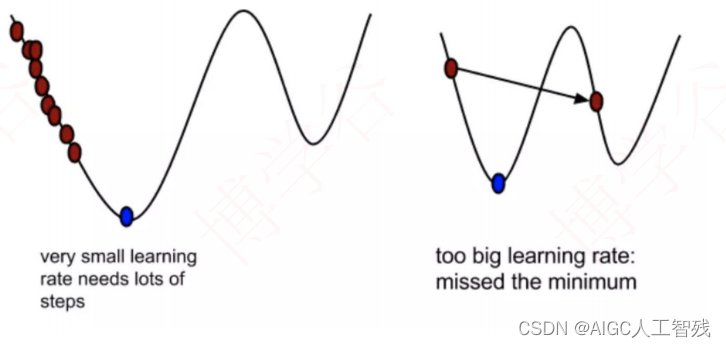
α在梯度下降算法中被称作为学习率或者步⻓,意味着我们可以通过α来控制每⼀步⾛的距离,控制参数不要⾛太快,错过了使损失函数取最⼩值的点。同时也要保证不要⾛的太慢,导致太阳下⼭了,还没有⾛到⼭下。所以α的选择在梯度下降法中往往是很重要的!α不能太⼤也不能太⼩,太⼩的话,可能导致迟迟⾛不到最低点,太⼤的话,会导致错过最低点!
梯度下降法分类:
- 全梯度下降算法(Full gradient descent) FGD
- 要在所有数据集上计算梯度,所以下降速度慢;
- 无法在线更新模型,即运行过程中无法增加样本
- 随机梯度下降算法(Stochastic gradient descent)SGD
- 计算单个样本的梯度,速度更快;
- 由于只使用一个样本,容易陷入局部最优解
- ⼩批量梯度下降算法(Mini-batch gradient descent)
- 随机抽取一个小批量样本集,然后再采用FGD
- batch_size = 1为SGD,batch_size=n为FGD,一般设为2的幂次方
- 随机平均梯度下降算法(Stochastic average gradient descent)
- 内存中为每个样本维护一个旧梯度,随机选择i个样本来更新该梯度,其他梯度保持不变,然后求得所有梯度的平均值
- n设置为1时,为SGD
两种方法对比
那么什么时候用正规方程法,什么时候用梯度下降法呢?
- 是否存在逆矩阵:从正规方程的公式可以得知,要先计算逆矩阵,有可能它的逆矩阵不存在,这就需要我们去除冗余特征值,让其逆矩阵不为0。而梯度下降法可以使用;
- 特征值数据量是否大:特征值数据大于10000时,建议采用梯度下降法。正规方程法计算量较大,难以计算,当然可以用主成分分析降低特征的维度,再使用正规方程法计算;
- 拟合函数是否为线性:不是线性无法使用正规方程法,梯度下降法还是可以使用;
- 以下几种情况特殊处理:
- 特征值数据较少,无法拟合;
- 特征值数量与样本量一致时,正规方程法可以解决;
所以线性回归的算法选择总结如下:
线性回归API
- 正规方程法:
sklearn.linear_model.LinearRegression(fit_intercept=True)
- 参数:
- 属性:
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
- 梯度下降法:
sklearn.linear_model.SGDRegressor(max_iter = 1000, loss=“squared_loss”, fit_intercept=True, learning_rate
=‘invscaling’, eta0=0.01)
- 参数:
- loss:损失类型
- max_iter用来指定神经网络的最大迭代次数,默认值为1000
- fit_intercept:是否计算偏置
- learning_rate:学习率填充
- ‘constant’: eta = eta0
- ‘optimal’: eta = 1.0 / (alpha * (t + t0)) [default]
- ‘invscaling’: eta = eta0 / pow(t, power_t) power_t=0.25:存在⽗类当中
- eta0:初始学习率或者步长,对于学习速率α,可以先选择0.001,然后按10倍来进行调整。
- 属性:
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
线性回归性能评估
均⽅误差(Mean Squared Error, MSE)评价线性回归模型的好坏,公式如下:
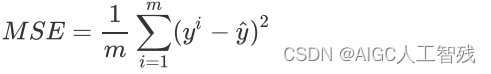
对应API:
- sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均⽅误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
线性回归应用
回归分析主要用于分析自变量和因变量的影响关系,也可以分析自变量对因变量的影响因素。它的主要应⽤场景是进⾏预测和控制例如计划制定、KPI制定、⽬标制定等。
优点
回归分析的优点是数据模式和结果便于理解,如线性回归⽤y=ax+b的形式表达,在解释和理
解⾃变量与因变量关系式相对容易;在基于函数公式的业务应⽤中,可以直接使⽤代⼊法求
解,因此应⽤起来⽐较容易。
缺点
回归分析的缺点是只能分析少量变量之间的相互关系,⽆法处理海量变量间的相互作⽤关系,
尤其是变量共同因素对因变量的影响程度。
回归分析实际落地场景举例
回归分析的结果,着重于不同X对于Y影响的对⽐,直接预测Y的场景较少。以在各种媒体上投放的⼴告对最终销售所产⽣的效果研究为例:
- 公司投入很多的营销渠道:传统大众媒体、直销媒体和数字媒体,通过线性回归能够回答不同渠道之间的销量影响;并且调整每个渠道之间的投入营销,从而获取最大收益;并且在哪个渠道的广告效果最好。
- 销售量=营销变量+误差因素;回归分析并不能直接得出营销变量和销售量的关系,但能够分析出营销变量里的影响因素大小。
回归分析的结果,着重于不同X对于Y影响的对⽐,直接预测Y的场景较少。