
CVPR 作为计算机视觉三大顶级会议之一,一直以来都备受关注。被 CVPR 收录的论文更是代表了计算机视觉领域的最新发展方向和水平。今年,CVPR 2019 将于美国洛杉矶举办,上个月接收结果公布后,又引起了 CV 届的一个小高潮,一时间涌现出众多 CVPR 论文的解读文章。
根据 CVPR 官网论文列表统计的数据,本年度共有 1300 篇论文被接收,而这个数据在过去 3 年分别为 643 篇(2016)、783 篇(2017)、979 篇(2018)。这从一个方面也说明了计算机视觉这个领域的方兴未艾,计算机视觉作为机器认知世界的基础,也作为最主要的人工智能技术之一,正在受到越来越多的关注。
全球的学者近期都沉浸在 CVPR 2019 的海量论文中,希望能第一时间接触到最前沿的研究成果。但在这篇文章里,我们先把 CVPR 2019 的论文放下,一同回首下 CVPR 2018 的论文情况。
根据谷歌学术上的数据,我们统计出了 CVPR 2018 收录的 979 篇论文中被引用量最多的前五名,希望能从引用量这个数据,了解到这些论文中,有哪些最为全球的学者们所关注。
由于不同搜索引擎的引用量数据各不相同,所以我们在这里仅列出了谷歌学术的数据。谷歌的参考文献是从多个文献库,包括大量书籍中筛选的,其引用次数一般仅作为衡量一篇论文重要性的粗略指标。
根据 CVPR 2018 的论文列表(http://openaccess.thecvf.com/CVPR2018.py)在谷歌学术进行搜索,得到数据如下(以 2019 年 3 月 19 日检索到的数据为准,因第 2 名及第 3 名数据十分接近,不做明确排名) :
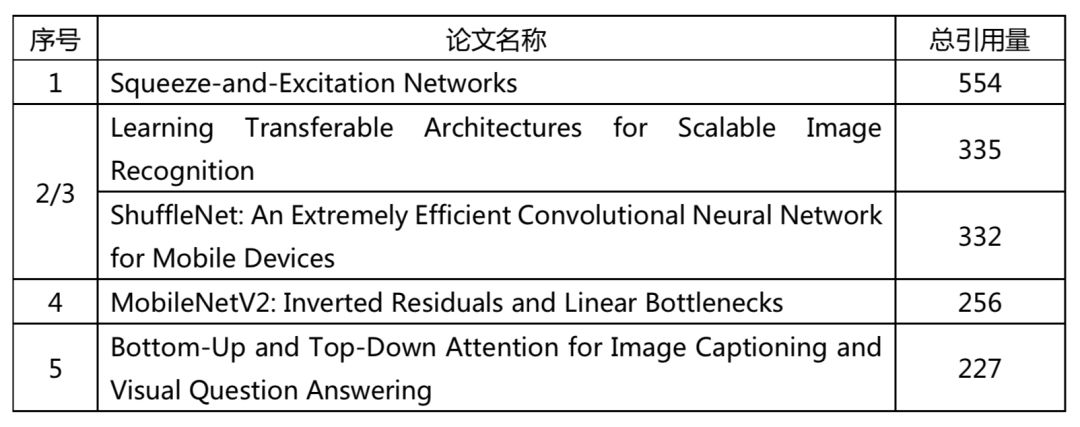
“引用”指的是在论文中引述前人的研究成果,是作者表明其方法、观点和发现来源的标准方式。评价一篇论文的重要性,除了论文是否被顶级会议收录这一维度,论文的被引数也是不可或缺的维度。虽然引用量具体到不同学科的数据相差很多,但在计算机视觉这一单个学科内,论文的被引用量是评价某篇论文是否得到推崇的重要量化指标。
CVPR 2018 的高被引数论文都是获得学术界较大关注和推崇的论文,这主要在于他们的开创性。例如,排名第一的 Squeeze-and-Excitation Networks(简称 SE-Net)构造就非常简单,很容易被部署,不需要引入新的函数或者层,并且在模型和计算复杂度上具有良好的特性。
借助 SE-Net,论文作者在 ImageNet 数据集上将 Top-5 error 降低到 2.251%(此前的最佳成绩为 2.991%),获得了 ImageNet 2017 竞赛图像分类的冠军。在过去一年里,SE-Net 不仅作为业界性能极强的深度学习网络单元被广泛使用,也为其他学者的研究提供了参考。
SE-Net 介绍详见原作者讲解:

此外,还有 Google Brain 带来的 Learning Transferable Architectures for Scalable Image Recognition,提出了用一个神经网络来学习另一个神经网络的结构,也为许多学者所关注。
以下是 5 篇文章的摘要,以供读者们回顾:



Convolutional neural networks are built upon the convolution operation, which extracts informative features by fusing spatial and channel-wise information together within local receptive fields. In order to boost the representational power of a network, several recent approaches have shown the benefit of enhancing spatial encoding.
In this work, we focus on the channel relationship and propose a novel architectural unit, which we term the “Squeeze- and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modeling interdependencies between channels. We demonstrate that by stacking these blocks together, we can construct SENet architectures that generalise extremely well across challenging datasets.
Crucially, we find that SE blocks produce significant performance improvements for existing state-of-the-art deep architectures at a minimal additional computational cost. SENets formed the foundation of our ILSVRC 2017 classification submission which won first place and significantly reduced the top-5 error to 2.251%, achieving a ∼25% relative improvement over the winning entry of 2016. Code and models are available at https: //github.com/hujie-frank/SENet.



We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves ∼13× actual speedup over AlexNet while maintaining comparable accuracy.



Developing neural network image classification models often requires significant architecture engineering. In this paper, we study a method to learn the model architectures directly on the dataset of interest. As this approach is expensive when the dataset is large, we propose to search for an architectural building block on a small dataset and then transfer the block to a larger dataset.
The key contribution of this work is the design of a new search space (which we call the “NASNet search space”) which enables transferability. In our experiments, we search for the best convolutional layer (or “cell”) on the CIFAR-10 dataset and then apply this cell to the ImageNet dataset by stacking together more copies of this cell, each with their own parameters to design a convolutional architecture, which we name a “NASNet architecture”.
We also introduce a new regularization technique called ScheduledDropPath that significantly improves generalization in the NASNet models. On CIFAR-10 itself, a NASNet found by our method achieves 2.4% error rate, which is state-of-the-art. Although the cell is not searched for directly on ImageNet, a NASNet constructed from the best cell achieves, among the published works, state-of-the-art accuracy of 82.7% top-1 and 96.2% top-5 on ImageNet. Our model is 1.2% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS – a reduction of 28% in computational demand from the previous state-of-the-art model.
When evaluated at different levels of computational cost, accuracies of NASNets exceed those of the state-of-the-art human-designed models. For instance, a small version of NASNet also achieves 74% top-1 accuracy, which is 3.1% better than equivalently-sized, state-of-the-art models for mobile platforms. Finally, the image features learned from image classification are generically useful and can be transferred to other computer vision problems. On the task of object detection, the learned features by NASNet used with the Faster-RCNN framework surpass state-of-the-art by 4.0% achieving 43.1% mAP on the COCO dataset.



In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3.
is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design.
Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on ImageNet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.



Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and topdown attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered.
Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
点击以下标题查看更多往期内容:
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐