-
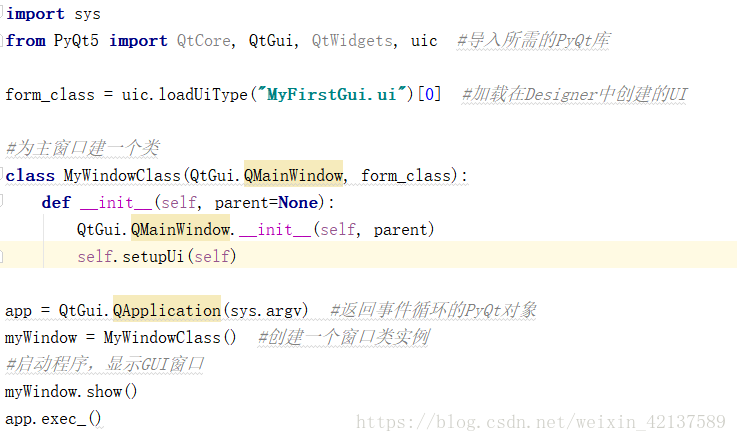
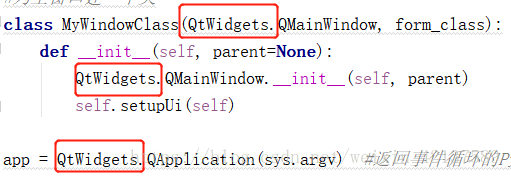
背景 我在 Django 1 8 5 中定义了以下模型 class PublishInfo models Model pass class Book models Model info models OneToOneField Publis
-
我上传了 2 个包 它们位于我的 gitlab 存储库中 如果我想使用 pip 将它们安装在我的系统中 这很容易 因为 gitlab 可以帮助您 https docs gitlab com ee user packages pypi rep
-
我安装为http www reinbach com uwsgi nginx flask virtualenv mac os x html http www reinbach com uwsgi nginx flask virtualenv
-
我需要从 psql 表中查找包含多个单引号的字符串 我当前的解决方案是将单引号替换为双单引号 如下所示 sql query f SELECT exists SELECT 1 FROM table name WHERE my column m
-
我需要将一个非常 高 的两列数组写入文本文件 而且速度非常慢 我发现如果我将数组改造成更宽的数组 写入速度会快得多 例如 import time import numpy as np dataMat1 np random rand 1000
-
我想处理不同形状的张量序列 列表 并输出另一个张量列表 考虑每个时间戳上具有不同隐藏状态大小的 RNN 就像是 输入 tf ones 1 2 2 tf ones 2 2 3 tf ones 3 2 1 输出 tf zeros 1 2 4 t
-
好的 我知道您可以使用 dir 方法列出模块中的所有内容 但是有什么方法可以仅查看该模块中定义的函数吗 例如 假设我的模块如下所示 from datetime import date datetime def test return Thi
-
在Python中 我有一个文件 其中的单词由 例如 city state zipcode 我的文件阅读器无法区分单词 另外 我希望我的文件阅读器从第 2 行而不是第 1 行开始 如何让我的文件阅读器分隔单词 import os import
-
我下面有一个 DataFrame 但我需要根据取消和订单列从每个代码中选择行 假设代码 xxx 的阶数为 6 1 5 1 阶数为 11 我需要一种算法 可以选择满足总共 11 行的行 阶数为 6 5 如果没有行匹配 则选择最接近的 id 并
-
我尝试像 while 循环一样跳过 for 循环中的几个步骤 在 while 循环中 步骤根据特定条件进行调整 如下面的代码所示 i 0 while i lt 10 if i 3 i 5 else print i i i 1 result
-
下面是我的代码 我面临着多处理问题 我看到这个问题之前已经被问过 我已经尝试过这些解决方案 但它似乎不起作用 有人可以帮我吗 from multiprocessing import Pool Manager Class X def init
-
我更喜欢在声明参数的同一行记录每个参数 根据需要 以便应用D R Y http en wikipedia org wiki Don t repeat yourself 如果我有这样的代码 def foo flab nickers a ser
-
我已经训练 CNN 对图像进行 3 类分类 在训练模型时 我使用 keras 的 ImageDataGenerator 类对图像应用预处理功能并重新缩放它 现在我的网络在测试集上训练得非常准确 但我不知道如何在单图像预测上应用预处理功能 如
-
我有两个数据框 df1 和 df2 np random seed 0 df1 pd DataFrame key A B C D id 2 23 234 2345 2021 np random randn 4 df2 pd DataFrame
-
只是一个问题 我试图将 csv 文件中的选定行写入新的 csv 文件 但出现错误 我试图读取的 test csv 文件是这样的 两列 2013 9 1 2013 10 2 2013 11 3 2013 12 4 2014 1 5 2014
-
我想在每次保存模型之前验证值 所以 我必须重写保存函数 代码几乎是一样的 我想把它写在 mixin 类中 但失败了 我不知道如何写 super func 我英语不好 抱歉 class SyncableMixin object def sav
-
Anaconda python 发行版 https store continuum io cshop anaconda 非常方便地部署科学计算环境 SCE 并根据需要切换python版本 默认情况下 安装会将 python 定位到 anac
-
我问自己关于 sklearn 中拟合方法的各种问题 问题1 当我这样做时 from sklearn decomposition import TruncatedSVD model TruncatedSVD svd 1 model fit X
-
我能够从表中获取单个数据 但是当我试图获取表上的所有数据时 我只得到一行 cnn execute sql rows cnn fetchall column t 0 for t in cnn description for row in ro
-
我有一个数据框 如下所示 import pandas as pd d decil 1 decil 1 decil 2 decil 2 decil 3 decil 3 decil kommune AA BB AA BB AA BB 2010