spark集群部署规划:
| hadoop1 |
master worker |
datanode namenode secondarynamenode(hadoop) resourcemanager nodemanager(yarn) |
| hadoop2 |
worker |
datanode nodemanager |
| hadoop3 |
worker |
datanode nodemanager |
问题引出:Hadoop集群启动后,使用jps查看进程均没问题,但是在Web50070端口上只显示了两个datanode。
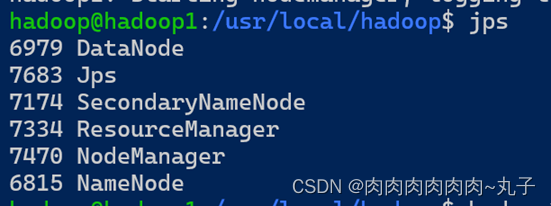
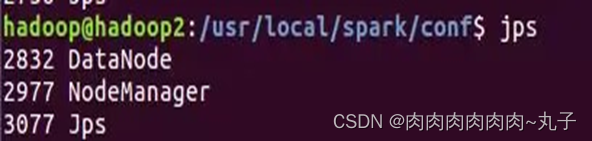

进入50070端口,发现只有hadoop1和hadoop2没有hadoop3
解决方法:
1.关闭集群
stop-dfs.sh
stop-yarn.sh
stop-dfs.sh
stop-yarn.sh
2.将集群中每个datanode节点的VERSION删除
(VERSION里面记录着datanode id信息 路径/hadoop/tmp/dfs/data/current)
cd /usr/local/hadoop/tmp/dfs/data/current/
ls
rm -f VERSION
cd /usr/local/hadoop/tmp/dfs/data/current/
ls
rm -f VERSION
3.执行hdfs namenode -format (格式化语句)
hdfs namenode -format
4.重启集群
先检查一下各个节点的etc/hosts文件是否都配置正确。
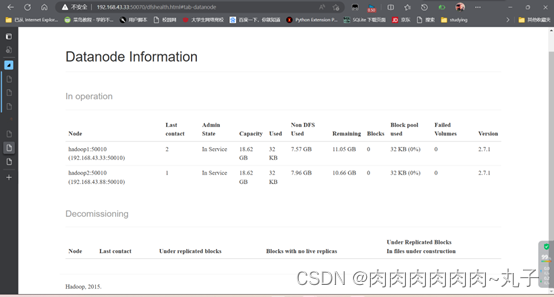
再次尝试:
登录master50070端口可以看到三个结点都存在,问题解决了!!!
