目录
1.txt数据集格式
2.xml数据集格式
3.转换代码
4.根据xml标签分割出图像中的目标物体
5.效果展示
1.txt数据集格式
第1元素代表类别,第2,3表示目标框的中心位置,第4,5表示目标框的大小。
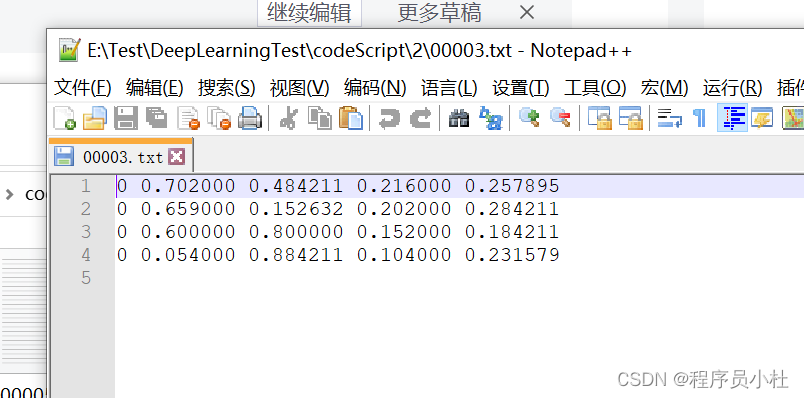
请注意: xml 格式文件 目标物体是xmin ymin xmax ymax 描述位置信息,表示目标框的左上角和右下角的坐标,因此在写脚本的时候要注意转换。
3. 转换代码
注意: 提供txt_path img_path 两个文件夹路径,且两者的文件数量和名称要对应。
# .txt-->.xml
# ! /usr/bin/python
# -*- coding:UTF-8 -*-
import os
import cv2
def txt_to_xml(txt_path,img_path,xml_path):
#1.字典对标签中的类别进行转换
dict = {'0': "organoid",
'1': "car",
'2': "bus",
'3': "ufo",
'4': "robot",
'5': "virus",
'6': "trunk",
'7': "plash",
'8': "biycle"}
#2.找到txt标签文件夹
files = os.listdir(txt_path)
#用于存储 "老图"
pre_img_name = ''
#3.遍历文件夹
for i, name in enumerate(files):
#许多人文件夹里有该文件,默认的也删不掉,那就直接pass
if name == "desktop.ini":
continue
print(name)
#4.打开txt
txtFile=open(txt_path+name)
#读取所有内容
txtList = txtFile.readlines()
#读取图片名称
img_name = name.split(".")[0]
pic = cv2.imread(img_path+img_name+".jpg")
#获取图像大小信息
Pheight,Pwidth,Pdepth=pic.shape
#5.遍历txt文件中每行内容
for row in txtList:
#按' '分割txt的一行的内容
oneline = row.strip().split(" ")
#遇到的是一张新图片
if img_name != pre_img_name:
#6.新建xml文件
xml_file = open((xml_path + img_name + '.xml'), 'w')
xml_file.write('<annotation>\n')
xml_file.write(' <folder>VOC2007</folder>\n')
xml_file.write(' <filename>' + img_name + '.jpg' + '</filename>\n')
xml_file.write('<source>\n')
xml_file.write('<database>orgaquant</database>\n')
xml_file.write('<annotation>organoids</annotation>\n')
xml_file.write('</source>\n')
xml_file.write(' <size>\n')
xml_file.write(' <width>' + str(Pwidth) + '</width>\n')
xml_file.write(' <height>' + str(Pheight) + '</height>\n')
xml_file.write(' <depth>' + str(Pdepth) + '</depth>\n')
xml_file.write(' </size>\n')
xml_file.write(' <object>\n')
xml_file.write('<name>' + dict[oneline[0]] + '</name>\n')
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(int(((float(oneline[1]))*Pwidth+1)-(float(oneline[3]))*0.5*Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(int(((float(oneline[2]))*Pheight+1)-(float(oneline[4]))*0.5*Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(int(((float(oneline[1]))*Pwidth+1)+(float(oneline[3]))*0.5*Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(int(((float(oneline[2]))*Pheight+1)+(float(oneline[4]))*0.5*Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
pre_img_name = img_name #将其设为"老"图
else: #不是新图而是"老图"
#7.同一张图片,只需要追加写入object
xml_file = open((xml_path + img_name + '.xml'), 'a')
xml_file.write(' <object>\n')
xml_file.write('<name>'+dict[oneline[0]]+'</name>\n')
''' 按需添加这里和上面
xml_file.write(' <pose>Unspecified</pose>\n')
xml_file.write(' <truncated>0</truncated>\n')
xml_file.write(' <difficult>0</difficult>\n')
'''
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(int(((float(oneline[1]))*Pwidth+1)-(float(oneline[3]))*0.5*Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(int(((float(oneline[2]))*Pheight+1)-(float(oneline[4]))*0.5*Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(int(((float(oneline[1]))*Pwidth+1)+(float(oneline[3]))*0.5*Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(int(((float(oneline[2]))*Pheight+1)+(float(oneline[4]))*0.5*Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
#8.读完txt文件最后写入</annotation>
xml_file1 = open((xml_path + pre_img_name + '.xml'), 'a')
xml_file1.write('</annotation>')
xml_file1.close()
print("Done !")
#修改成自己的文件夹 注意文件夹最后要加上/
txt_to_xml("txt_path/","img_path/","xml_path/")
4. 根据xml标签分割出图像中的目标物体
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = '1/'
# XML文件的地址
anno_path = '3/'
# 存结果的文件夹
cut_path = 'crops/'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
print(obj_i)
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("&&&&")
if __name__ == '__main__':
main()
5.效果展示
原图:
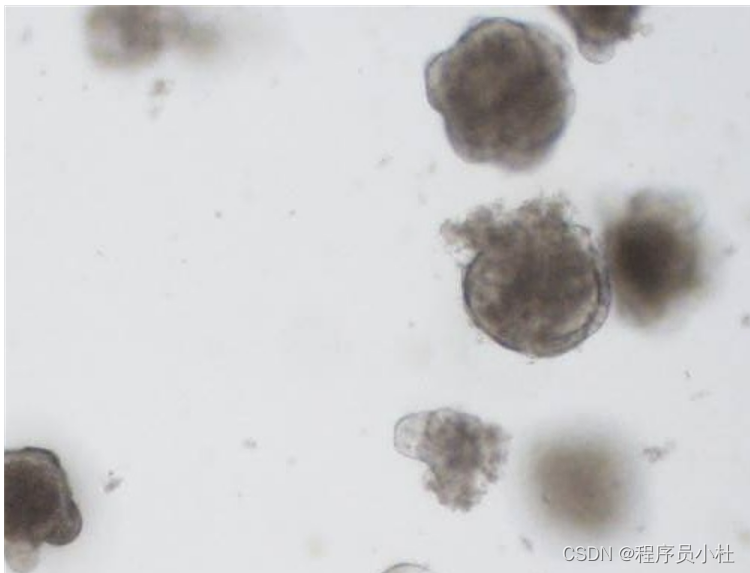
分割后的图像:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)