研究脑电算法的时候发现了一个问题,如何评价模型的准确性? 之前的工作流程都是先用公开数据集的数据训练好模型,然后放到实测数据上进行参数微调。在公开数据集上进行模型的选择主要是因为公开数据集的数据质量较好,可以排除硬件的影响,从而专心于算法的研究。但有些时候,尽管在公开数据集上计算模型得到的结果也不是很理想,可是还想进一步分析算法,这时候就需要保证数据的不受其他因素的影响了,可是实测的数据总是会受到各种外界因素的干扰,难以对一些计算细节进行分析。要是能有模拟的脑电信号就好了,这样就可以不受其他因素干扰了,查了一下,MNE中还真有这方面的库。
里面有一个例子包含的内容比较全面,,,,,,,,,,,,,,,,,
以此为例进行学习:
第一步:导入数据模板,利用模板中的电极信息。
import numpy as np
import matplotlib.pyplot as plt
import mne
from mne import find_events, Epochs, compute_covariance, make_ad_hoc_cov
from mne.datasets import sample
from mne.simulation import (simulate_sparse_stc, simulate_raw,add_noise, add_ecg, add_eog)
# 打印开头的函数说明,这里没有添加说明也就没有内容需要打印
print(__doc__)
# 设置数据路径,MNE下载的数据保存路径
data_path = sample.data_path()
raw_fname = data_path + '/MEG/sample/sample_audvis_raw.fif'
fwd_fname = data_path + '/MEG/sample/sample_audvis-meg-eeg-oct-6-fwd.fif'
# 加载数据作为模板,主要是为了使用电极位置等一系列相关信息
raw = mne.io.read_raw_fif(raw_fname)
# 设置参考电极,默认为average,这里projection为Ture说明只是添加了参考,但并没有进行运算
raw.set_eeg_reference(projection=True)
第二步:生成源的波形数据
# 创建的偶极子数
n_dipoles = 4
# 每一个epoch/event的持续时间
epoch_duration = 2.
# 谐波数
n = 0
# 获取随机状态,主要是为了使每次运行的结果相同,方便调试,如果不设置固定状态,每次的结果会不一样
rng = np.random.RandomState(0)
# 数据生成函数,在10赫兹谐波下产生时间交错的正弦波,函数中的n为全局变量,这里有4个偶极子会调用4次,
# 也就是生成10hz,20hz,30hz,40hz的正弦波
def data_fun(times):
# 全局变量n
global n
# 时间序列长度
n_samp = len(times)
# 时间窗,主要为了后面生成时间交错的波形
window = np.zeros(n_samp)
# 时间窗的起始和结束范围,谐波间隔出现
start, stop = [int(ii * float(n_samp) / (2 * n_dipoles))
for ii in (2 * n, 2 * n + 1)]
# 对想保留的范围赋值为1
window[start:stop] = 1.
# 全局变量加一
n += 1
# 正弦波函数sin(2*pi*w*t)
data = 25e-9 * np.sin(2. * np.pi * 10. * n * times)
# 保留时间窗内对应的数据,也可以理解为滤波
data *= window
# 返回生成的波形数据
return data
# 获取时间序列,前面我们读取了sample_audvis_raw.fif作为模板,获取其采样频率,其对应的epoch_duration(2秒钟)的时间序列如下。
times = raw.times[:int(raw.info['sfreq'] * epoch_duration)]
# 获取位置正解信息,我的理解也就是信号源的位置信息
fwd = mne.read_forward_solution(fwd_fname)
# 获取源位置
src = fwd['src']
# 利用data_fun函数生成4个偶极子离散源的时间序列
stc = simulate_sparse_stc(src, n_dipoles=n_dipoles, times=times,
data_fun=data_fun, random_state=rng)
# 绘制4个偶极子源的时间序列图像
fig, ax = plt.subplots(1)
ax.plot(times, 1e9 * stc.data.T)
ax.set(ylabel='Amplitude (nAm)', xlabel='Time (sec)')
mne.viz.utils.plt_show()

第三步:模拟原始数据
在simulate_raw函数的实现中,提到了一篇参考文献,尝试了很多途径都没有找到,要是谁有希望能分享下。
[1] Larson E, Taulu S (2017). "The Importance of Properly Compensating
for Head Movements During MEG Acquisition Across Different Age
Groups." Brain Topogr 30:172–181
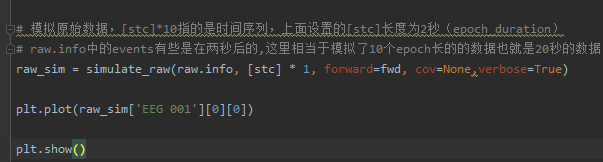
# 模拟原始数据,[stc]*10指的是时间序列,上面设置的[stc]长度为2秒(epoch_duration)
# raw.info中的events有些是在两秒后的,这里相当于模拟了10个epoch长的的数据也就是20秒的数据
raw_sim = simulate_raw(raw.info, [stc] * 10, forward=fwd, cov=None,verbose=True)
# 生成噪声的协方差
cov = make_ad_hoc_cov(raw_sim.info)
# 添加噪音
add_noise(raw_sim, cov, iir_filter=[0.2, -0.2, 0.04], random_state=rng)
# 添加心电(ECG)信号
add_ecg(raw_sim, random_state=rng)
# 添加眼电(EOG)信号
add_eog(raw_sim, random_state=rng)
# 绘制添加噪声后的数据
raw_sim.plot()

第四步:绘制白化后的evoke数据
# 提取事件
events = find_events(raw_sim)
# 根据事件生成epochs
epochs = Epochs(raw_sim, events, 1, tmin=-0.2, tmax=epoch_duration)
# 计算epoch的经验协方差
cov = compute_covariance(epochs, tmax=0., method='empirical', verbose='error')
# epoch求取均值得到evoke
evoked = epochs.average()
# 绘制evoke白化后的数据
evoked.plot_white(cov, time_unit='s')

其它一些个人理解
按照示例程序走了一遍,对整个过程大概理解了,但是为啥看起来和源的波形差距那么大呢?
1、噪声、心电、眼电对数据的影响。
提取其中的一个epoch数据进行分析,这是没加噪声前EEG 001的数据
EEG001的检测数据->添加噪声后的数据,添加心电和眼电后的数据,



2、不加噪声的数据
如果不添加噪声数据会是什么样子呢?注释掉add_noise()。

不加噪声的脑电信号,不加噪声的时候还是可以看出源的波形图的。

