在C++的程序设计中,为了处理方便,把具有相同类型的若干变量或对象按有序的形式组织起来,这些按序排列的同类数据元素的集合称为数组,组成数组的变量或对象称为数组的元素。数组元素由数组名和下标组成。
1.数组的声明
数组属于构造类型,在使用前一定要先进行类型声明,然后才能被引用。这里的声明又称为定义性声明
类型标识符 数组名[ 常量表达式1 ] [ 常量表达式2 ] . . . ;
其中类型标识符是用来说明数组元素的类型,可以是任一种基本数据类型,也可以是构造类型或类等用户自定义的类型。数组名的命名规则和变量名相同,遵循标识符规则,但不能与其他变量名重名。常量表达式需要用一对方括号括起来,可以是常量,符号常量或常量表达式,但是不允许为变量,即C++不允许对数组的大小做动态的定义。常量表达式1用来确定第1维下标的长度,常量表达式2用来确定第2维下标的长度…数组元素的个数等于各维长度的乘积。
# define M 50 int a[ 10 ] ;
char str[ M] ;
float b[ 3 ] [ 4 ] ;
Notice:
一般情况下,三维和三维以上数组很少用,最常用的就是一维数组。
2.数组的使用
一个数组一旦经过定义即可以使用,但是数组不允许整体使用,只能逐个引用数组元素。
数组名[ 下标表达式1 ] [ 下标表达式2 ] . . .
其中,下标表达式的个数取决于数组的维度,该组下标指明拟访问的数组元素的在数组中的位置。下标表达式一般为整形常量或整形表达式,若为小数,系统自动取整。下标表达式的值从0开始,上界不要超过声明时所确定的该维的大小。在引用数组元素时若下标"越界",C++编译系统是不做检查报错的,这时需要编程者在编写程序的时候自己保证引用的正确性。数组元素的使用方法和同类型的变量使用方法一样,凡是允许使用该类型变量的地方,都可以使用数组元素。
a[ 3 ] = 2 * a[ 0 ] ; //合法
cout>> a[ 10 ] ; //合法
cin<< b[ i] [ j] ; //合法
我们通过下面的例子来进行学习:
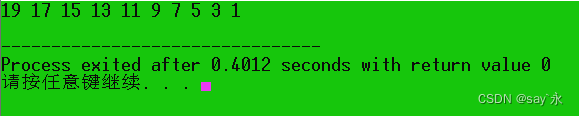
# include <iostream> using namespace std;
int main ( void )
{
int i, a[ 10 ] ;
for ( i = 0 ; i< 10 ; i++ ) {
a[ i] = 2 * i+ 1 ;
}
for ( i = 9 ; i>= 0 ; i-- ) {
cout<< a[ i] << ' ' ;
}
cout<< endl;
return 0 ;
}
程序运行结果:
1.数组的存储
数组在内存中占用一段连续的内存空间,数组元素的值依次存储在这段连续的存储空间内。对于一维数组,数组按下标由小到大存放;对于多维数组,元素"按行存储",即首先存储第一维下标为0的所有元素,再存储下标为1的所有元素等,依次类推。
int a[ 10 ] ;
float b[ 3 ] [ 4 ] ;
说明a数组在内存中占用一段连续的空间,在这段空间内依次存储a[0],a[1],a[2]直到a[9]。b数组在内存中也占用一段连续的空间,在这段空间内首先存储行下标为0的所有元素,即b[0][0],b[0][1],b[0][2].b[0][3],然后再存储行下标为1的所有元素,即b[1][0],b[1][1],b[1][2],b[1][3],最后存储行下标为2的所有元素,即b[2][0],b[2][1],b[2][2],b[2][3].
2.数组的初始化
数组的初始化是指在声明数组的时候对数组中开始的若干元素乃至全部元素赋初值。
对于基本类型的数组初始化的过程就是给数组元素赋值;对于对象数组,每个元素都是某个类的一个对象,初始化就是调用该对象的构造函数。
(1)数组元素全部初始化
例如,一维数组元素全部初始化
int a[ 10 ] = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } ;
Notice:
例如,二维数组全部初始化:
int b1[ 3 ] [ 4 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 } ;
int b2[ 3 ] [ 4 ] = { { 1 , 2 , 3 , 4 } , { 5 , 6 , 7 , 8 } , { 9 , 10 , 11 , 12 } } ;
二维数组初始化时,可以按行连续赋初值,即把所有元素的值都写在{}内,数组元素的值按其在内存中的排列顺序赋值,若所有元素均有赋值,在定义的时候可以省掉第一维的大小,编译系统在编译程序时对初始值表中所包含的元素的个数进行检测,能够自动确定这个二维数组的第一维长度。也可以采用按行分段赋初值,即按第一维下标进行分组,使用{}将每一组数组括起来。若初始化时每一行均有赋值,在定义的时候可以省掉第一维的大小。
int b1[ ] [ 4 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 } ;
int b2[ ] [ 4 ] = { { 1 , 2 , 3 , 4 } , { 5 , 6 , 7 , 8 } , { 9 , 10 , 11 , 12 } } ;
(2)数组元素部分初始化
数组在初始化的时候,初始值的数目小于数组的个数,即只给出部分数组元素的初始值,则数组剩余的元素自动被初始化为0.如果是一维数组部分初始化,则在定义时不能省掉方括号中的常量;若二维数组采用的是按行连续赋初值的方式,则在定义时不能省掉第一维的大小;若采用按行分段赋初值,行没有全给,定义时也不能省略第一维的大小。例如:
int a[ 10 ] = { 0 , 1 , 2 , 3 , 4 } ; //只给a[0]~a[4]5个元素赋0值,定义的时候[]中的10不能省略掉
int b1[ 3 ] [ 4 ] = { { 0 , 1 } , { 0 , 0 , 2 } , { 3 } } ; //可以省略掉一维大小3
/*上面语句与下面语句等价*/
int b1[ 3 ] [ 4 ] = { 0 , 1 , 0 , 0 , 0 , 0 , 0 , 2 , 0 , 3 } ; //第一维大小3不能省略
int b2[ ] [ 4 ] = { { 0 , 0 , 3 } , { 0 } , { 0 , 10 } } ; //采用按行分段赋初值,每行都有给数据,省略第一维大小
这样的写法能够通知编译系统:数组共有3行。数组各元素为:
[
1
2
3
4
5
6
]
\left[ \begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ \end{matrix} \right]
[ 1 4 2 5 3 6 ]
[
1
4
2
5
3
6
]
\left[ \begin{matrix} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{matrix} \right]
1 2 3 4 5 6
解决代码如下:
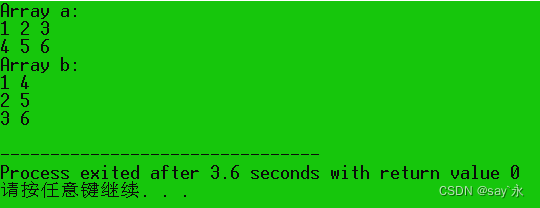
# include <iostream> using namespace std;
int main ( void )
{
int a[ 2 ] [ 3 ] = { { 1 , 2 , 3 } , { 4 , 5 , 6 } } ;
int b[ 3 ] [ 2 ] ;
for ( int i = 0 ; i < 2 ; i++ ) {
for ( int j = 0 ; j< 3 ; j++ ) {
b[ j] [ i] = a[ i] [ j] ;
}
}
cout<< "Array a:" << endl;
for ( int i= 0 ; i< 2 ; i++ ) {
for ( int j= 0 ; j< 3 ; j++ ) {
cout<< a[ i] [ j] << ' ' ;
}
cout<< endl;
}
cout<< "Array b:" << endl;
for ( int i= 0 ; i< 3 ; i++ ) {
for ( int j= 0 ; j< 2 ; j++ ) {
cout<< b[ i] [ j] << ' ' ;
}
cout<< endl;
}
return 0 ;
}
运行结果如下:
数组元素和数组名都可以作为函数的实参,以实现函数间数据的传递和共享。数组元素作为函数实参时,其用法与同类型变量作为函数实参时用法相同;数组名作为函数实参时,传递的时数组的首地址。
**1.数组元素作为函数实参
前面已经介绍过,数组元素的使用等同于同类型的变量。因此数组元素作为函数实参同变量实参一样,和形参之间采取的是单向的"值传递".
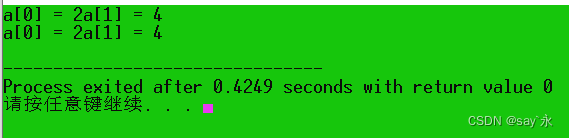
/*用数组元素作为函数实参*/
# include <iostream> using namespace std;
void swap1 ( int x, int y) {
int t;
t = x;
x = y;
y = t;
}
int main ( )
{
int a[ 2 ] = { 2 , 4 } ;
cout<< "a[0] = " << a[ 0 ] << "a[1] = " << a[ 1 ] << endl;
swap1 ( a[ 0 ] , a[ 1 ] ) ;
cout<< "a[0] = " << a[ 0 ] << "a[1] = " << a[ 1 ] << endl;
return 0 ;
}
运行结果如下:
2.数组名作为函数实参
用数组名作为函数实参,此时,实参与形参都应是数组名,且类型要相同。
和数组元素作为实参不同,由于数组名代表的是数组所占用的内存段的起始地址,故使用数组名作为函数实参时,传递的是实参数组的首地址。case 1: 编写一个函数可以求n个数的平均值,并在主函数中调用该函数
# include <iostream> using namespace std;
float average ( float array[ ] , int n) {
float aver, sum = 0 ;
for ( int i = 0 ; i < n; i++ ) {
sum = sum + array[ i] ;
}
aver = sum/ n;
return aver;
}
int main ( void )
{
float data[ 10 ] = { 5.6 , 8.9 , 4 , 3.2 , 1 , 2.8 , 98 , 12 , 23.5 , 44.6 } ;
cout<< "the average of datal is " << average ( data, 10 ) << endl;
return 0 ;
}
运行结果如下:
关于数组名作为实参的几点说明 case 1 中array是形参数组名,data是实参数组名,分别在其所在函数中定义。case 1 中均为float型),系统可能进行自动转换,但是不一定能得到期望的结果。case 1 中是n).case 2:用数组名作为函数实参实现数组元素的反序存储
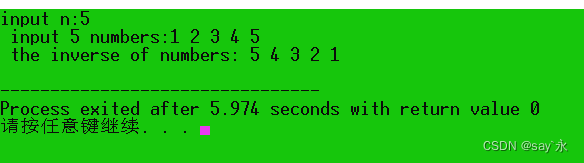
# include <iostream> using namespace std;
void inverse ( int array[ ] , int n) {
int i, j, t;
for ( i = 0 , j = n- 1 ; i< j; i++ , j-- ) {
t = array[ i] ;
array[ i] = array[ j] ;
array[ j] = t;
}
}
int main ( )
{
int a[ 10 ] , i, n;
cout<< "input n:" ;
cin>> n;
cout<< " input " << n<< " numbers:" ;
for ( int i= 0 ; i< n; i++ ) {
cin>> a[ i] ;
}
inverse ( a, n) ;
cout<< " the inverse of numbers:" ;
for ( int i= 0 ; i< n; i++ ) {
cout<< " " << a[ i] ;
}
cout<< endl;
return 0 ;
}
运行结果如下:
int a[ 3 ] [ 10 ] ;
//或者
//int a[][10];
二者都合法并且等价。但是不能把第二维大小说明省略。case 3:有一个2✖4的矩阵,求所有元素中的最小值。
# include <iostream> using namespace std;
int min_value ( int array[ ] [ 4 ] , int n) {
int min;
min = array[ 0 ] [ 0 ] ;
for ( int i = 0 ; i< n; i++ ) {
for ( int j = 0 ; j< 4 ; j++ ) {
if ( array[ i] [ j] < min) {
min = array[ i] [ j] ;
}
}
}
return min;
}
int main ( void )
{
int a[ 2 ] [ 4 ] = { { 101 , 34 , 63 , 28 } , { 90 , 17 , 56 , 62 } } ;
cout<< min_value ( a, 2 ) << endl;
return 0 ;
}
运行结果如下:
数组的元素可以是基本数据类型的数据,也可以是用户自定义数据类型的数据,对象数组就是指数组的元素是对象。
对象数组中的元素必须属于同一个类,每个元素不仅具有数据成员,而且还有成员函数。因此和基本数据类型相比,对象数组有一些特殊之处。
类名 数组名[ 下标表达式] . . . ;
其中"类名"指出该对象数组的元素所在的类;"下标表达式"给出数组的维数和大小。例如:
myclass obs[ 5 ] ; //定义了一个对象数组obs,它含有5个属于exam类的对象
与基本类型数组一样,在使用对象数组时也只能使用单个数组元素。每个数组元素都是一个对象,通过这个对象,便可以访问到它的2公有成员。其引用形式为:
数组名[ 下标] . 成员名
例如:
cout<< obs[ 2 ] . getx ( ) << endl;
其中,getx()是myclass中的公有成员函数case 4:给类中无自定义的构造函数的对象数组赋值
# include <iostream> using namespace std;
class exam {
private :
int x;
public :
void setx ( int n) {
x = n;
}
int getx ( ) {
return x;
}
} ;
int main ( void )
{
exam ob[ 4 ] ;
for ( int i = 0 ; i < 4 ; i++ ) {
ob[ i] . setx ( i) ;
}
for ( int i= 0 ; i< 4 ; i++ ) {
cout<< ob[ i] . getx ( ) << ' ' << endl;
}
return 0 ;
}
case 5: 给类中定义了不带参数的构造函数的对象数组赋值
# include <iostream> using namespace std;
class exam {
private :
int x;
public :
exam ( ) {
x = 0 ;
}
exam ( int n) {
x = n;
}
int getx ( ) {
return x;
}
} ;
int main ( void )
{
exam ob1[ 4 ] ; //调用不带参数的构造函数
exam ob2[ 4 ] = { 1 , 2 , 3 , 4 } ; //调用初始值表给对象数组赋值
for ( int i= 0 ; i< 4 ; i++ ) {
cout<< ob1[ i] . getx ( ) << " " << endl;
}
for ( int i= 0 ; i< 4 ; i++ ) {
cout<< ob2[ i] . getx ( ) << " " << endl;
}
return 0 ;
}
/冒泡排序 /
# include <iostream> using namespace std;
void sort ( int array[ ] , int n) {
for ( int i= 0 ; i< n- 1 ; i++ ) {
for ( int j= 0 ; j< n- 1 - i; j++ ) {
if ( array[ j] > array[ j+ 1 ] ) {
int temp = array[ j] ;
array[ j] = array[ j+ 1 ] ;
array[ j+ 1 ] = temp;
}
}
}
}
int main ( void )
{
int a[ 10 ] ;
cout<< "input 10 numbers:" << endl;
for ( int i= 0 ; i< 10 ; i++ ) {
cin>> a[ i] ;
}
sort ( a, 10 ) ;
cout<< "the sorted numbers:" << endl;
for ( int i= 0 ; i< 10 ; i++ ) {
cout<< a[ i] << ' ' ;
}
cout<< endl;
return 0 ;
}
运行结果如下:求二维数组中的鞍点
**所谓鞍点是指一个矩阵元素的值在其所在行最大,在其所在类最小。
# include <iostream> using namespace std;
# define M 3 # define N 3 int AnDian_solve ( int B[ ] [ N] ) {
for ( int i= 0 ; i< M; i++ ) {
int max_temp = B[ i] [ 0 ] ;
int col; //记录元素所在列
for ( int j= 0 ; j< N; j++ ) {
if ( B[ i] [ j] > max_temp) {
max_temp = B[ i] [ j] ;
col = j;
}
}
int flag = 1 ;
for ( int k= 0 ; k< M&& flag; k++ ) {
if ( B[ k] [ col] < max_temp) {
flag = 0 ;
break ;
}
}
if ( flag) {
cout<< "数组A中的鞍点是:" << max_temp<< endl;
cout<< "位置是:" << "第" << i+ 1 << "行" << "第" << col+ 1 << "列" << endl;
return 0 ;
}
}
return 1 ;
}
int main ( void )
{
int A[ M] [ N] ;
cout<< "请输入数组A[M][N]的元素:" << endl;
for ( int i= 0 ; i< M; i++ ) {
for ( int j= 0 ; j< N; j++ ) {
cin>> A[ i] [ j] ;
}
}
int returnN = AnDian_solve ( A) ;
if ( returnN) {
cout<< "数组A无鞍点" << endl;
}
return 0 ;
}
运行结果如下: