1、查询分类

- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
match_query 根据单个字段查询
multi_match_query 根据多个字段查询
3.精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
ids 根据id查询
range 根据范围查询
term 精确查询
4.地理(geo)查询:根据经纬度查询。例如:
geo_distance
geo_bounding_box
5.复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
bool
function_score
基本语法:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
2、查询所有
注意:因为性能问题,查询到的结果页面显示的不是全部。

3、全文检索查询
match查询
:会对用户输入内容进行分词,然后去倒排索引库检索,只根据一个查询字段中是否包含用户输入的词分词后的词
比如用户输入赎吧安居客,先分词成赎吧和安居客两个词,然后查询fileId字段中包含赎吧和安居客其中任意一个词的文档

先分词后查询

multi_match查询
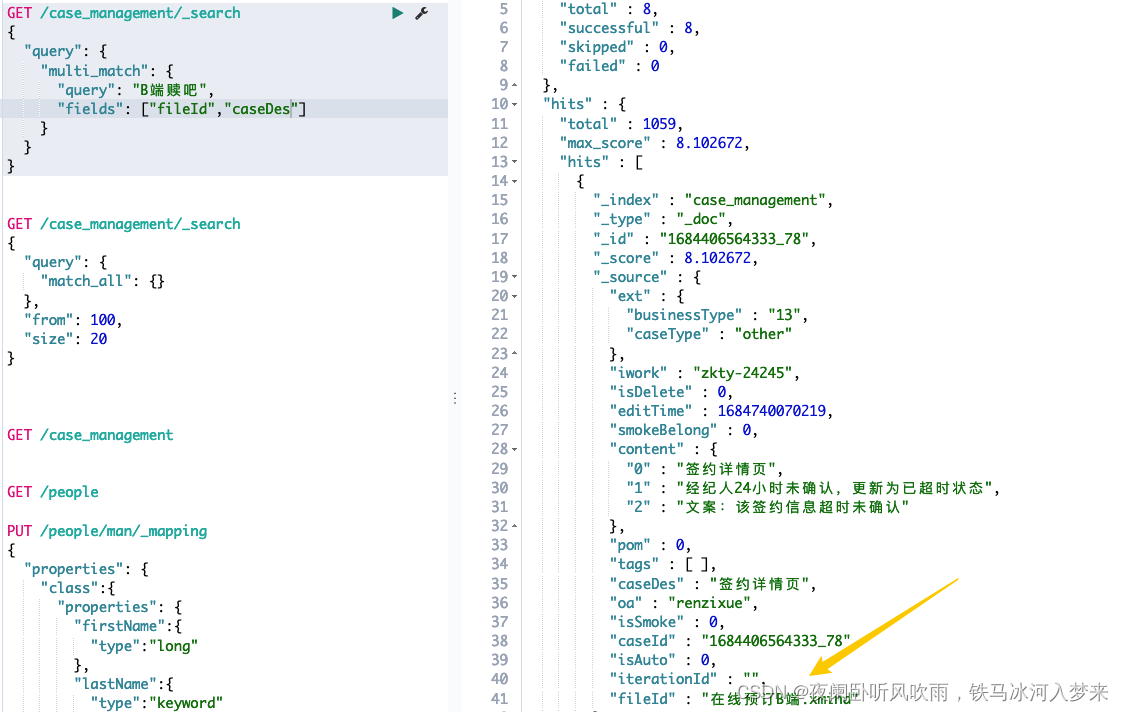
:多个字段查询,也是先对用户输入分词,分词后查询多个字段中任意一处符合即可
如输入B端赎吧,查询字段是 "fields": ["fileId","caseDes"],就是fileId和caseDes中只要有一处包含B端或赎吧即可返回
copy_to属性
multi_match:根据多个字段查询,参与查询字段越多,查询性能越差,所以常用的是会将常参与查询的字段复制到一个字段中,如下将title字段和content字段拷贝到full_text字段中,查询时仅查询full_text字段即可,full_text字段并不存在,只是一种关联关系,可参与查询
copy_to属性是用来将一个字段的内容复制到另一个字段中的。这样可以实现对同一个文档的多个字段进行索引和搜索,适用于需要对特定字段进行更详细的搜索或分析的情况
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "full_text"
},
"content": {
"type": "text",
"copy_to": "full_text"
},
"full_text": {
"type": "text"
}
}
}
}
4、精确查询
term 精确查询
主要用来查询不能分词的字段
根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
查询oa名称为lilan04的文档,如果查询oa为lilan的查询不到数据

range范围查询
主要用来查询范围内的数据,根据数值范围查询,可以是数值、日期的范围

5、地理位置查询
geo_distance:查询到指定中心点小于某个距离值的所有文档
geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"FIELD": "31.21,121.5"
}
}
}
6、复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑
Function Score Query
fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
相关性算分:
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
function score query定义的三要素:
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算



Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
must:必须匹配每个子查询,类似“与”
should:选择性匹配子查询,类似“或”
must_not:必须不匹配,不参与算分,类似“非”
filter:必须匹配,不参与算分
如下:查询oa是lilan04时间在2023-01-01 -2023-08-15不能是已删除的文档信息
GET /case_management/_search
{
"query": {
"bool": {
"must": [
{"match": {
"oa": "lilan04"
}}
],
"should": [
{
"range": {
"editTime": {
"gte": 1684740000000,
"lte": 1684740070219
}
}
}
],
"filter": {
"term": {
"isDelete": "1"
}
}
}
},
"from": 100,
"size": 20
}
7、搜索结果处理
排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。

按编辑时间排序


分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果


针对深度分页,ES提供了两种解决方案,官方文档:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。

高亮
高亮:就是在搜索结果中把搜索关键字突出显示
将搜索结果中的关键字用标签标记出来
在页面中给标签添加css样式
GET /books/_search
{
"query": {
"match": { "title": "javascript" }
},
"highlight": {
"require_field_match": false,
"fields": {
"fieldTitle": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
},
"fieldContent": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"]
}
}
}
}
