前言
利用Python爬取IMDB电影。废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
random模块;
bs4模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一来豆瓣作为爬虫入门,各种大牛的深入分析已趋于完美;另一方面随着中国电影工业的发展,我们需要将视角转向国际市场,通过数据分析,了解一下外国人比较感兴趣的电影。
思路分析
IMDB top250主页
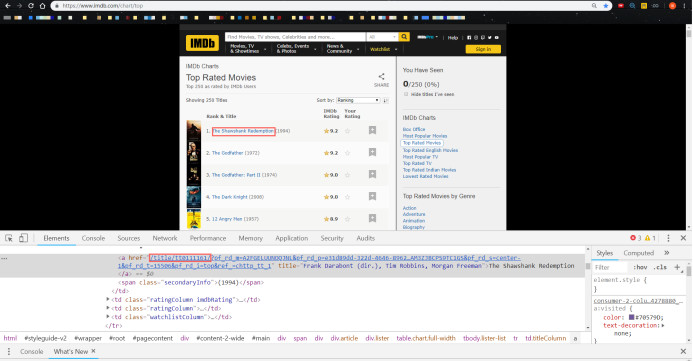
IMDB电影详情页 (1)
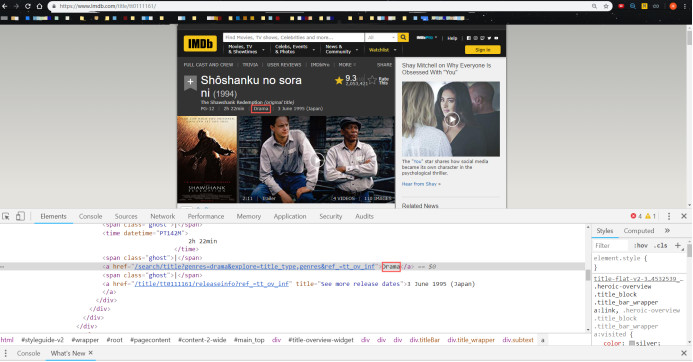
IMDB 电影详情页 (2)
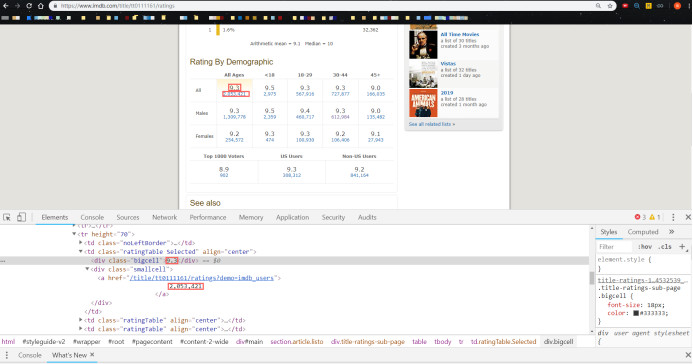
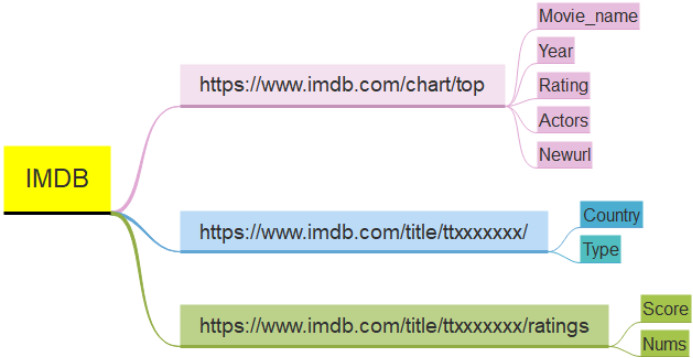
基于以上网页构造,我们发现只需得到每个电影的详情页编码(唯一),通过2次“蛙跳”,实现详情页(1)(2)导出国家&类型,分数&人数的信息的获取。便于理解,爬取思维导图如下:
爬虫代码
IMDB top250主页
#导入库-------------------------------------------
from urllib import request
from chardet import detect
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
#获取网页源码,生成soup对象-------------------------
def getSoup(url):
with request.urlopen(url) as fp:
byt = fp.read()
det = detect(byt)
time.sleep(random.randrange(1,5))
return BeautifulSoup(byt.decode(det['encoding']),'lxml')
#解析数据-------------------------------------------
def getData(soup):
#获取评分
ol = soup.find('tbody', attrs = {
'class': 'lister-list'})
score_info = ol