1、概述
在hive中执行sql任务时,当任务在reduce阶段一直卡在99%时,很有可能出现了数据倾斜,这个时候如果我们
的sql很长,需要判断出是哪段sql导致的数据倾斜,才便于我们解决问题。
2、定位数据倾斜
2.1、表结构
2.1.1、第一张表:user_info(用户基本信息)
| 字段名 |
字段含义 |
| userkey |
用户标识 |
| idno |
用户身份证号 |
| phone |
用户的手机号 |
| name |
用户姓名 |
2.1.2、第二张表:user_active(用户活跃)
| 字段名 |
字段含义 |
| userkey |
用户标识 |
| user_active_at |
用户最后活跃日期 |
2.1.3、第三张表:user_intend(用户意向表)
| 字段名 |
含义 |
| phone |
用户的手机号 |
| intend_commodity |
用户意向次数最多的商品 |
| intend_rank |
用户意向等级 |
2.1.4、第四张表:user_order(用户订单表)
| 字段名 |
字段含义 |
| idno |
用户的身份证号 |
| order_num |
用户的订单次数 |
| order_amount |
用户的订单总金额 |
2.1.5、代码
select
a.userkey,
a.idno,
a.phone,
a.name,
b.user_active_at,
c.intend_commodity,
c.intend_rank,
d.order_num,
d.order_amount
from user_info a
left join user_active b on a.userkey = b.userkey
left join user_intend c on a.phone = c.phone
left join user_order d on a.idno = d.idno;
- 执行本条sql后,任务在reduce阶段一直卡顿在99%,如图:
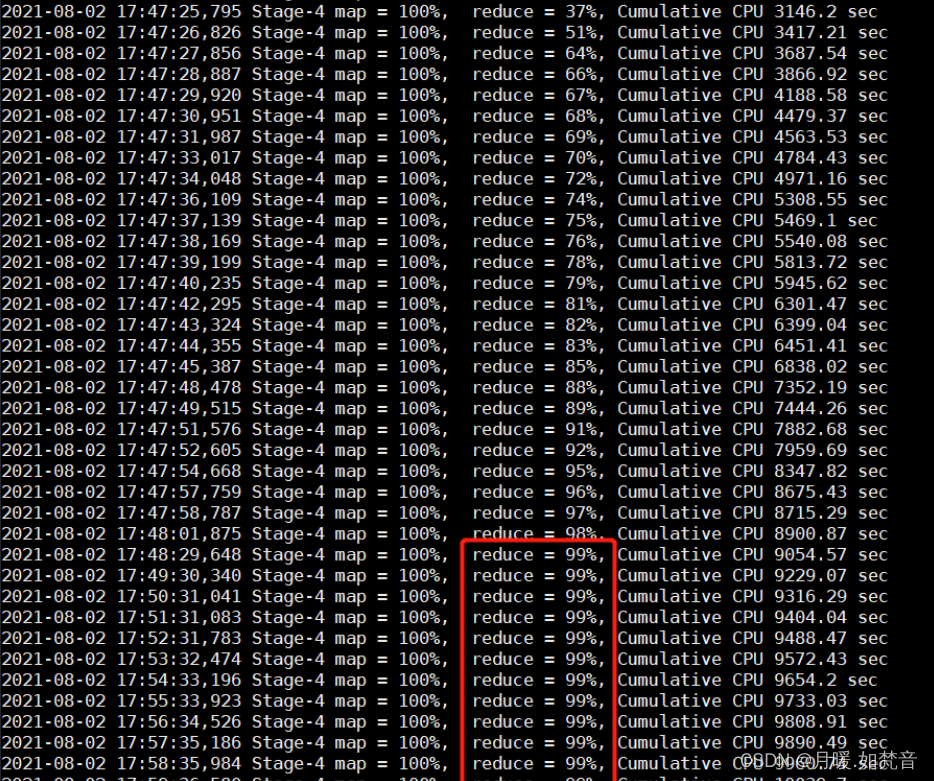
- 出现这种情况,我们便需要考虑数据倾斜。当然,还有一种情况是任务执行超时,当Reduce 处理的数据量巨大,在做 full gc 的时候,stop the world。导致响应超时,超出默认的 600 秒,任务被杀掉。报错信息一般如下:

2.1.6、数据倾斜排查
- 在本条sql中,如果出现数据倾斜,那一定是由大key导致的,那就需要判断是哪一步的关联出现了大key(确定到底是不是大key导致的数据倾斜)
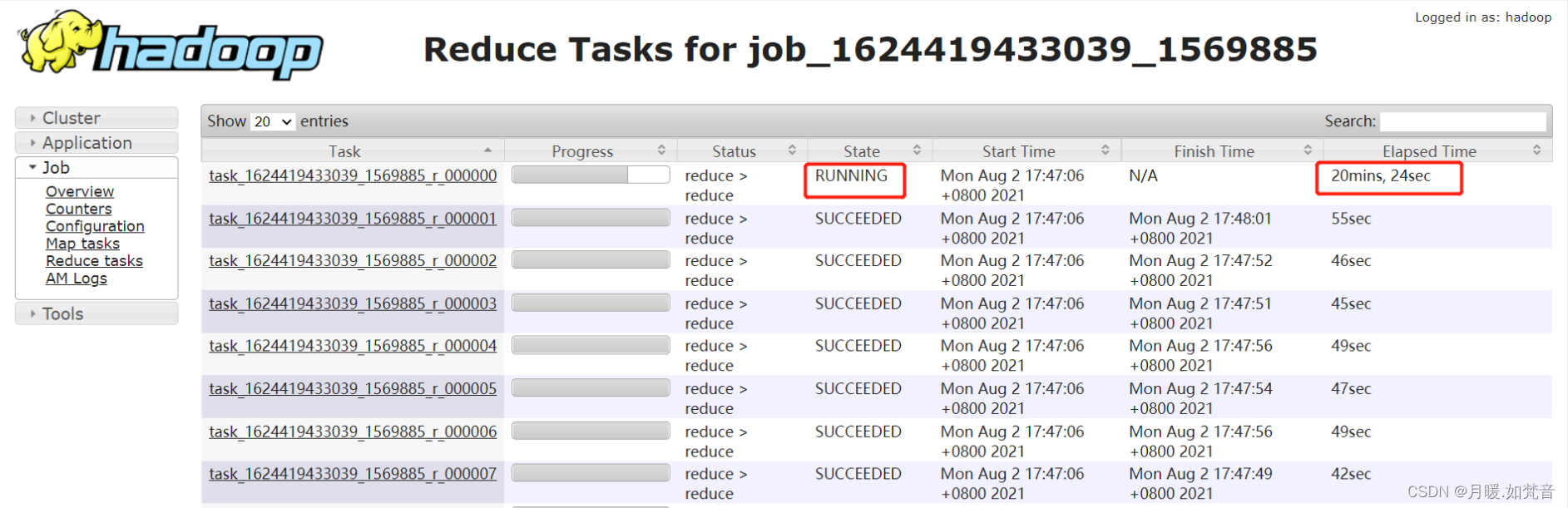
- 1、通过UI查看reduce的执行时间,如图所示,当其中某一个reduce的执行时间远超过其它的reduce执行时间
- 1、如果所有的reduce的执行时间都很长,可能是reduce数量较少导致的
- 2、某个 task 执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce 的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于 task 执行节点问题导致的个别 task 慢。但是如果推测执行后的 task 执行任务也特别慢,那更说明该 task 可能会有倾斜问题。
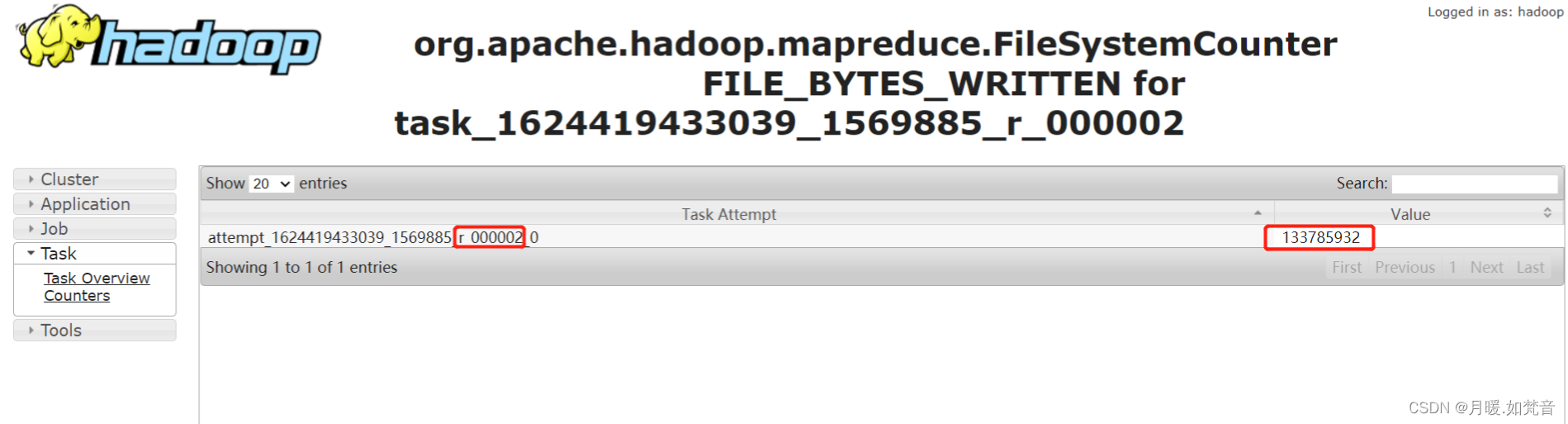
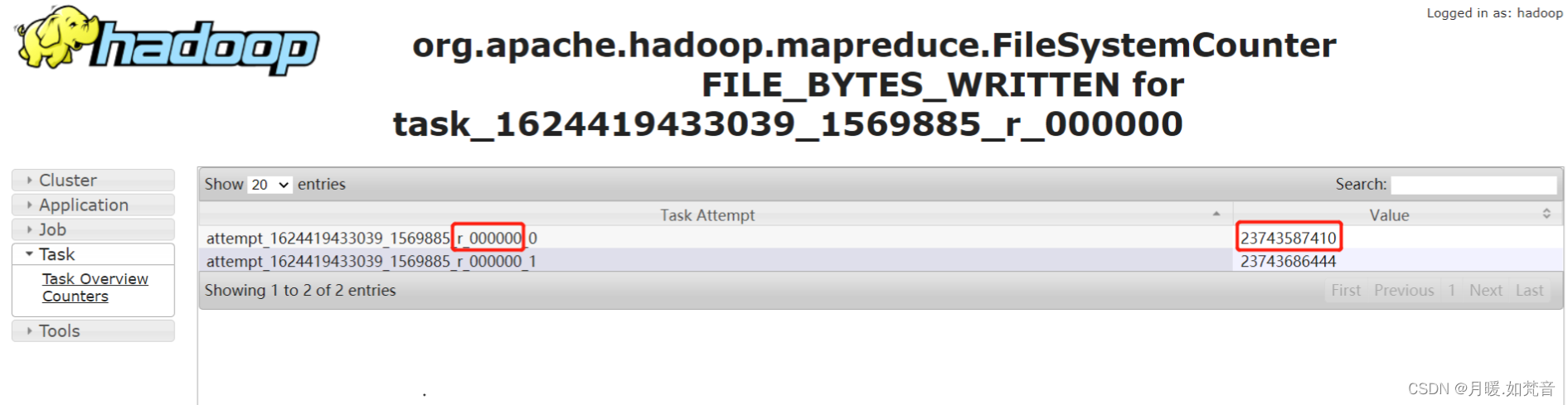
- 3、通过job中task输入的记录数判断,如图,其余task输入的记录数只有13亿多,但时间较长的task输入的记录数是230多亿
- 2、确定任务卡住的stage:
- 1、通过jobname确定stage:一般 Hive 默认的 jobname 名称会带上 stage 阶段,如下通过 jobname 看到任务卡住的为 Stage-4

- 2、如果jobname是自定义的,那么需要通过task执行日志来确定stage,如图,图中的关键信息是:struct<_col0:string, _col1:string, _col3:string>

- 3、同时需要查看sql的执行计划,通过对照参数信息确定stage,如图:
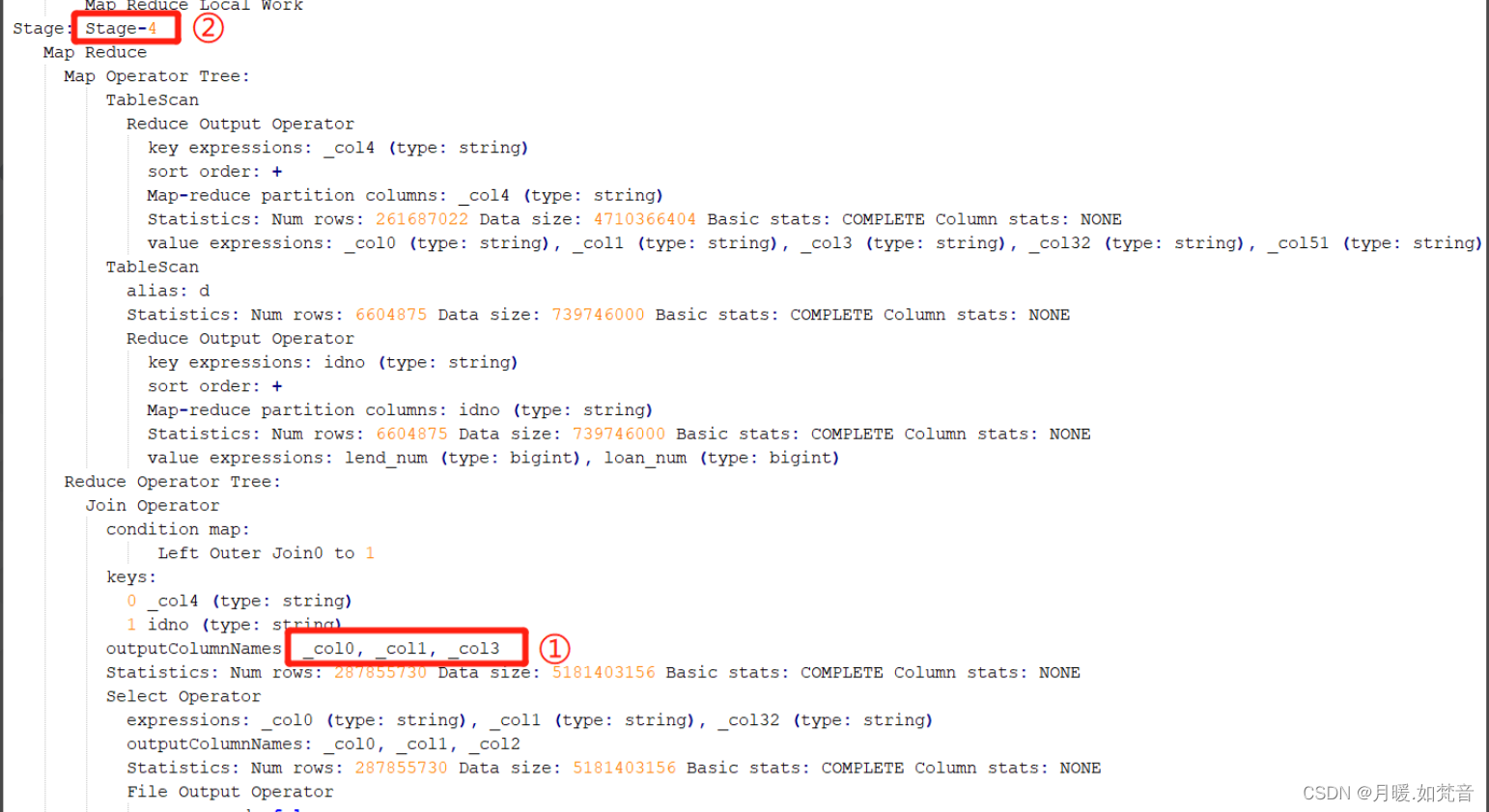
- 4、确定了执行阶段,再通过表的别名判断出在哪个阶段产生了数据倾斜,如图,在这个stage中进行连接的表别名是d

- 5、确定了表名,再对照sql,可以确定是图中关联的地方产生了数据倾斜
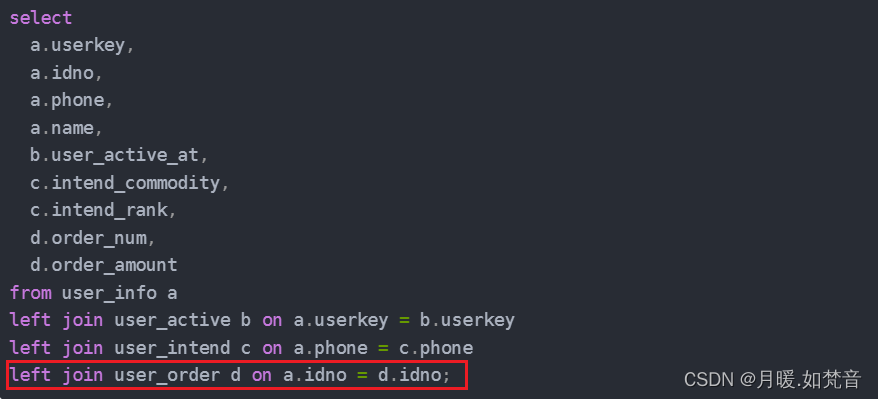
- 6、倾斜原因:产生倾斜的地方是用户基本信息表和用户订单表使用身份证号进行关联,查询用户基本信息表后发现idno字段为null的数据比较多,所以关联的时候导致了数据倾斜
3、解决数据倾斜
- 1、可以将用户基本信息表中idno字段为空的数据过滤之后再进行关联,此处可以直接在表关联条件直接添加where条件进行过滤,因为hive会进行谓词下推,即先进行条件判断再进行关联
select
a.userkey,
a.idno,
a.phone,
a.name,
b.user_active_at,
c.intend_commodity,
c.intend_rank,
d.order_num,
d.order_amount
from user_info a
left join user_active b on a.userkey = b.userkey
left join user_intend c on a.phone = c.phone
left join user_order d on a.idno = d.idno where a.idno is not null;
- 2、对基本信息表中的idno字段进行随机赋值,但随机值不能和表中的数据相同
4、其它解决数据倾斜的方案
- 1、如果导致数据倾斜的大key是一些无意义的数据,可以直接进行过滤,但在本例中的idno字段具有实际意义,不能直接过滤
- 2、数据预处理:对产生数据倾斜的字段进行随机赋值,尽量保证为同一个值的key不要出现太多
- 3、增加reduce数量:如果一条sql中出现了多个大key,可以适当增加reduce数量,这样会尽可能的降低大key落在同一个reduce的概率
- 4、转换为mapjoin:如果是小表和大表进行关联,可以启用map join
set hive.auto.convert.join = true; 是否开启自动mapjoin,默认是true
set hive.mapjoin.smalltable.filesize=100000000; mapjoin的表size大小
- 5、启用倾斜连接优化:hive中可以通过调整参数,将超过设置数量的key认定为倾斜连接,然后将sql分为两个job进行处理。设置skewjoin.key时需要先对业务中的数据两进行计算,设置一个合适的值进行倾斜化判断
set hive.optimize.skewjoin=true; 启用倾斜连接优化
set hive.skewjoin.key=200000; 超过20万行就认为该键是偏斜连接键
- 6、调整内存设置:某些时候,因为数据量较大的原因,sql运行需要的内存较大,会因为内存超限被kill掉,这个时候需要调整内存设置,保证任务能够正常跑起来。这个设置不能保证明显降低job运行时间
set mapreduce.reduce.memory.mb=5120; 设置reduce内存大小
set mapreduce.reduce.java.opts=-Xmx5000m -XX:MaxPermSize=128m;