以
tb_user
表为例,我们先来查看一下之前
tb_user
表所创建的索引。
在
tb_user
表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:
profession
,
age
,
status
。
对于最左前缀法则指的是,查询时,最左变的列,也就是
profession
必须存在,否则索引全部失效。而且中间不能跳过某一列,否则该列后面的字段索引将失效。 接下来,我们来演示几组案例,看一下具体的执行计划:
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';

explain select * from tb_user where profession = '软件工程' and age = 31;

explain select * from tb_user where profession = '软件工程';

以上的这三组测试中,我们发现只要联合索引最左边的字段
profession
存在,索引就会生效,只不
过索引的长度不同。 而且由以上三组测试,我们也可以推测出
profession
字段索引长度为
47
、
age
字段索引长度为
2
、
status
字段索引长度为
5
。
explain select * from tb_user where age = 31 and status = '0';

explain select * from tb_user where status = '0';

而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引左边的列
profession
不存在。
explain select * from tb_user where profession = '软件工程' and status = '0';

上述的
SQL
查询时,存在
profession
字段,最左边的列是存在的,索引满足最左前缀法则的基本条
件。但是查询时,跳过了
age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索 引的长度就是47
。
6.3 范围查询
联合索引中,出现范围查询
(>,<)
,范围查询右侧的列索引失效。
explain select * from tb_user where profession = '软件工程' and age > 30 and status
= '0';

当范围查询使用
>
或
<
时,走联合索引了,但是索引的长度为
49
,就说明范围查询右边的
status
字
段是没有走索引的。
explain select * from tb_user where profession = '软件工程' and age >= 30 and
status = '0';

当范围查询使用
>=
或
<=
时,走联合索引了,但是索引的长度为
54
,就说明所有的字段都是走索引的。
所以,在业务允许的情况下,尽可能的使用类似于
>=
或
<=
这类的范围查询,而避免使用
>
或
<
。
6.4 索引失效情况
6.4.1 索引列运算
不要在索引列上进行运算操作, 索引将失效。
在
tb_user
表中,除了前面介绍的联合索引之外,还有一个索引,是
phone
字段的单列索引。
A. 当根据phone字段进行等值匹配查询时, 索引生效。
explain select * from tb_user where phone = '17799990015';

B. 当根据phone字段进行函数运算操作之后,索引失效。
explain select * from tb_user where substring(phone,10,2) = '15';

6.4.2 字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
接下来,我们通过两组示例,来看看对于字符串类型的字段,加单引号与不加单引号的区别:
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= 0;

explain select * from tb_user where phone = '17799990015';
explain select * from tb_user where phone = 17799990015;

经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。 \
6.4.3 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
接下来,我们来看一下这三条
SQL
语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据
profession
字段查询,符合最左前缀法则,联合索引是可以生效的,我们主要看一下,模糊查询时,
%
加在关键字之前,和加在关键字之后的影响。
explain select * from tb_user where profession like '软件%';
explain select * from tb_user where profession like '%工程';
explain select * from tb_user where profession like '%工%';

经过上述的测试,我们发现,在
like
模糊查询中,在关键字后面加
%
,索引可以生效。而如果在关键字前面加了
%
,索引将会失效。
6.4.4 or连接条件
用
or
分割开的条件, 如果
or
前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select * from tb_user where id = 10 or age = 23;
explain select * from tb_user where phone = '17799990017' or age = 23;

由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
然后,我们可以对
age
字段建立索引。
create index idx_user_age on tb_user(age);

建立了索引之后,我们再次执行上述的SQL语句,看看前后执行计划的变化。

最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
6.4.5 数据分布影响
如果
MySQL
评估使用索引比全表更慢,则不使用索引。
select * from tb_user where phone >= '17799990005';
select * from tb_user where phone >= '17799990015';

经过测试我们发现,相同的
SQL
语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为
什么呢?
就是因为
MySQL
在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。 因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
接下来,我们再来看看 is null 与 is not null 操作是否走索引。
执行如下两条语句 :
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;

接下来,我们做一个操作将profession字段值全部更新为null。

然后,再次执行上述的两条
SQL
,查看
SQL
语句的执行计划。
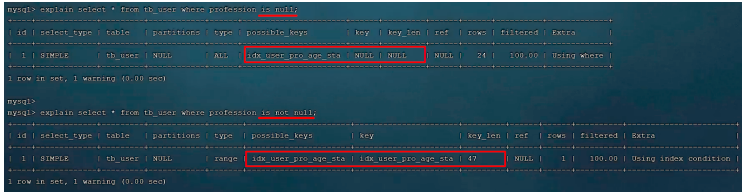
最终我们看到,一模一样的
SQL
语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象,这是和数据库的数据分布有关系。查询时
MySQL
会评估,走索引快,还是全表扫描快,如果全表扫描更快,则放弃索引走全表扫描。 因此,
is null
、
is not null
是否走索引,得具体情况具体
分析,并不是固定的。
♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家



