决策树
决策树是机器学习中一种最为常见的算法。顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面对决策问题时一种很自然的处理机制。决策树的生成算法可以说是信息论的一种应用,但它其实只用到了信息论中的一小部分思想。因此对信息论有个基础性的理解时很有必要的。
基本原理
1、信息论
1.1 信息论简介
信息论创始人克劳德·埃尔伍德·香农被公认为是二十世纪最聪明的人之一。他在1948年发表的划时代的论文——“通讯的数学原理”奠定了现代信息论的基础。
信息论主要内容可类比语言来阐述,通常具有以下两个重要特点。
- 最常用的词汇(如:“的”、“好”、“行”)应该要比相对而言不太常用的词(如“自行车”、“宇宙”、“地球”)更短一些。
- 如果句子的某一部分被漏听或者由于噪声干扰(比如身处闹市)而被误听,听者应该仍可以抓住句子的大概意思。该特点也被称为“鲁棒性(Robustness)”。
需要注意的一点是,信息论不会考虑一段消息的重要性或内在意义,比如像“救命”这样的话显然比“你好”这样的话更重要也更有意义,而信息论只会关注信息量和可读性方面的问题。
既然关注的是信息量,就需要定义一种信息量的度量方法。决策树生成算法背后的思想正是利用该度量方法衡量一种数据划分的优劣,从而生成一个“判定序列”。具体而言,它会不断寻找最优的数据划分,使得在该划分下获得的信息量最大。这也正是决策树的精髓所在。
1.2 不确定性
在决策树的生成中,获得信息量的度量方法是从反方向来定义的:若一种划分使得“不确定性”减少的越多,即意味着该划分获取的信息信息就越多。至此,关键问题就在于如何度量数据的不确定性(或说不纯度Impure)。常见的信息量度量标准有两个:信息熵(Entropy)和基尼系数(Gini index)。
1.2.1 信息熵
信息熵基本公式为:
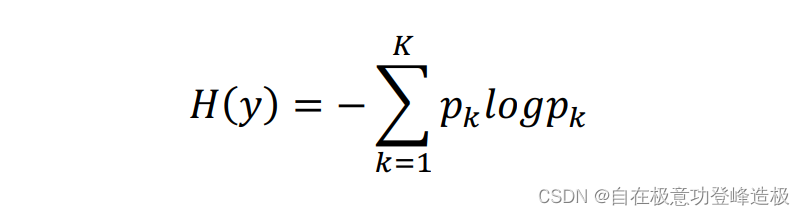
在实际使用中经常采用经验熵来估计信息熵(其思想也就是“频率估计概率”):
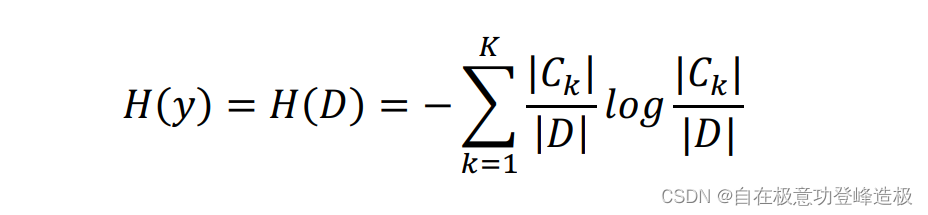
上式假设随机变量
y
y
y的取值空间为
c
1
,
c
2
,
…
,
c
k
{c_1,c_2,…,c_k}
c1,c2,…,ck,
p
k
p_k
pk表示
y
y
y取
c
k
c_k
ck的概率:
p
k
=
p
(
y
=
c
k
)
p_k=p(y=c_k)
pk=p(y=ck),
∣
C
k
∣
|C_k |
∣Ck∣代表随机变量
y
y
y中类别为
c
k
c_k
ck的个数,
∣
D
∣
|D|
∣D∣代表
D
D
D的总样本个数。
一般而言,公式中对数的底会取为2,此时信息熵H(y)的单位叫做比特(bit);如果把底数取为e(即取自然对数)的话,
H
(
y
)
H(y)
H(y)的单位就叫做纳特(nat)
那么上述公式是如何来度量不确定性的?可以证明当以下条件成立时:
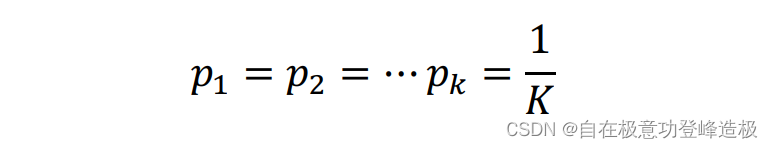
H
(
y
)
H(y)
H(y)达到最大值
−
l
o
g
1
/
K
-log 1/K
−log1/K、亦即
l
o
g
K
logK
logK。由于
p
k
=
(
y
=
c
k
)
p_k=(y=c_k)
pk=(y=ck),上式意味着随机变量
y
y
y取每一个类的概率是相同的,亦即
y
y
y完全没有规律可循,若像预测它的取值只能靠运气。而我们的目的是让y的不确定性减小、亦即让
y
y
y变得有规律可循,以方便我们预测。严格来说,就是
y
y
y取某个类的概率特别大,取其他类的概率特别小。极端的例子自然就是存在某个
k
∗
k^*
k∗,使得
p
(
y
=
c
(
k
∗
)
)
=
1
p(y=c_{(k^* )} )=1
p(y=c(k∗))=1、
p
(
y
=
c
k
)
=
0
p(y=c_k )=0
p(y=ck)=0,
∀
k
≠
k
∗
∀k≠k^*
∀k=k∗,亦即
y
y
y生成的样本总属于
c
(
k
∗
)
c_(k^* )
c(k∗)类。带入
H
(
y
)
H(y)
H(y)的定义式,可以发现此时
H
(
y
)
=
0
H(y)=0
H(y)=0,亦即
y
y
y生成的样本没有不确定性。
接下来举个二分类的例子,加深一下对于信息熵的理解。即
K
=
2
K=2
K=2时。不妨先假设
y
y
y只取0、1二值,再设:
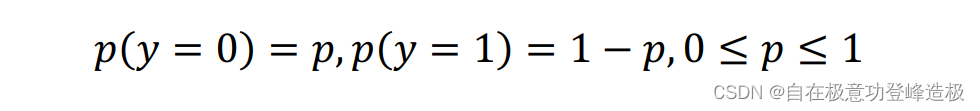
那么此时的信息熵:
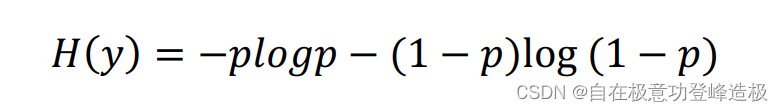
由此可以得到
H
(
y
)
H(y)
H(y)随
p
p
p变化的函数曲线如下图所示(这里对数取底数为2)。
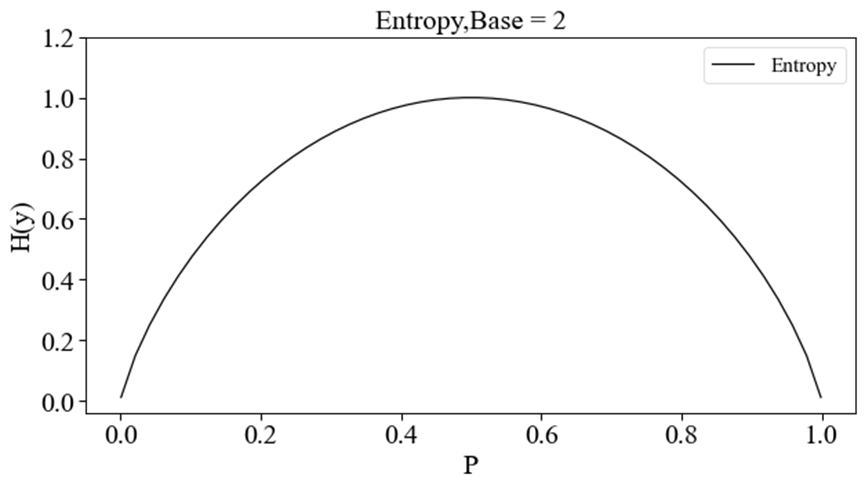
该图说明:随着这两类样本的分离的难易程度(
p
p
p与
1
−
p
1-p
1−p越接近越不容易分离,亦即
p
=
0.5
p=0.5
p=0.5时
H
(
y
)
H(y)
H(y)达到最大),信息熵
H
(
y
)
H(y)
H(y)呈现先增加后减少的变化趋势。
以上的叙述说明,
y
y
y越乱意味着
H
(
y
)
H(y)
H(y)越大,
y
y
y越有规律意味着
H
(
y
)
H(y)
H(y)越小,亦即
H
(
y
)
H(y)
H(y)确实是可以作为不确定性的度量标准,从而可以作为信息的度量方法。
1.2.2 基尼系数
基尼系数基本公式为:
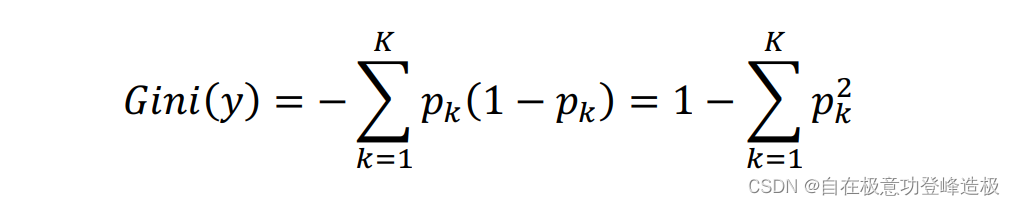
在实际使用中经常采用经验基尼系数来进行估计:
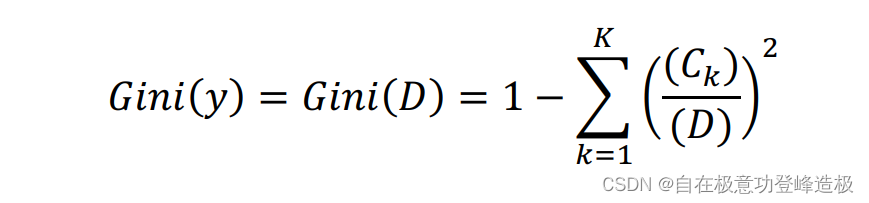
与信息熵类型,同样可以证明,当
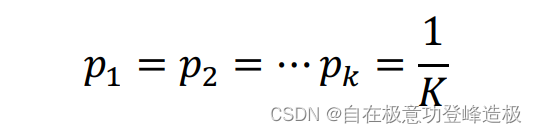
是,
G
i
n
i
(
y
)
Gini(y)
Gini(y)取得最大值
1
−
1
/
K
1-1/K
1−1/K;当存在
k
∗
k^*
k∗使得
k
∗
=
1
k^*=1
k∗=1、
G
i
n
i
(
y
)
=
0
Gini(y)=0
Gini(y)=0。
这里再次以上述二分类为例子,即当
K
=
2
K=2
K=2时可以导出:
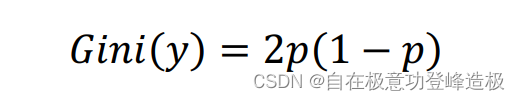
此时
G
i
n
i
(
y
)
Gini(y)
Gini(y)随
p
p
p变化的函数曲线如下图所示。
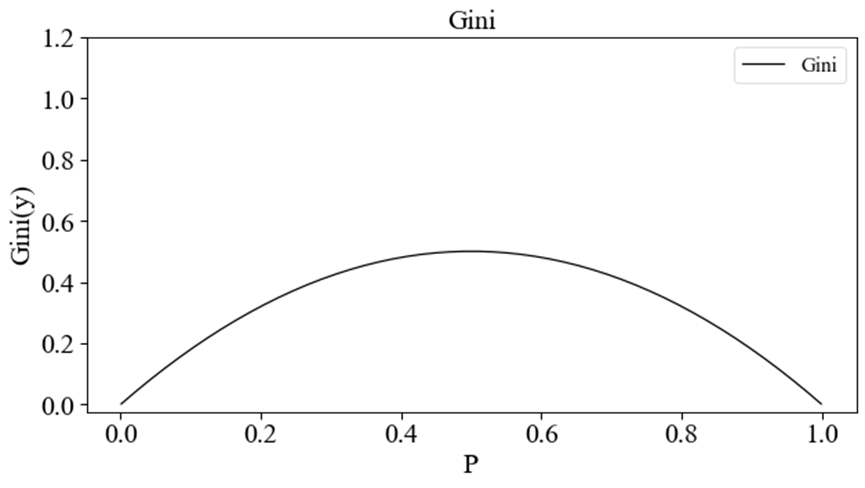
同理,基尼系数也可以作为信息的度量方法。
1.2.3 信息增益
在定义好不确定性的度量标准后,我们便把问题转向了如何来获取“信息量”的大小。为加深直观印象,先假设数据集
D
=
(
x
1
,
y
1
)
,
…
,
(
x
n
,
y
n
)
D={(x_1,y_1 ),…,(x_n,y_n)}
D=(x1,y1),…,(xn,yn),其中
x
i
=
(
x
i
1
,
…
x
i
n
)
x_i=(x_i1,…x_in)
xi=(xi1,…xin)是描述
x
i
x_i
xi的
n
n
n维特征。此时以
x
i
x_i
xi的第
m
(
m
<
n
)
m(m<n)
m(m<n)个特征
x
i
m
x_{im}
xim为例,那么所谓的信息增益,反映的就是特性
x
i
m
x_{im}
xim所能带来的关于
y
i
y_i
yi的“信息量”大小。
可以引入条件熵
H
(
y
│
A
)
H(y│A)
H(y│A)的概念来定义信息增益。所谓条件熵,就是在
x
i
x_i
xi第
m
m
m个特征
x
i
m
x_{im}
xim的不同取值限制下的各个部分的不确定性以取值本身的概率加权求和的计算结果。(可以这么理解,假设
Y
Y
Y的某个特征
A
A
A由
m
m
m个取值,即
A
=
a
1
,
…
a
m
A={a_1,…a_m }
A=a1,…am,依次用这些特征对
y
y
y限制,分别计算被其限制的
y
y
y的信息熵,再把这些信息熵根据限制特征本身的概率加权求和,即得到条件熵)
我们先认可该结论:条件熵
H
(
y
│
A
)
H(y│A)
H(y│A)越小,就意味着
y
y
y被
A
A
A限制后的总的不确定性越小,从容决策的结果更加有可信度。
条件熵的数学定义如下:
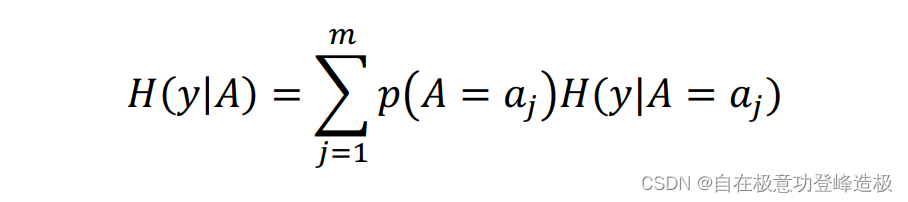
其中
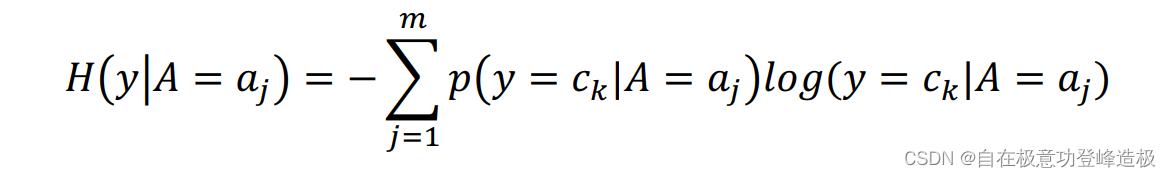
同样用经验条件熵来估计条件熵:
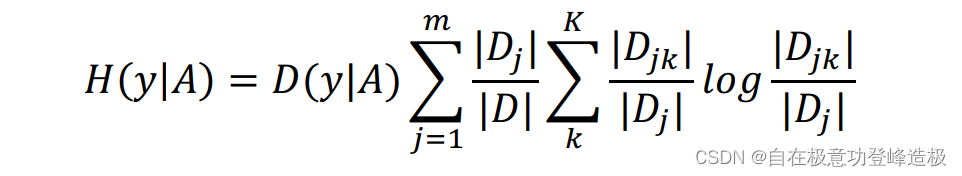
从条件熵出发,我们先定义互信息(
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)