前言
- 在项目中,上传大文件往往会遇上很多问题,比如:
- 1、超时和请求体大小限制;一般我们使用Nginx,它对每个HTTP连接时间和请求内容大小限制的,这些配置值不建议设置很大。
- 2、网络中断;比如突然断网了,那么整个大文件要重新上传。
- 3、用户体验差;直接HTTP上传大文件耗时长,用户只能等待,没有友好的上传进度提示。
- 如果我们将一个大文件拆分成多个文件上传,就能解决上面的问题了。这就是本文主要讲的
分片。
整体思路
前端
- 1、将文件转为
ArrayBuffer对象。
- 2、利用
SparkMD5根据文件内容生成 hash 值。
SparkMD5 GitHub 地址 https://github.com/satazor/js-spark-md5
安装命令:npm install --save spark-md5
- 3、设置每个分片大小,生成切片。
- 4、发送上传切片的请求。
后端
- 1、接收前端传输的数据,设定好保存的位置。
- 2、把分片内容追加到文件上。
代码实现
前端
// 调用这个方法
async chunkUploadFile(){
try{
// 这是File对象
const fileObj = this.uploadFile
const buffer = await this.fileToBuffer(fileObj)
console.log("getFileBuffer ",buffer,fileObj)
const {hash,chunkList,chunkSize,chunkListLength} = this.createChunk(fileObj,buffer)
this.sendRequest(chunkList,hash,chunkSize,chunkListLength)
}catch(e){
console.log(e)
}
},
// 将 File 对象转为 ArrayBuffer
fileToBuffer(file) {
return new Promise((resolve, reject) => {
const fr = new FileReader()
fr.onload = e => {
resolve(e.target.result)
}
fr.readAsArrayBuffer(file)
fr.onerror = () => {
reject(new Error('转换文件格式发生错误'))
}
})
},
createChunk(fileObj,buffer){
// 将文件按固定大小(2M)进行切片,注意此处同时声明了多个常量
const chunkSize = 2097152,
chunkList = [], // 保存所有切片的数组
chunkListLength = Math.ceil(fileObj.size / chunkSize), // 计算总共多个切片
suffix = /\.([0-9A-z]+)$/.exec(fileObj.name)[1] // 文件后缀名
// 根据文件内容生成 hash 值
const spark = new SparkMD5.ArrayBuffer()
spark.append(buffer)
const hash = spark.end()
// 生成切片,这里后端要求传递的参数为字节数据块(chunk)和每个数据块的文件名(fileName)
let curChunk = 0 // 切片时的初始位置
for (let i = 0; i < chunkListLength; i++) {
const item = {
chunk: fileObj.slice(curChunk, curChunk + chunkSize),
fileName: `${hash}_${i}.${suffix}`, // 文件名规则按照 hash_1.jpg 命名
chunkNumber: i,
}
curChunk += chunkSize
chunkList.push(item)
}
console.log("chunkList",chunkList)
return {chunkList:chunkList,hash:hash,chunkSize:chunkSize,chunkListLength:chunkListLength}
},
// 发送请求是同步的,这样更简单
sendRequest(chunkList,hash,chunkSize,chunkListLength) {
let _vm = this
const requestList = [] // 请求集合
chunkList.forEach(item => {
const fn = () => {
const formData = new FormData()
// 分片文件
formData.append('file', item.chunk)
// 文件hash值
formData.append("hash",hash)
// 把文件放到哪个文件夹下
formData.append("folder","live")
// 每个分片大小
formData.append("chunkSize",chunkSize)
// 第几个分片
formData.append("chunkNumber",item.chunkNumber)
// 分片总数
formData.append("chunkListLength",chunkListLength)
// 分片名称
formData.append('fileName', item.fileName)
return _vm.$axios({
url: '/api/common/chunkUploadFile',
method: 'post',
headers: { 'Content-Type': 'multipart/form-data' },
data: formData
}).then(res => {
if (res.data.success) { // 成功
// 进度
const percentCount = item.chunkNumber / chunkListLength
console.log("percentCount ",percentCount);
}
})
}
requestList.push(fn)
})
let i = 0 // 记录发送的请求个数
const send = async () => {
if (i >= requestList.length) {
// 发送完毕
this.uploadComplete()
return
}
await requestList[i]()
i++
send()
}
send() // 发送请求
},
uploadComplete(){
console.log("发送视频完毕");
},
后端代码
@ApiModel("分片文件上传对象")
@Data
public class ChunkUploadFileDto {
@ApiModelProperty(value = "分片文件")
@NotNull(message = "请上传分片文件")
@JSONField(serialize = false)
private MultipartFile file;
@NotBlank(message = "文件夹不能为空")
@ApiModelProperty("把分片数据上传到哪个文件夹")
private String folder;
@NotBlank(message = "文件hash为空")
@ApiModelProperty("文件hash")
private String hash;
@NotBlank(message = "文件名称不能为空")
@ApiModelProperty("文件名称")
private String fileName;
@NotNull(message = "每个分片大小不能为空")
@ApiModelProperty("每个分片大小")
private Integer chunkSize;
@NotNull(message = "当前分片编号不能为空")
@ApiModelProperty("当前分片编号")
private Integer chunkNumber;
@NotNull(message = "总分片次数不能为空")
@ApiModelProperty("总分片次数")
private Integer chunkListLength;
}
@RestController
@RequestMapping("/common")
@Api(tags = "通用处理请求")
public class CommonController {
@PostMapping("/chunkUploadFile")
@ApiOperation("分片上传文件")
public R<Void> chunkUploadFile(@Validated ChunkUploadFileDto chunkUploadFileDto) {
log.info("分片上传文件 [ {} ]", chunkUploadFileDto.getFileName());
// FileStorageService 是文件存储策略 ,目前有本地和OSS
FileStorageService fileStorageService = applicationContext.getBean(sysConfigService.selectConfigByKey(SysConfig.RESOURCE_FILE_CONFIGURE), FileStorageService.class);
return fileStorageService.chunkUploadFile(chunkUploadFileDto);
}
}
/**
* @author Zhou Zhongqing
* @ClassName FileUploadService
* @description: 文件存储的service
* @date 2022-08-15 15:40
*/
public interface FileStorageService {
public final String UNKNOWN = "unknown";
/***
* 分片上传文件
* @param chunkUploadFileDto
* @return
*/
R<Void> chunkUploadFile(ChunkUploadFileDto chunkUploadFileDto);
}
// 本地上传策略
/**
* @author Zhou Zhongqing
* @ClassName LocalFileStorageServiceImpl
* @description: 本地存储策略
* @date 2022-08-15 16:13
*/
@Service(value = "localFileStorageServiceImpl")
public class LocalFileStorageServiceImpl implements FileStorageService {
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
@Resource
private ISysConfigService sysConfigService;
@Override
public R<Void> chunkUploadFile(ChunkUploadFileDto chunkUploadFileDto) {
String extName = StrUtil.DOT + FileUtil.extName(chunkUploadFileDto.getFileName());
String fileName = (WebSecurityUtils.isLogin() ? WebSecurityUtils.getLoginUser().getId() : UNKNOWN) + Constants.SEPARATOR + chunkUploadFileDto.getFolder() + Constants.SEPARATOR + chunkUploadFileDto.getHash() + extName;
File dest = new File(FileUtil.getTmpDirPath() + fileName);
FileUtil.mkdir(dest.getParentFile().getPath());
appendFileByMappedByteBuffer(dest.getPath(), chunkUploadFileDto);
if (chunkUploadFileDto.getChunkNumber().equals(chunkUploadFileDto.getChunkListLength() - Constants.ONE)) {
//TODO 表示上传完了
}
return R.ok();
}
private boolean appendFileByMappedByteBuffer(String resultFileName, ChunkUploadFileDto param) {
// 分片上传
try (RandomAccessFile randomAccessFile = new RandomAccessFile(resultFileName, "rw");
FileChannel fileChannel = randomAccessFile.getChannel()) {
// 分片大小必须和前端匹配,否则上传会导致文件损坏
long chunkSize = param.getChunkSize().longValue();
// 写入文件
long offset = chunkSize * param.getChunkNumber();
byte[] fileBytes = param.getFile().getBytes();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, offset, fileBytes.length);
mappedByteBuffer.put(fileBytes);
// 释放
unmap(mappedByteBuffer);
} catch (IOException e) {
// log.error("文件上传失败:" + e);
return false;
}
return true;
}
/**
* 释放 MappedByteBuffer
* 在 MappedByteBuffer 释放后再对它进行读操作的话就会引发 jvm crash,在并发情况下很容易发生
* 正在释放时另一个线程正开始读取,于是 crash 就发生了。所以为了系统稳定性释放前一般需要检
* 查是否还有线程在读或写
* 来源:https://my.oschina.net/feichexia/blog/212318
*
* @param mappedByteBuffer mappedByteBuffer
*/
public static void unmap(final MappedByteBuffer mappedByteBuffer) {
try {
if (mappedByteBuffer == null) {
return;
}
mappedByteBuffer.force();
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
try {
Method getCleanerMethod = mappedByteBuffer.getClass()
.getMethod("cleaner");
getCleanerMethod.setAccessible(true);
Cleaner cleaner =
(Cleaner) getCleanerMethod
.invoke(mappedByteBuffer, new Object[0]);
cleaner.clean();
} catch (Exception e) {
e.printStackTrace();
// log.error("MappedByteBuffer 释放失败:" + e);
}
// System.out.println("clean MappedByteBuffer completed");
return null;
});
} catch (Exception e) {
// log.error("unmap error:" + e);
}
}
}
...省略OSS...
执行效果
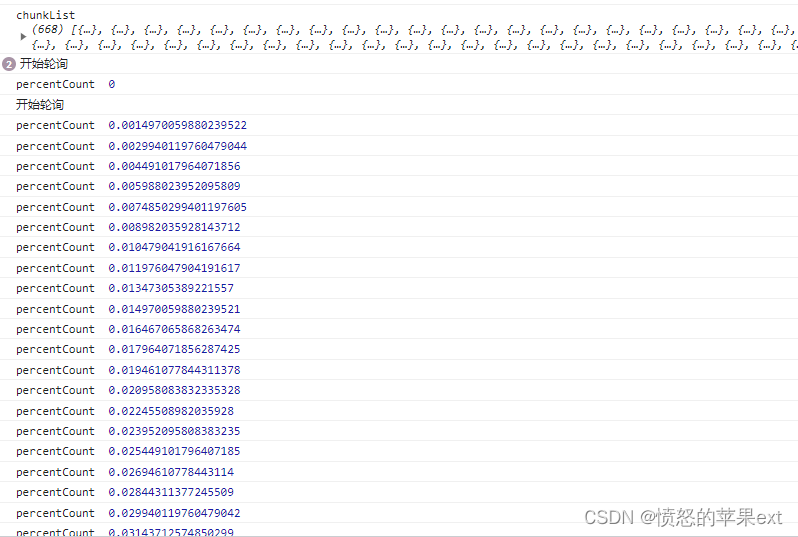
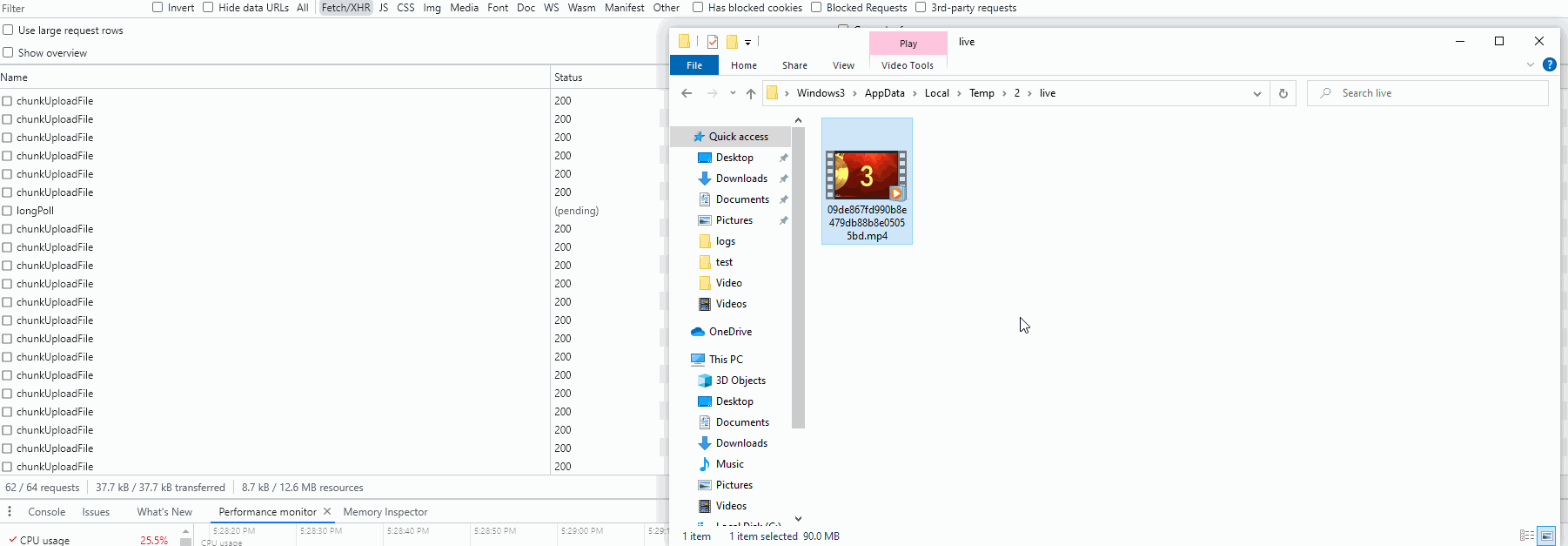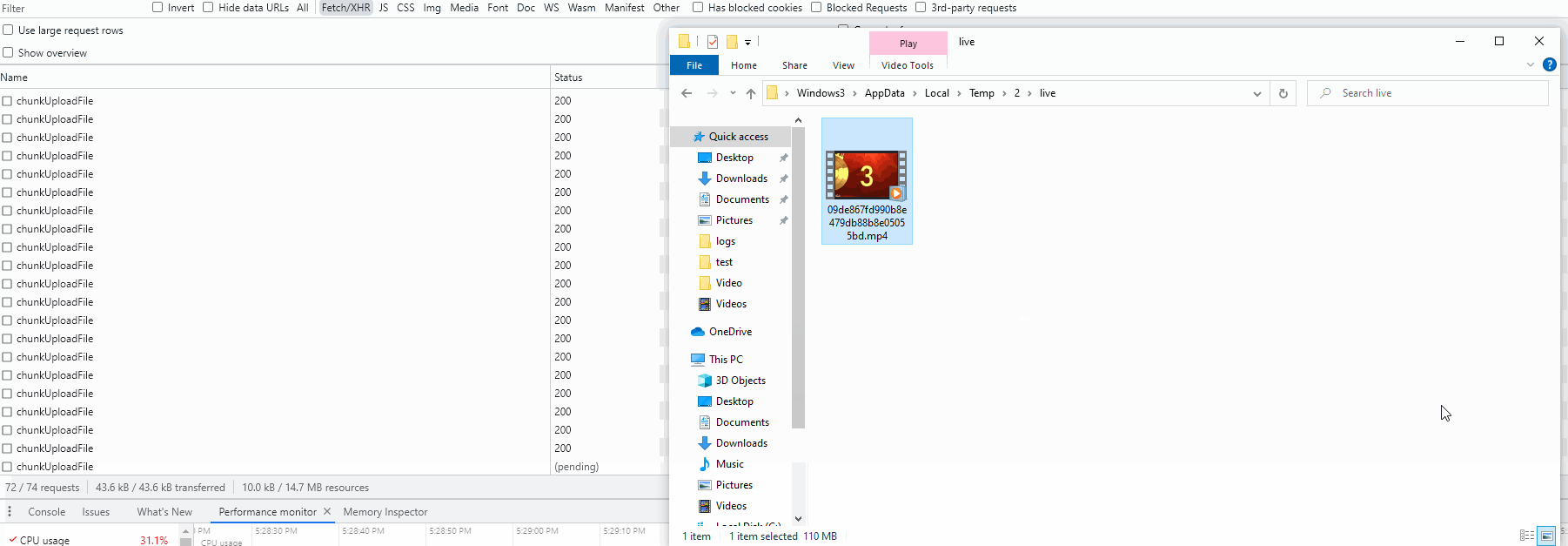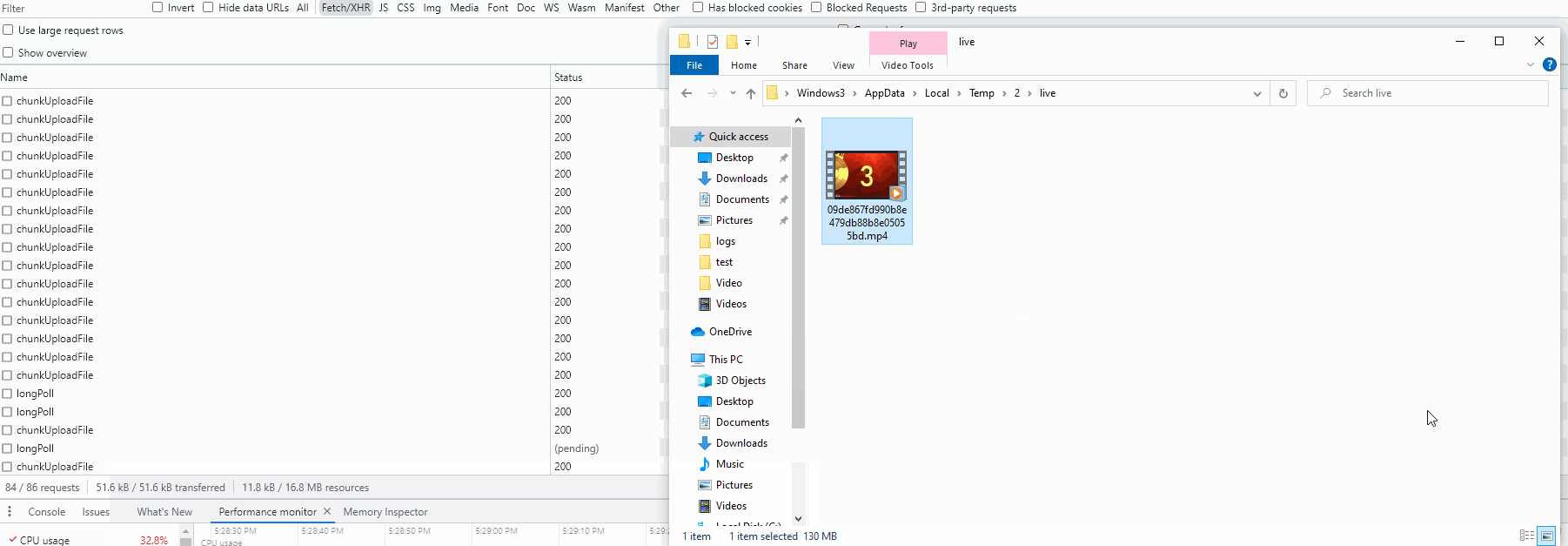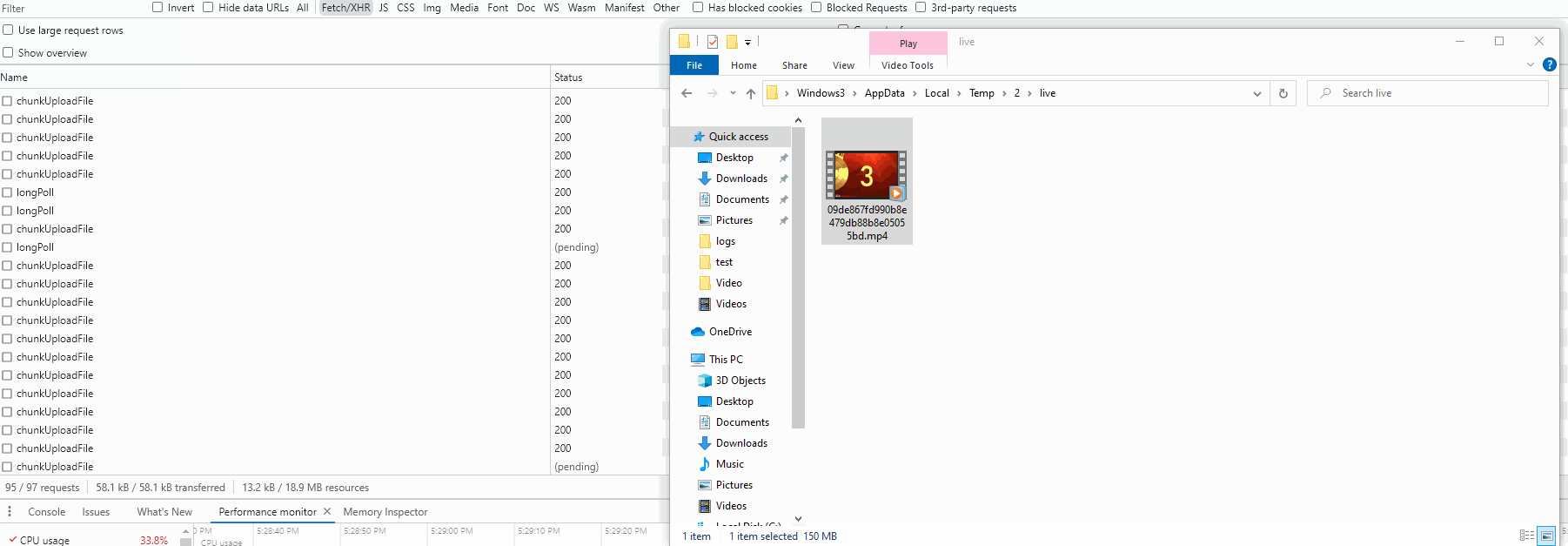
总结
- 以上代码只使用了1个接口,通过追加数据的方式边上传就边合并分片了。另外的一种方式定义2个接口,一个是上传分片,一个是专门合并分片接口,上传完成后,调用合并分片的接口。
- 本文使用同步的方式上传分片,效率并不高,只是代码实现更简单。
其他问题
网络中断,分片上传失败怎么办?
方案1:可以在每个分片上传成功后,做1个标记,保存到Cookie、localStorage之类的地方,也就是实现断点续传。
方案2:把chunkList设置为当前页面对象,每上传成功1个分片就删除1个,重传的逻辑已经是遍历chunkList。
如何实现秒传
服务器端对比文件hash值,如果有则直接返回成功。
服务器端多实例的情况
方案1:需要有1个中心服务,单独抽1个服务处理处理上传文件功能,还可以使用第三方服务比如OSS等等。
方案2:如果使用了Nginx直接代理了后端服务,Nginx配置ip的负载均衡策略。
方案3:上传分片使用WebSocket。
如何删除无用的分片?
- 如果上传到一半,用户直接关闭了页面或浏览器,那么已经上传的分片就无用,如果一直存在就浪费空间。
例如在Linux服务器中,/tmp目录是会定期清理的。所以我的想法是先传到类似/tmp机制的目录,这样就省了我们自己清理无用文件的工序,如果这个文件是有效的再移动到其他目录。
参考