背景介绍:
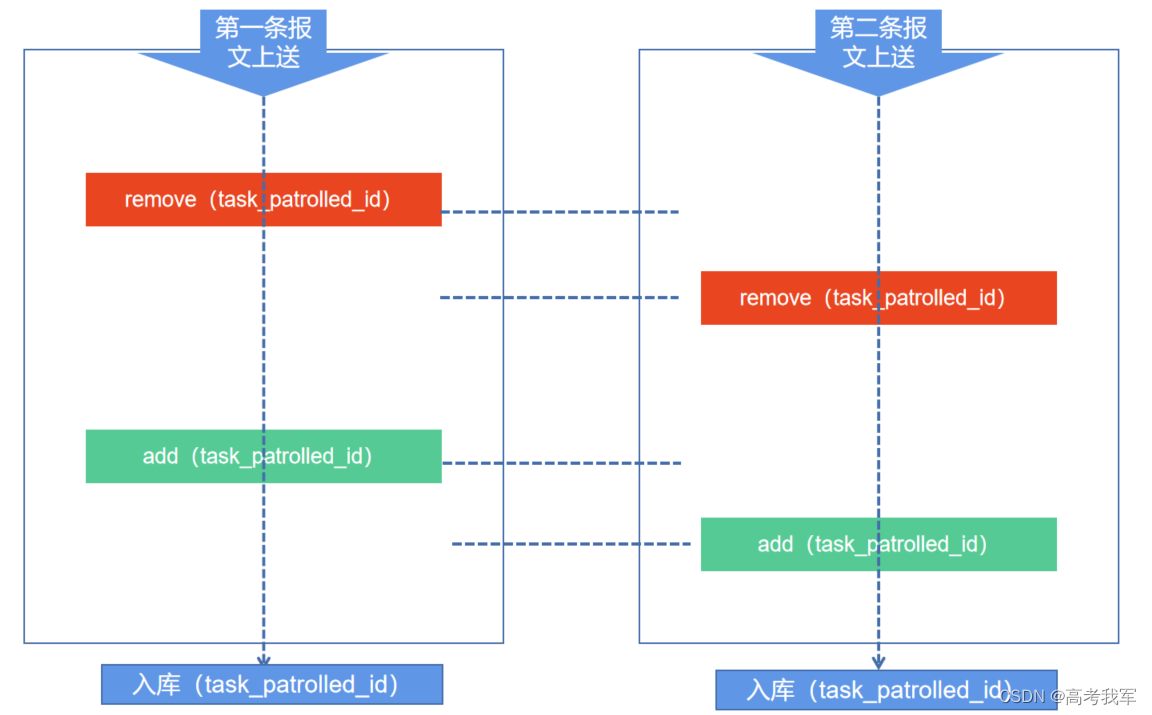
业务场景:服务持续接收巡视任务的状态报文,解析报文后入库。业务处理逻辑:先根据报文中的唯一主键task_patrolled_id删除remove数据库中的表数据,然后再add插入新的数据。
但是现在出现这种情况,两条报文上送上来的时间间隔为2毫秒,导致第一次上送报文的逻辑已经remove掉数据库中的数据,但是还未走到add入库,第一条数据还未入库。
此时第二条报文已经上报上来,在remove的时候,因第一条的add还未完成,导致remove失效,然后在第一条报文add的时候,第二条报文也add了,导致数据库出现两条task_patrolled_id相同的数据
解决方法:
1.在表结构设计时,要把task_patrolled_id作为主键;
ALTER TABLE "public"."t_centralized_mission_state" ADD CONSTRAINT "test_pkey" PRIMARY KEY ("task_patrolled_id" );
这里设置主键时要注意,要先把原有的主键给删除掉,并且把表中,新主键重复的表数据给删除掉才行。
给一个删除表中重复数据的例子:
场景:表 t_centralized_mission_state 是一个任务进度表,每个任务进度都有一个新主键task_patrolled_id,还有update_time表示插入时间。因为有数据同时插入的情况,导致数据出现有重复task_patrolled_id的情况。id是根据 nextval 自动生成的,唯一。
删除重复task_patrolled_id的逻辑:
1.查出 task_patrolled_id 重复的数据,
SELECT *
FROM (
SELECT DISTINCT (task_patrolled_id) ,count(*)
FROM t_centralized_mission_state
GROUP BY task_patrolled_id
) t
WHERE count > 1
2.利用 row_number,获取到 t_centralized_mission_state 表中task_patrolled_id重复的、除了第一条以外的数据
SELECT id
FROM (
SELECT id
,update_time
,task_patrolled_id
,row_number() OVER (PARTITION BY task_patrolled_id) AS row
FROM (
SELECT t1.update_time ,t1.id ,t2.*
FROM t_centralized_mission_state t1
,(
SELECT *
FROM (
SELECT DISTINCT (task_patrolled_id) ,count(*)
FROM t_centralized_mission_state
GROUP BY task_patrolled_id
) t
WHERE count > 1
ORDER BY count DESC
) t2
WHERE t1.task_patrolled_id = t2.task_patrolled_id
ORDER BY t2.task_patrolled_id
) t
) t1
WHERE t1.row > 1
3.根据第二部筛选出来的id进行删除
DELETE
FROM t_centralized_mission_state
WHERE id IN (
SELECT id
FROM (
SELECT id
,update_time
,task_patrolled_id
,row_number() OVER (PARTITION BY task_patrolled_id) AS row
FROM (
SELECT t1.update_time
,t1.id
,t2.*
FROM t_centralized_mission_state t1
,(
SELECT *
FROM (
SELECT DISTINCT (task_patrolled_id)
,count(*)
FROM t_centralized_mission_state
GROUP BY task_patrolled_id
) t
WHERE count > 1
ORDER BY count DESC
) t2
WHERE t1.task_patrolled_id = t2.task_patrolled_id
ORDER BY t2.task_patrolled_id
) t
) t1
WHERE t1.row > 1
)
2.修改先remove再add的逻辑,去掉remove,直接add,但是在add入库的sql语句上做下整改:
INSERT INTO t_centralized_mission_state ( "task_patrolled_id", "task_name", "task_progress" )
VALUES
( '11111', 'task1', 100 ) ON conflict ( task_patrolled_id )
DO UPDATE
SET task_patrolled_id = '11111',
"task_name" = 'task1',
"task_progress" = '100'
其实就是运用了postgresql插入操作遇到唯一值重复时更新,这样只要两次add不是同一时间发生,第二次add就会覆盖第一次的add,保证数据库中数据的唯一性。
当然这只是权宜之计,其实可以将每次报文入库的逻辑,做成队列,队列每次只取一个来执行,这样就可以保证后一次操作和前一次操作不会冲突。
此文章只是为了记录“postgresql插入操作遇到唯一值重复时更新”的处理过程,仅供参考
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)