环境搭建
环境搭建(Vmware)
账号管理
开机关机
目录管理
文件管理
文件操作(touch、cat、tac、more、less、grep、wc、vim)
磁盘管理(iostat、sar、df、du)
内存管理(free)
CPU管理(top)
进程管理
防火墙管理
进阶小故事之CPU深夜狂飙
进阶小故事之轻松分析定位JVM问题
交互工具
环境安装
程序员常用开发命令组合
环境搭建
第一种方式:直接安装Linux操作系统 (会替换掉现有系统)
第二种方式:本机电脑安装成双系统 (windos linux)
第三种方式:虚拟机(VMware下载(360一键安装))
[注]虚拟机搭建环境有两种方式:
a. 下载镜像进行安装
b. 可以使用他人已制作好的镜像
安装VMware虚拟机软件好后打开镜像即可使用
第四种方式:购买云服务器 (有经济来源的话可以购买阿里云服务器,因为这才是最接近公司中原生环境的)
环境搭建(Vmware)
-
安装Vmware
-
创建虚拟机
-
创建新的虚拟机
-
选择自定义(高级)
VMware建立虚拟机分为典型(快速)和自定义(高级)两种方式
-
选择硬件的兼容性
-
选择安装创建的虚拟机的操作系统
-
选择你所要安装的客户机操作系统
-
选择操作系统的版本
-
更改虚拟机的名称和存放的位置
-
选择虚拟机具备的引导设备类型
-
指定处理器数量
-
为虚拟机预设多少内存
-
选择虚拟机的网络类型
-
配置本机网络适配器环境
进入 “控制面板”——“网络和Internet”——“更改适配器设置”
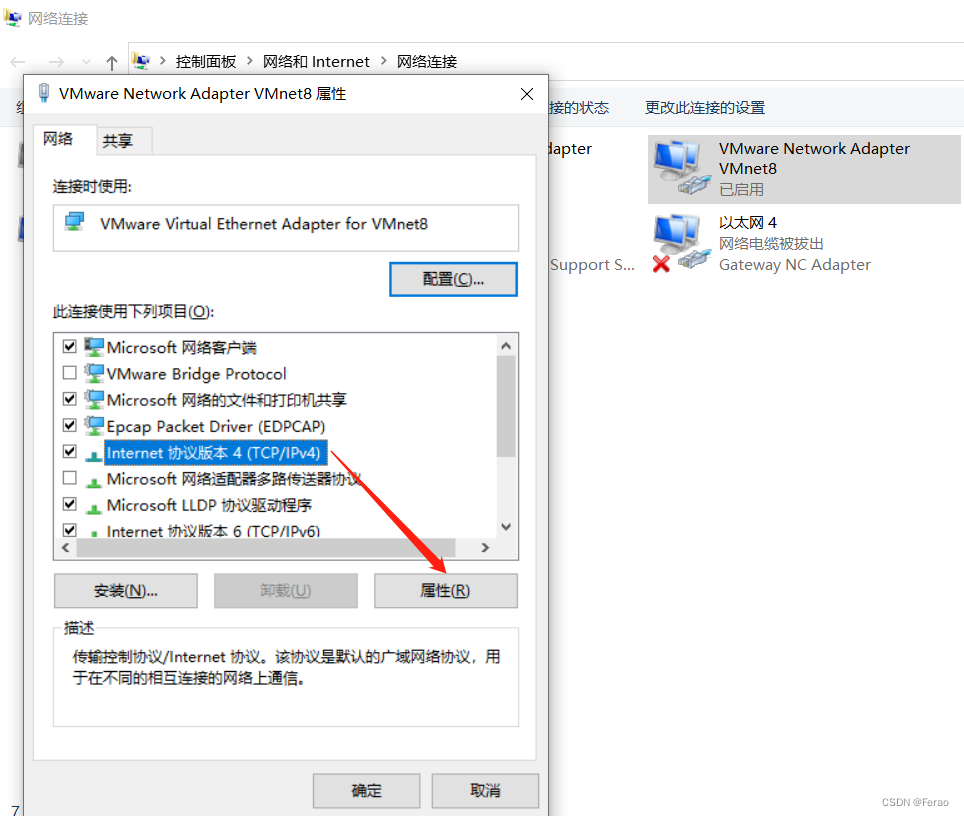
选择VMnet8是配置器,右键选择“属性”,选择“Ipv4”,如下图:
-
配置Vm网络连接
-
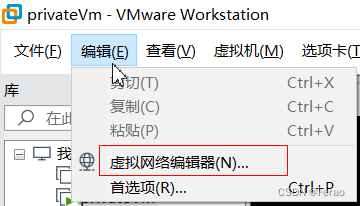
进入虚拟网络编辑器
由于安装VMware虚拟机后是没有网络的,因此我们还需要手动对VMware虚拟机配置网络,选择虚拟机左上方的“编辑–>虚拟网络编辑器”
-
配置虚拟网络地址
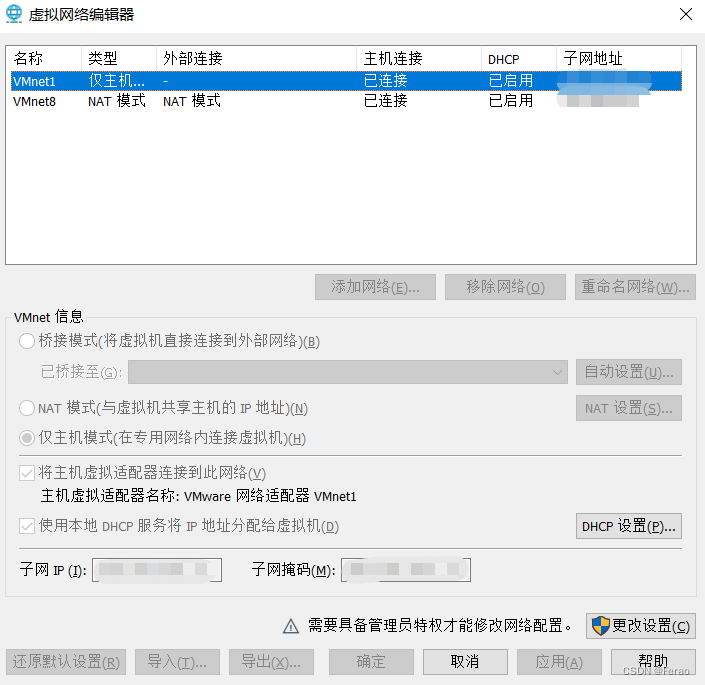
VMnet信息 (虚拟机网络信息)
-
桥接模式
需要依赖外部网络环境,VMware 虚拟出来的操作系统就像是局域网中的一台独立的主机,需要手工为虚拟系统配置IP地址,虚拟机的ip必须和宿主机(Windows)的ip是同一个网段。相当于虚拟机和主机就好比插在同一台交换机上的两台电脑,虚拟机需要占用一个真实ip
-
NAT模式
使用 NAT 模式,就是让虚拟系统借助 NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网,如果主机能够正常上网,那么虚拟机也能够直接上网。此时虚拟机处于一个新的网段内,由VMware提供的DHCP服务自动分配IP地址,然后通过VMware提供的NAT服务,共享主机实现上网, 不依赖外部网络环境
-
仅主机模式
该模式下,虚拟网络是一个全封闭的网络,它唯一能够访问的就是主机,当然多个虚拟机之间也可以互相访问, 但是仅主机模式虚拟机是无法上外网的
-
修改对应的虚拟机镜像的网络环境
找到你需要修改的虚拟机,右键找到“设置”选项,将虚拟机的网络适配器修改为NAT模式,然后保存
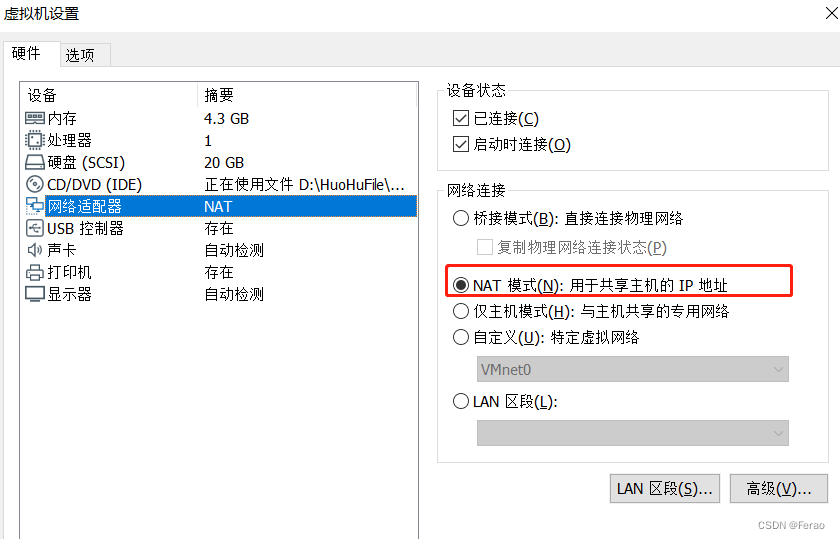
-
修改centos7里边配置网络环境
账号管理
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。每个用户账号都拥有一个唯一的用户名和各自的口令。
用户在登录时键入正确的用户名和口令后,就能够进入系统和自己的主目录。
实现用户账号的管理,要完成的工作主要有如下三个方面:
-
用户账号的添加、删除、修改
-
用户账号的添加(useradd)
添加用户账号就是在系统中创建一个新账号,然后为新账号分配用户名、用户组、主目录和登录 Shell等资源
#添加账号
useradd 选项 用户名
-
用户账号的删除(userdel)
删除用户账号就是要将/etc/passwd等系统文件中的该用户记录删除,必要时还删除用户的主目录。删除命令删除用户在系统文件中(主要是/etc、/etc/shadow…)
#删除已有用户的时候将它的目录页一并删除
userdel -r [文件名]
-
用户账号的修改(usermod)
#常用选项-c/d/m/g/G/s/u/o
usermod -d [文件名]
-
用户口令的管理(su)
#切换用户
su 用户名
#切换用户后使用新用户的工作环境
su - 用户名
#切换到root用户
sudo su
#退回原来用户
exit
#退回原来用户
logout
#退回原来用户,其实也是执行的eixt命令
ctrl + d
-
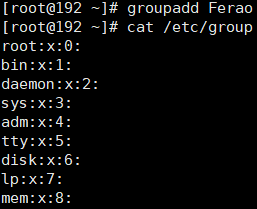
用户组的管理
将用户分组是Linux系统对用户进行管理及控制访问的一种手段。用户组的所有信息都存放在/etc/group文件中。此文件的格式也类似于/etc/passwd文件,由冒号(:)隔开若干个字段,这些字段有(组名:口令:组标识号:组内成员用户列表)
a. 组名是用户组的名称,由字母或数字构成。与/etc/passwd中的登录名一样,组名不应重复
b. 口令字段存放的是用户组加密后的口令字。一般linux系统的用户组都没有口令,即这个字段一般为空,或者是*
c. 组标识号与用户标识号类似,也是一个整数,被系统内部用来标识组
d. 组内用户列表是属于这个组的所有用户的列表,不同用户之间用(,)分隔。这个用户组可能是用户的主组,也可能是附加组
每个用户都属于某个用户组,一个组中可以有多个用户,一个用户可以属于不同的组
当一个用户同时是多个组中成员时,在etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组,用户要访问附加组的文件时,必须首先使用newgrp命令使自己成为所要访问的组中的成员
完成用户的管理工作有许多办法,但是每种办法实际都是对有关系统文件进行修改
#创建一个用户组
groupadd [用户组]
#创建一个用户组并设置id
groupadd -g [数字] [用户组]
#修改旧用户名为新用户名且设置id
group -g [数字] -n [新用户组] [旧用户组]
#删除用户组
groupdel [用户组]
#修改用户组的组标识号
groupmod -g [数字] 用户组
#将旧用户组名修改为新的,并标识号改1000
groupmod -g 1000 -n 新用户组名 旧用户组名
#切换[root]用户组
newgrp root
#查看group文件中组信息
cat /etc/group
#查看所有用户信息
cat /etc/passwd
-
查看系统用户信息
作为系统管理员,你可能经常会(在某个时候)需要查看系统中有哪些用户正在活动。有些时候,你甚至需要知道他(她)们正在做什么。本文为我们总结了4种查看系统用户信息(通过编号(ID))的方法。
-
查看登录用户正在使用的进程信息(w)
w命令用于显示已经登录系统的用户的名称,以及他们正在做的事。该命令所使用的信息来源于/var/run/utmp文件。w命令输出的信息包括:
• 用户名称
• 用户的机器名称或tty号
• 远程主机地址
• 用户登录系统的时间
• 空闲时间(作用不大)
• 附加到tty(终端)的进程所用的时间(JCPU时间)
• 当前进程所用时间(PCPU时间)
• 用户当前正在使用的命令
w命令还可以使用以下选项
• -h忽略头文件信息
• -u显示结果的加载时间
• -s不显示JCPU, PCPU, 登录时间

-
查看登录用户信息(who)
who命令用于列举出当前已登录系统的用户名称。其输出为:用户名、tty号、时间日期、主机地址。
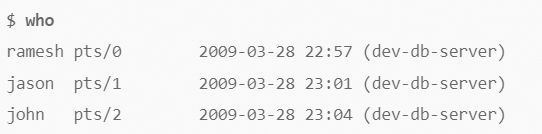
[注]使用whoami命令查看你所使用的登录名称
-
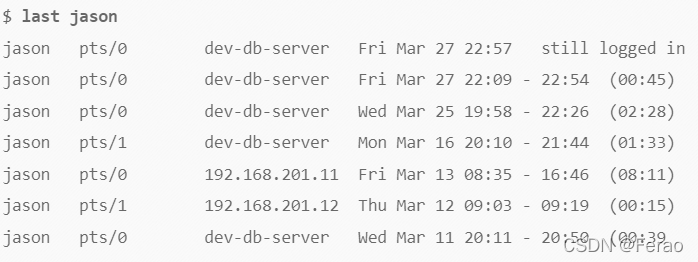
查看曾经使用过系统的历史用户信息(who)
last命令可用于显示特定用户登录系统的历史记录。如果没有指定任何参数,则显示所有用户的历史信息。在默认情况下,这些信息(所显示的信息)将来源于/var/log/wtmp文件。该命令的输出结果包含以下几列信息:
• 用户名称
• tty设备号
• 历史登录时间日期
• 登出时间日期
• 总工作时间
-
用户账号授权(sudo)
简单的说,sudo 是一种权限管理机制,管理员可以授权于一些普通用户去执行一些 root 执行的操作,而不需要知道 root 的密码。
严谨些说,sudo 允许一个已授权用户以超级用户或者其它用户的角色运行一个命令。当然,能做什么不能做什么都是通过安全策略来指定的。sudo 支持插件架构的安全策略,并能把输入输出写入日志。第三方可以开发并发布自己的安全策略和输入输出日志插件,并让它们无缝的和 sudo 一起工作。默认的安全策略记录在 /etc/sudoers 文件中。而安全策略可能需要用户通过密码来验证他们自己。也就是在用户执行 sudo 命令时要求用户输入自己账号的密码。如果验证失败,sudo 命令将会退出。(注意,本文介绍的 sudo 命令运行在 ubuntu 14.04中。)
sudo命令还可以使用以下选项
• -b 在后台执行指令
• -h 显示帮助
• -H 将HOME环境变量设为新身份的HOME环境变量
• -k 结束密码的有效期限,也就是下次再执行sudo时便需要输入密码
• -l 列出目前用户可执行与无法执行的指令
• -p 改变询问密码的提示符号
• -s 执行指定的shell
• -u <用户> 以指定的用户作为新的身份。若不加上此参数,则预设以root作为新的身份
• -v 延长密码有效期限5分钟
• -V 显示版本信息
• -S 从标准输入流替代终端来获取密码
sudo 程序相关文件如下
• /etc/sudoers
• /etc/init.d/sudo
• /etc/pam.d/sudo
• /var/lib/sudo
• /usr/share/doc/sudo
• /usr/share/lintian/overrides/sudo
• /usr/share/bash-completion/completions/sudo
• /usr/bin/sudo
• /usr/lib/sudo
现在了解了这些概念后下一步是进行基本配置:
系统默认创建了一个名为 sudo 的组。只要把用户加入这个组,用户就具有了 sudo 的权限。
至于如何把用户加入 sudo 组,您可以直接编辑 /etc/group 文件,当然您得使用一个有 sudo 权限的用户来干这件事:
$ sudo vim /etc/group
在 sudo 组中加入新的用户,要使用逗号分隔多个用户。
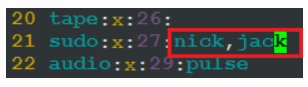
或者您可以使用 usermod 命令把用户添加到一个组中:
$ sudo usermod -a -G sudo jack
上面的设置中我们把用户 jack 添加到了 sudo 组中,所以当用户 jack 登录后就可以通过 sudo 命令以 root 权限执行命令了!
[拓展]详细配置
在前面的配置中我们只是把用户 jack 加入了 sudo 组,他就具有了通过 root 权限执行命令的能力。
现在我们想问一下,这是怎么发生的?是时候介绍如何配置 sudo 命令了!
sudo 命令的配置文件为 /etc/sudoers。
编辑这个文件是有单独的命令的 visudo(这个文件我们最好不要使用 vim 命令来打开),是因为一旦你的语法写错会造成严重的后果,这个工具会替你检查你写的语法,这个文件的语法遵循以下格式:
who where whom command
说白了就是哪个用户在哪个主机以谁的身份执行那些命令,那么这个 where, 是指允许在那台主机 ssh 连接进来才能执行后面的命令,文件里面默认给 root 用户定义了一条规则:
root ALL=(ALL:ALL) ALL
• root 表示 root 用户
• ALL 表示从任何的主机上都可以执行,也可以这样 192.168.100.0/24
• (ALL:ALL) 是以谁的身份来执行,ALL:ALL 就代表 root 可以任何人的身份来执行命令
• ALL 表示任何命令
那么整条规则就是 root 用户可以在任何主机以任何人的身份来执行所有的命令。
现在我们可以回答 jack 为什么具有通过 root 权限执行命令的能力了。打开 /etc/sudoers 文件:

sudo 组中的所有用户都具有通过 root 权限执行命令的能力!
再看个例子
nick 192.168.10.0/24=(root) /usr/sbin/useradd
上面的配置只允许 nick 在 192.168.10.0/24 网段上连接主机并且以 root 权限执行 useradd 命令。
现在设置 sudo 时不需要输入密码
执行 sudo 命令时总是需要输入密码事件很不爽的事情(抛开安全性)。有些应用场景也需要在执行 sudo 时避开输入密码的交互过程。
那么需要如何设置呢?其实很简单,只需要在配置行中添加 NOPASSWD: 就可以了:
****** ALL=(ALL) NOPASSWD: ALL
再试试看,是不是已经不需要输入密码了?
在 ubuntu 中,sudo 的日志默认被记录在 /var/log/auth.log 文件中。当我们执行 sudo 命令时,相关日志都是会被记录下来的。比如下图中显示的就是一次执行 sudo 命令的日志:

开机关机
-
开机登录
方式一 : 命令行登录
方式二 : ssh登录
方式三 : 图形界面登录
[注]开机会启动许多程序。它们在windows中叫"服务"(service),在linux中叫"守护进程"(daemon)
-
关机(shutdown)
在Linux领域内大多用在服务器上,很少遇到关机的操作,不管是重启还是关闭系统,首先要运行sync命令,把内存中的数据同步到磁盘中.
使用关机指令,可以man shutdown 来看一下帮助文档。
#立即关机
shutdown -h now
#计算机将在10分钟后关机
shutdown -h 10
#10分钟后关机
shutdown -h +10
#系统会在今天20:25关机
shutdown -h 20:25
#关机,等同于 shutdown -h now 和 poweroff
halt
-
重启
#系统立即重启
shutdown -r now
#系统10分钟后重启
shutdown -r +10
#重启,等同于 shutdown -r now
reboot
目录管理
-
目录结构
根目录/,所有的文件都挂载在这个节点下,根目录里的结构如下
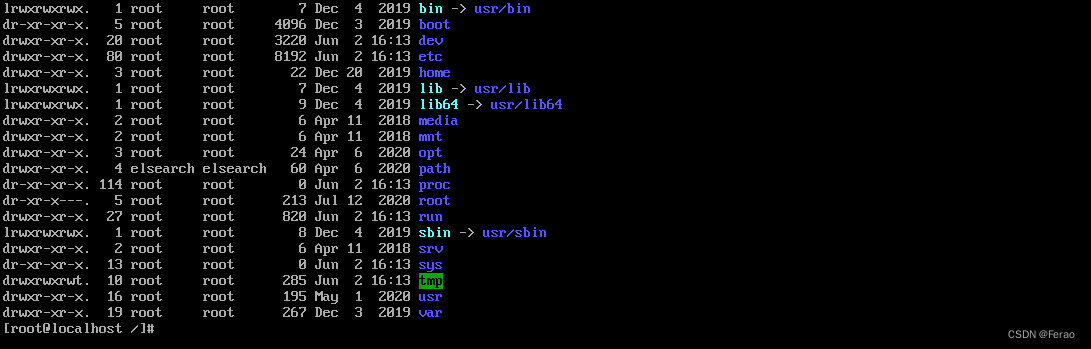
ls是系统目录查看命令,通过ls /命令查看根目录里的内容,各子目录所代表的内容如下:
#binshi Binary的缩写,表示二进制文件,bin目录包含了会被所有用户使用的可执行程序
cd /bin
#包含于linux启动密切相关的文件
cd /boot
#dev是Device(设备)的缩写,表示设备,它里面的子目录每一个对应一个外设,比如我们的光盘驱动器的文件就在这里面
cd /dev
#包含系统的配置文件
cd /etc
#用户的主目录,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的
cd /home
#lib是Library的缩写,表示库,包含被程序所调用的库文件
cd /lib
#这个目录一般情况下是空的,当系统非法关机后,这里就存放一些文件
cd /lost+found
#媒体,可移动的外设(USB盘、SD卡)插入电脑时,Linux可以让我们通过media的子目录来访问这些外设的内容
cd /media
#Mount的缩写,表示挂载,类似media,一般表示临时挂载一些装置
cd /mnt
#这里给主机额外安装软件所摆放的目录。比如开发者安装一个ORALCE数据库则就可以放到这个目录下。默认是空的
cd /opt
#这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息
cd /proc
#超级用户,root的家目录
cd /root
#s就是super user的意思,这里存放的是系统管理员使用的系统管理程序
cd /sbin
#service的缩写,该目录存放一些服务启动之后需要提取的数据
cd /srv
#这是Linux2.6内核的一个很大的变化,该目录下安装2.6内核中新出现的一个文件系统sysfs
cd /sys
#这个目录是用来存放一些临时文件的。用完即丢的文件
cd /tmp
#这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录
cd /usr
#variable的缩写,表示动态的,通常包含程序的数据,比如Log文件
cd /var
这里要注意,“/“是根目录,”~“是家目录。linux存储是以挂载的方式,相当于树状的,源头就是”/”,也就是根目录,而每个用户都有"家"目录,也就是用户的个人目录,比如root用户的"家"目录就是/root,普通用户a的"家"目录就是/home/a。
[注]
8./etc/passwd文件是用户管理工作涉及的最重要的文件
9.linux系统中的每个用户都在/etc/passwd文件中有一个对应的记录行,它记录着用户的一些基本信息,这个文件对所有用户都是可读的
10./etc/passwd中每行记录用(:)分隔为7个字段,其格式和含义是
(用户名:口令:用户账号标识号:组标识号:注释性描述:主目录:登录xshell)
11.口令中一些系统中,存放着加密后的用户口令字

-
目录增删移查命令(mkdir、rmdir、rm、mv、cp)
| 命令 |
描述 |
| pwd |
显示当前所在的目录 |
| mkdir [new_folder] |
创建一个目录 |
| mkdir -p one/two/three |
创建多个目录 |
| rmdir dir1 |
删除指定空目录,如果目录不是空的,会提示错误 |
| rm -rf dir1 |
rm命令通常用于删除Linux中的文件。可以添加参数用来删除目录; -f 强制删除而不提示;-r 递归删除文件夹; -i向用户确认是否删除 |
| mv file one |
移动目录,file 文件移动到 one 目录下; -f 强制移动; -u 只替换已经更新过的文件 |
| cp file file_copy |
复制目录;file 是目标文件,file_copy 是拷贝出来的文件; -r递归拷贝 |
-
列出命令(ls)
#列出目录
ls
#和ls -l效果一样,查看文件属性、权限,没有隐藏文件
ll
#-a参数即all,查看全部的文件,包括隐藏文件
ls -a
#-l参数,列出所有的文件,包括文件的属性和权限,没有隐藏文件
ls -l
#-a和-l的组合,列出所有文件的属性和权限,包括隐藏文件
ls -al
-
查找命令(find)
#列出当前目录及子目录下的所有文件和文件夹,其中. 代表当前文件夹,会递归查找子文件夹
find .
#在/usr目录下查找FeraoRedisConfig文件夹
find /usr -name "FeraoRedisConfig"
#在/usr目录下查找以.txt结尾的文件名,文件名 可用文件全名或*代表不确定部分,如*.sh
find /usr -name "*.txt"
文件操作
-
文件颜色

在上图中每类颜色代表不同含义,含义如下:
• 绿色文件:执行文件,可执行的程序
• 红色文件:压缩文件或者包文件
• 蓝色文件:目录
• 白色文件:普通,如文本文件、配置文件、源码文件等
• 浅蓝色文件:链接文件,主要是使用ln命令建立的文件
• 红色闪烁:表示链接的文件有问题
• 黄色文件:表示设备文件
• 灰色文件:表示其他文件
-
文件权限
linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。
用户有三种不同类型的:文件所有者,同组用户、其他用户。所有者一般是文件或目录的创建者。所有者可以允许同组用户有权访问文件,还可以将文件的访问权限赋予系统中的其他用户。在这种情况下,系统中每一位用户都能访问该用户拥有的文件或目录。
文件或目录的访问权限分为只读,只写和可执行三种。以文件为例,只读权限表示只允许读其内容,而禁止对其做任何的更改操作。可执行权限表示允许将该文件作为一个程序执行。文件被创建时,文件所有者自动拥有对该文件的读、写和可执行权限,以便于对文件的阅读和修改。用户也可根据需要把访问权限设置为需要的任何组合。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。当用ls -l命令显示文件或目录的详细信息时,最左边的一列为文件的访问权限。 例如:
[root@localhost test]# ll -al
总计 316lrwxrwxrwx 1 root root 11 11-22 06:58 linklog.log -> log2012.log
-rw-r--r-- 1 root root 302108 11-13 06:03 log2012.log
-rw-r--r-- 1 root root 61 11-13 06:03 log2013.log
-rw-r--r-- 1 root root 0 11-13 06:03 log2014.log
-rw-r--r-- 1 root root 0 11-13 06:06 log2015.log
-rw-r--r-- 1 root root 0 11-16 14:41 log2016.log
-rw-r--r-- 1 root root 0 11-16 14:43 log2017.log
我们以log2012.log为例:
-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
第一列共有10个位置,第一个字符指定了文件类型(目录、文件或链接文件等等)。在通常意义上,一个目录也是一个文件。换句话说,该列为类型列。
类型列 含义
--------------------------
[d] 目录
[-] 非目录的文件
[l] 链接文档[link file]
[b] 装置文件内可供存储的接口设备(可随机存取装置)
[c] 装置文件内串行端口设备,如键盘(一次性读取装置)
从第二个字符开始到第十个共9个字符,3个字符一组,分别表示了3组用户对文件或者目录的权限。
第一组[rwx]:属主权限,代表该文件的所有者拥有该文件的权限
第二组[rwx]:属组权限,代表所有者的同组用户拥有该文件的权限
第三组[rwx]:其他用户权限,代表其他用户所拥有该文件的权限
权限字符用[-]代表空许可(没有权限)、[r]代表只读(read)、[w]代表写(write)、[x]代表可执行(execute)
示例中:- rw- r-- r--,表示log2012.log是一个普通文件;log2012.log的属主有读写权限;与log2012.log属主同组的用户只有读权限;其他用户也只有读权限。
确定了一个文件的访问权限后,用户可以利用Linux系统提供的命令对访问权限、所有者、用户组进行变更。
chmod命令:重新设定不同的访问权限。
chown命令:更改某个文件或目录的所有者。
chgrp命令:来更改某个文件或目录的用户组。
chmod命令是非常重要的,用于改变文件或目录的访问权限,用它控制文件或目录的访问权限。详细情况如下。
两种用法:
一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
1)文字设定法:
chmod [-cfvR] [who] [+ | - | =] [mode] 文件名
①格式:
chmod <参数> <权限范围>+<权限设置> 使权限范围内的目录或者文件具有指定的权限
chmod <参数> <权限范围>-<权限设置> 删除权限范围的目录或者文件的指定权限
chmod <参数> <权限范围>=<权限设置> 设置权限范围内的目录或者文件的权限为指定的值
②<参数>内容:
-c 当发生改变时,报告处理信息
-f 错误信息不输出
-R 处理指定目录以及其子目录下的所有文件
-v 运行时显示详细处理信息
③<权限范围>内容:
u :代表用户
g :代表用户组
o :代表其他
a :代表所有
④<权限设置>内容:
r :读权限,用数字4表示
w :写权限,用数字2表示
x :执行权限,用数字1表示
- :删除权限,用数字0表示
s :特殊权限
#增加授予这个文件的所属者执行的权限
#chmod <权限范围>+<权限设置> file
chmod u+x somefile
#授予所有用户这个文件的执行权
#chmod <权限范围>+<权限设置> file
chmod +x somefile
chmod a+x somefile
#为所有用户分配读权限
chmod =r file
# 递归地给directory目录下所有文件和子目录的属主分配读的权限
chmod -R u+r directory
2)数字设定法
我们必须首先了解用数字表示的属性的含义:
0 表示没有权限,
1 表示可执行权限,
2 表示可写权限,
4 表示可读权限,
每种身份(owner/group/others)各自的三个权限(r/w/x)分数是需要累加的,数字设定法的一般形式为:
chmod [mode] 文件名
#权限为 [rwxrwx---]
#owner = r w x = 4 + 2 + 1 =7
#group = r w x = 4 + 2 + 1 =7
#others = - - - = 0 + 0 + 0 =0
chmod 770 filename
#权限为 [rwxrwxrwx]
#owner = r w x = 4 + 2 + 1 =7
#group = r w x = 4 + 2 + 1 =7
#others = r w x = 4 + 2 + 1 =0
chmod 777 filename
-
组分类

文件操作
-
创建文件命令(touch)
命令:touch [文件名称]

-
浏览文件(cat、tac、more、less)
| 命令 |
描述 |
示例 |
| cat [文件名称] [辅助指令] |
一次性显示文件所有内容,更适合查看小的文件,常用辅助指令 -n,用来显示行号 |
|
| tac [文件名称] |
由最后一行开始显示文件内容 |
|
| more [文件名称] |
一页一页的显示文件内容 |
|
| less [文件名称] |
一页一页的显示文件内容,更适合查看大的文件,空格下翻页,pageDown、pageUp键代表翻动页面 |
|
| head [辅助指令] [数量] [文件名称] |
查看文件开头内容,默认文件的10行,常用辅助指令 -n,后跟数量指定展示行数 |
|
| tail [辅助指令] [文件名称] |
查看文件末尾内容,默认文件的结尾10行,并实时监控文件,常用辅助命令 -f 会每秒检查文件是否有更新 |
tail -100f cloud-init.log |
#【常用指令】
#/ 键:进入搜索模式,此时按n键跳到下一个符合位置,按N键跳到上一个符合位置,同时也可以输入正则表达式匹配
#d 键:前进半页;
#u 键:后退半页;
#q 键:停止读取文件,中止 less 命令;
#空格键:前进一页(一个屏幕);
#b 键:后退一页;
-
快速查看文件指定内容(grep)
grep 全称是Global Regular Expression Print(全局正则表达式版本),它的使用权限是所有用户。
命令:grep [指定内容] [文件名称] -[辅助指令] [–color]
辅助指令包含:
• A20 :显示匹配行的前20行
• B20 :显示匹配行的后20行
• C20 :显示匹配行前后20行
-
文件内容信息汇总(wc)
该命令统计给定文件中的字节数,字数,行数。如果没有给出文件名,则从标准输入读取.
wc同时也给出所有指定文件的总统计数。字由空格字符区分开的最大字符串。
#查看文件里有多少字节(统计字节数)
wc -c filename
#查看文件里有多少行(统计行数)
wc -l filename
#查看文件里有多少个word(统计字数)
wc -w filename
#文件里最长的哪一行是有多少个字
wc -L filename
-
编辑文件(vim)
vi/vim 打开文件的三种方式:
| 命令 |
作用 |
示例 |
| vim +n filename |
打开文件,并定位到第n行 |
|
| vim + filename |
打开文件,并定位到最后一行 |
|
| vim +/pattern filename |
定位至第一次被pattern匹配到的行的行首 |
vim +/“2019-02-17 23:01:49.994” server.log |
vi/vim 的三种模式:
| 模式 |
描述 |
命令 |
注意 |
| 命令模式(Command mode) |
命令模式是Vim的默认操作模式,当使用vim命令打开一个文件时,默认进入的就是命令模式。不管用户处于何种模式,只要按下Esc键就可使进入命令行模式。 |
进入模式:Esc |
如果这个文件存在,那就是修改这个文件,如果不存在,那就会新建这个文件 |
| 编辑模式(input mode) |
只有在vim编辑模式下,才能将键盘键入的内容输入到当前打开的文件中 |
进入模式: i、a、o ;退出模式:Esc |
|
| 尾行模式(last line mode) |
尾行模式主要用于保存文件或退出Vim,同时也可以设置编辑环境和一些编译工作,如列出行号(set nu)、寻找字符串(/target)等。在命令模式下,用户按冒号键(:)即可进入末行模式下,此时Vi会在显示窗口的最后一行显示一个”:“作为末行模式的提示符,等待用户输入命令。 |
进入模式: :;保存并退出::wq ;强制退出并忽略所有更改::q! ;放弃所有修改,并打开原来文件::e! |
|
-
文件压缩/解压缩
压缩命令:tar -zcvf 压缩文件名.tar.gz 被压缩文件名
解压缩命令:tar -zxvf 压缩文件名.tar.gz
-
文件内查找
#向下查找字符串
#n : 继续搜寻下一个
#N : 上寻找
/[要查找的字符]
#向上查找字符串
?[要查找的字符]
[注]可以使用man[命令]来查看各个命令的使用文档,如 man cp网络配置目录:cd /etc/sysconfig/network-scripts (CentOS7)ifconfig查看网络配置
软链接与硬链接
-
分类
硬链接
A---B,假设B是A的硬链接,那么他们两个指向了同一个文件,允许一个文件拥有多个路径,用户
可以通过这种机制建立硬链接到一些重要的文件上,防止误删
软链接
类似windows下的快捷方式,删除源文件,快捷方式也访问不了了
-
命令
ln 原文件 链接新文件 创建硬链接
ln -s 原文件 链接新文件 创建一个软链接(符号链接)
touch 新文件 创建文件
echo “字符串” >> 文件 输入字符串
磁盘管理(iostat、sar、df、du)
-
iostat命令
iostat命令可以用来显示系统的磁盘和CPU使用情况。使用以下命令来查看磁盘的读写情况:iostat -d
这将显示每个磁盘的平均读写速度、I/O等待时间以及CPU使用情况
-
sar命令
sar命令是系统活动报告(System Activity Reporter)的缩写,可以用来收集和报告系统的性能数据。使用以下命令来查看磁盘的读写情况:sar -d
这将显示每个磁盘的平均读写速度、I/O等待时间以及I/O请求的队列长度。
-
df命令
该命令查看磁盘各个分区的空间大小、占用、可用等信息。在任意一个目录下输入df:
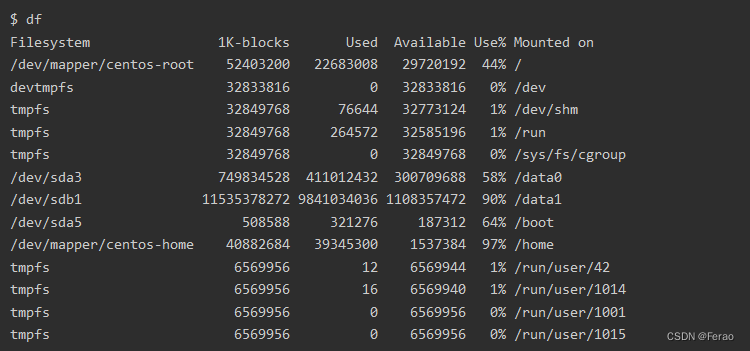
• Filesystem:表示该文件系统位于哪个分区,因此该列显示的是设备名称;
• Used:已用
• Available:可用
• Use%:已用百分比
• Mounted on:所在分区(挂载点)
df命令后可跟相关辅助指令,格式如:df [选项] [文件]
常用的有 df -h可以把内存大小单位换算为G,让信息更可读一些。-h代表human - 人类可读。
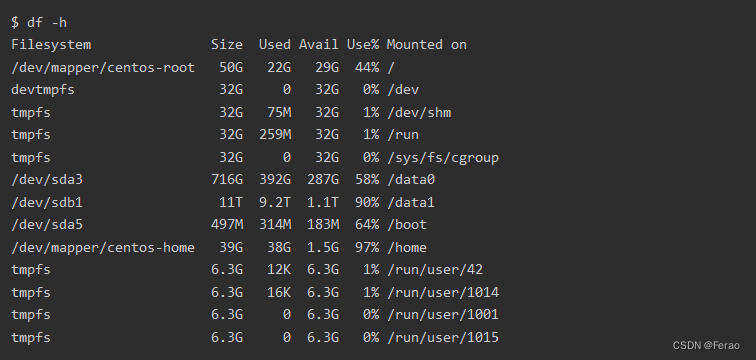
“df -i” 以inode模式来显示磁盘使用情况。
那么df -h 和df -i的区别是什么?同样是显示磁盘使用情况,为什么显示占用百分比相差甚远?
df -h的比较好解释,就是查看磁盘容量的使用情况。
至于df -i,先需要去理解一下inode
最简单的说法,inode包含的信息:文件的字节数,拥有者id,组id,权限,改动时间,链接数,数据block的位置。相反是不表示文件大小。这就是为什么df -h和df -i 显示的结果是不一样的原因。
ps:在df -h 和df -i 显示使用率100%,基本解决方法都是删除文件。
df -h 是去删除比较大无用的文件-----------大文件占用大量的磁盘容量。
df -i 则去删除数量过多的小文件-----------过多的文件占用了大量的inode号。
-
du命令
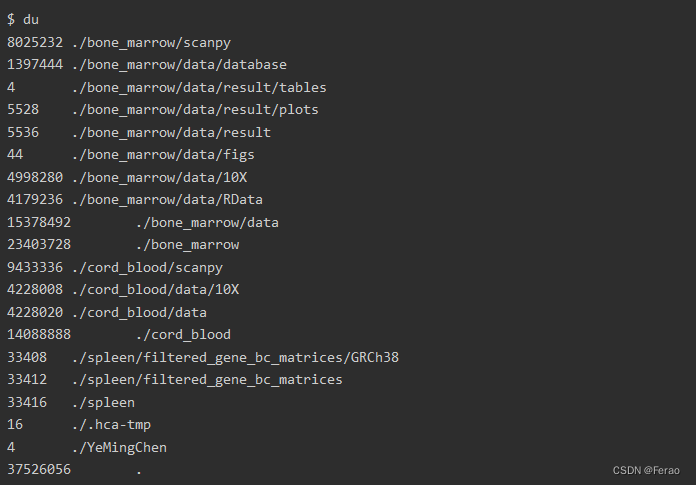
该命令可查看该文件夹的空间占用大小,du是disk usage。要在当前目录下使用,意思就是你要查看什么文件夹就在什么文件夹上输入命令。du会展示各个目录下的占用情况,最后再给出一个总的占用情况。
同理,-h转化为更可读的模式:
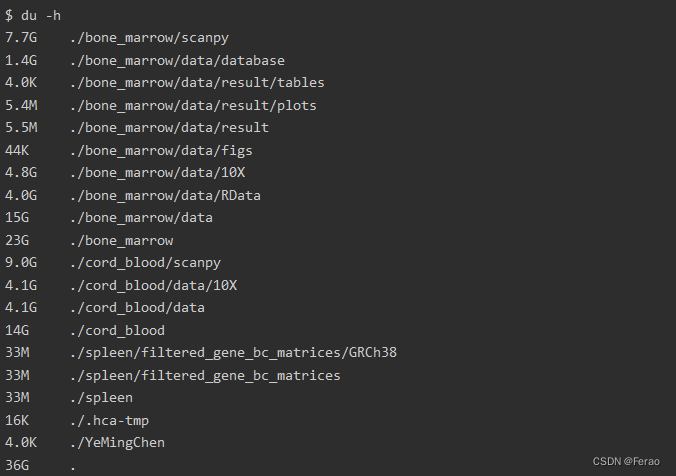
这样一来就清楚地知道这个文件夹总共占了36G,以及各个文件夹的占用。
如果不想查看各个文件夹占用,直接输入du -sh:
内存管理(free)
-
free命令
free命令是对 /proc/meminfo 收集到的信息的一个概述。它可以显示系统中的内存使用情况,包括总内存、已用内存、空闲内存等信息。在任意一个目录下输入free,通常命令后跟辅助指令 -h,表示以人类可读的方式显示内存使用情况,例如使用GB或MB的单位。
-
cat /proc/meminfo 方式
查看RAM使用情况最简单的方法是通过 /proc/meminfo。这个动态更新的虚拟文件实际上是许多其他内存相关工具(如:free / ps / top)等的组合显示。/proc/meminfo列出了所有你想了解的内存的使用情况。进程的内存使用信息也可以通过 /proc//statm 和 /proc//status 来查看。
CPU管理(top)
所有程序都共享CPU的有限资源,而由于某种原因的影响,系统应用程序就会变得缓慢或无响应,在这种情况下,我们就需要查看CPU使用率,并对其进行排查、处理,那么Linux中如何查看CPU使用率?在Linux中,可以通过以下方法查看CPU使用率。
-
top命令
实时显示process的动态,默认每隔5秒刷新,实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
语法:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
| 参数 |
说明 |
示例 |
| -d <秒数> |
指定 top 命令的刷新时间间隔,单位为秒 |
top -d 2 |
| -n <次数> |
指定 top 命令运行的次数后自动退出 |
|
| -p <进程ID> |
仅显示指定进程ID的信息 |
top -p 1234 |
| -u <用户名> |
仅显示指定用户名的进程信息 |
|
| -H |
在进程信息中显示线程详细信息 |
|
| -i |
不显示闲置(idle)或无用的进程 |
|
| -b |
以批处理(batch)模式运行,直接将结果输出到文件 |
|
| -c |
显示完整的命令行而不截断 |
top -c |
| -S |
累计显示进程的 CPU 使用时间 |
|

参数解释:
top - 00:32:08 up 150 days, 21:35, 2 users, load average: 0.91, 1.19, 1.48
| 23:10:41 |
系统当前时间 |
| days |
系统启动后到现在的运行时间 |
| users |
当前登录到系统的用户(终端数) |
| load average |
当前系统负载的平均值,系统在最近1分钟、5分钟、15分钟内,CPU的平均负载情况 |
Tasks: 101 total, 1 running, 97 sleeping, 3 stopped, 0 zombi
| total |
当前系统进程总数量 |
| running |
当前运行中的进程数量 |
| sleeping |
当前处于等待状态中的进程数量 |
| stopped |
停止的系统进程数量 |
| zombie |
僵尸进程数量 |
%Cpu(s): 13.4 us, 1.0 sy, 0.0 ni, 84.6 id, 0.0 wa, 0.7 hi, 0.3 si, 0.0 st
| us |
用户空间占用CPU百分比,表示用户空间程序的cpu使用率,没有通过nice调度 |
| sy |
内核空间占用CPU百分比,系统空间的cpu使用率,主要是内核程序 |
| ni |
用户进程空间内改变过优先级的进程占用CPU百分比,用户空间且通过nice调度过的程序的cpu使用率 |
| id |
空闲cpu,空闲CPU百分比 |
| wa |
等待输入输出的CPU时间百分比 |
| hi |
cpu处理硬中断的数量 |
| si |
cpu处理软中断的数量 |
| st |
被虚拟机偷走的cpu |
MiB Mem : 1826.7 total, 85.9 free, 1477.8 used, 263.1 buff/cache
| total |
物理内存总量 |
| free |
空闲内存总量 |
| used |
使用的物理内存总量 |
| buff/cache |
缓存,用作内核缓存的内存量 |
-
mpstat命令
该命令是一个Linux系统监控命令,可以实时显示CPU使用率和其他CPU统计数据。mpstat命令默认显示所有CPU的使用情况
例如:
02:40:01 AM CPU %user %nice %sys %iowait %irq %soft %steal %guest %idle
02:40:01 AM all 5.42 0.02 2.09 0.04 0.00 0.01 0.00 0.00 92.42
其中,%user表示用户空间程序的CPU使用率,%sys表示系统内核的CPU使用率,%idle表示CPU空闲的时间。
进程管理
在Linux中,每一个正在运行的程序都有一个进程,每一个进程都有一个id号,并且每一个进程都会有一个父进程。进程的存在方式有两种:前台、后台,一般的服务都是后台进行的,基本的程序都是前台运行的。
进程管理的命令是 ps (进程状态的缩写),ps可以显示当前运行进程的详细信息,如用户名、用户 ID、CPU 使用率、内存使用、进程启动日期时间、命令名等等。
在ps命令使用时通常会用到 | (管道符),如 A|B,在A的基础上通过B过滤进程信息。比如:
在所有进程中查找java进程:ps -aux | grep java 或 ps -ef | grep java
下面列出ps进程管理命令常见用法:
#查看当前系统中正在执行的各种进程信息
ps
#显示当前终端运行的所有的进程信息
ps -a
#以用户的信息显示进程
ps -u
#显示后台运行的进程参数
ps -x
#查看所有的进程
ps -aux
#在所有进程中匹配符合条件的字符并列出
ps -aux|grep mysql
#查看父进程
ps -ef
#通过目录树结构查看
ps -ef|grep mysql
#显示进程树-p 显示父ID、-u显示用户组
ps -pu
杀死进程使用kill命令:
#杀死进程,等于windows结束任务
kill -9 [进程ID]
[注]1.grep 查找文件中符合条件的字符串
[拓展]程序后台运行
nohup命令,如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思( n ohang up)。
该命令的一般形式为:nohup Command [ Arg … ] &
nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后使用 nohup 命令运行后台中的程序。要运行后台中的 nohup 命令,添加 & ( 表示”and”的符号)到命令的尾部。
操作系统中有三个常用的流:
▶0:标准输入流 stdin
▶1:标准输出流 stdout
▶2:标准错误流 stderr
一般当我们用 > console.txt,实际是 1>console.txt的省略用法;< console.txt ,实际是 0 < console.txt的省略用法。
使用nohup命令提交作业: 如果使用nohup命令提交作业,那么在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中,除非另外指定了输出文件:
nohup command > myout.file 2>&1 &
在上面的例子中,输出被重定向到myout.file文件中。
2>&1的意思 :是把标准错误(2)重定向到标准输出中(1),而标准输出又导入文件output里面,所以结果是标准错误和标准输出都导入文件output里面了。 至于为什么需要将标准错误重定向到标准输出的原因,那就归结为标准错误没有缓冲区,而stdout有。这就会导致 >output 2>output 文件output被两次打开,而stdout和stderr将会竞争覆盖,这肯定不是我门想要的.
【注】无论是否将 nohup 命令的输出重定向到终端,输出都将附加到当前目录的 nohup.out 文件中。如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。如果没有文件能创建或打开以用于追加,那么 Command 参数指定的命令不可调用。如果标准错误是一个终端,那么把指定的命令写给标准错误的所有输出作为标准输出重定向到相同的文件描述符。
最后谈一下/dev/null文件的作用,这是一个无底洞,任何东西都可以定向到这里,但是却无法打开。 所以一般很大的stdou和stderr当你不关心的时候可以利用stdout和stderr定向到这里>./command.sh >/dev/null 2>&1
[拓展]管道命令
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)
管道命令使用|作为界定符号,管道命令与上面说的连续执行命令不一样。
管道命令必须要能够接受来自前一个命令的数据成为standard input继续处理才行。且管道命令仅能处理standard output,对于standard error output会予以忽略。
管道命令有:less,more,head,tail…等等都是可以接受standard input的命令。
而例如 ls,cp,mv并不会接受standard input的命令,所以他们就不是管道命令了。
[拓展]命令执行顺序控制
通常情况下,开发者在终端只能执行一条命令,然后按下回车执行,那么执行多条命令的方法怎么样的? 示例如下:
#顺序执行多条(简单的顺序指令可以通过 ;来实现)
command1;command2;command3;
#有条件的执行多条命令
which command1 && command2 || command3
有条件的执行多条命令中符号含义:
&& : 如果前一条命令执行成功则执行下一条命令,如果command1执行成功(返回0),则执行command2
|| :与&&命令相反,执行不成功时执行这个命令
$?: 存储上一次命令的返回结果
防火墙管理
-
防火墙-端口
systemctl status firewalld 查看firewall服务状态
systemctl restart firewalld.service 开放端口重启防火墙才能生效
firewall-cmd --list-ports 查看所有开启的端口,如果是阿里云,还需配置安全
组规则
firewall-cmd --list-all 查看防火墙所有信息
firewall-cmd --reload 更新防火墙规则
firewall-cmd --zone=public --add-port=8080/tcp --permanent
永久开放9000端口
firewall-cmd --zone=public --add-port=80-90/tcp --permanent
多端口永久开放
firewall-cmd --zone=public --remove-port=80/tcp --permanent
移除80端口号
【注】
--zone 作用域
--add-port=80/tcp 添加端口,格式为端口和通讯协议
--permanent 永久生效,没有此参数重启后失效
进阶小故事之CPU深夜狂飙
傍晚时分,警报声乍起,整个Linux帝国都陷入了惊恐之中。
安全部长迅速召集大家商讨应对之策。
“诸位,突发情况,CPU占用率突然飙升,并且长时间没有降下来的趋势,CPU工厂的阿Q向我们表达了强烈抗议”
这时,一旁的kill命令说到:“部长莫急,叫top老哥看一下谁在占用CPU,拿到进程号pid,我把他干掉就好了”
此言一出,在座的大伙都点头赞许,惊恐之色稍解。
top命令站了起来,面露得意之色,说到:“大家请看好了”,说完,打印出了当前的进程列表:
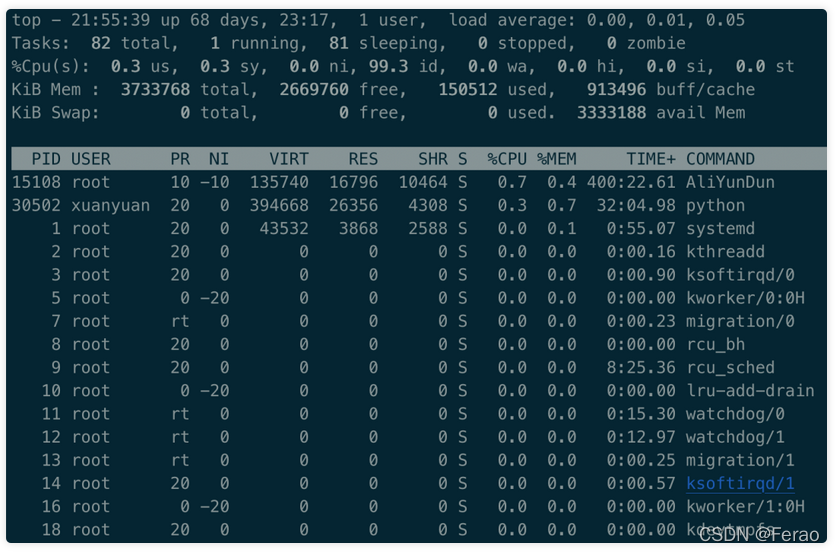
众人瞪大了眼睛,瞅了半天,也没看出哪个进程在疯狂占用CPU,top老哥这下尴尬了。
这时,一旁的ps命令凑了上来,“让我来试试”
ps命令深吸了一口气,也打印出了进程列表。
然而,依旧没有任何可疑的进程。
“你俩怎么回事,为什么没有?”,安全部长有些不悦。
“部长,我俩都是遍历的 /proc/ 目录下的内容,按理说,所有的进程都会在这里啊,我也想不通为什么找不到···”,top老哥委屈的说到。
“遍历,怎么遍历的?”
“就是通过opendir/readdir这些系统调用函数来遍历的,这都是帝国提供的标准接口,应该不会出错,除非···”,说到这,top打住了。
“除非什么?”
“除非这些系统调用把那个进程给过滤掉了,那样的话我就看不到了,难道有人潜入帝国内核,篡改了系统调用?”
安全部长瞪大了眼睛,真要如此,那可是大事啊!
眼看部长急的团团转,一旁的netstat起身说到:“部长,我之前结识一好友,名叫unhide,捉拿隐藏进程是他的拿手好戏,要不请他来试试?”
部长大喜,“还犹豫什么,赶紧去请啊!”
“已经联系了,随后就到”
部长看着netstat,说到:“正好,趁着这个功夫,你先来看看现在有没有对外可疑的连接”
netstat点了点头,随后打印出了所有的网络连接信息:

“来来来,你们挨个来认领,看看都是谁的”,部长说到。
“这个80端口的服务是我的”,nginx站了出来。
“这个6379端口服务是我的”,redis也站了出来。
“这个,9200是我的”,elasticsearch说到。
“3306那个是我的”
“8182是我的”
······
一阵嘈杂后,只剩下一个连接无人认领:

“部长,这八成就是躲在暗处那家伙的连接”,netstat说到。
安全部长思考片刻问到:“curl何在?来访问下这个IP地址,探探对方虚实”
curl站了出来,“来了来了”
curl小心翼翼的发送了一个HTTP请求过去,对方竟然回信了:

一行醒目的mining poll出现在大家面前。
“挖,挖矿病毒!”,top老哥叫了出来。
这一下,在场所有的人都倒吸了一口凉气。
部长赶紧叫防火墙firewall配置了一条规则,将这条连接掐断。
就在这时,unhide走了进来。
简单了解了情况后,unhide拍拍胸脯说到:“这事交给我了,一定把这家伙给揪出来”
随后,unhide一阵操作猛如虎,输出了几行信息:

众人皆凑了过来,瞪大了眼睛,unhide老哥果然不是盖的,果真发现了几个可疑分子。
top有点表示怀疑,问到:“敢问兄台用的什么路数,为何我等都看不到这几个进程的存在?”
unhide笑道:“没什么神秘的,其实我也是遍历 /proc/ 目录,和你们不同的是,我不用readdir,而是从进程id最小到最大,挨个访问 /proc/$pid 目录,一旦发现目录存在而且不在ps老哥的输出结果中,那这就是一个隐藏进程。”
一旁的ps笑道:“原来还有我的功劳呐”
“找到了,就是这家伙!”,netstat大声说到。

“你怎么这么肯定?”部长问到。
“大家请看,进程打开的文件都会在 /proc/pid/fd 目录下,socket也是文件,我刚看了一下,这个进程刚好有一个socket。再结合/proc/tcp信息,可以确定这个socket就是目标端口号7777的那一条!”
“好家伙!好家伙”,众人皆啧啧称赞。
“还等什么,快让我来干掉它吧!”,kill老哥已经按捺不住了。
“让我来把它删掉”,rm小弟也磨刀霍霍了。
部长摇头说到:“且慢,cp何在,把这家伙先备份到隔离目录去,以待秋后算账”
cp拷贝完成,kill和rm两位一起上,把背后这家伙就地正法了。
top赶紧查看了最新的资源使用情况,惊喜的欢呼:“好了好了,CPU占用率总算降下去了,真是大快人心”
天色已然不早,没多久,众人先后离开,帝国恢复了往日的平静。
不过,安全部长的脸上,仍然是一脸愁容。
“部长,病毒已经被清除,为何还是闷闷不乐呢?”,助理问到。
“病毒虽已清除,但却不知这家伙是如何闯入的,还有背后暗中保护隐藏它的人又是谁,这实让我在很忧心啊”
进阶小故事之轻松分析定位JVM问题
你可能一开始会比较畏惧使用复杂的工具去排查问题,又或者是打开了工具感觉无从下手,但是随着实践越来越多,对Java程序和各种框架的运作越来越熟悉,你会发现使用这些工具越来越顺手。
接下来测试使用JDK自带工具来分析和定位Java程序问题。
为了测试这些工具,我们先来写一段代码:启动 10 个死循环的线程,每个线程分配一个 10MB 左右的字符串,然后休眠 10 秒。可以想象到,这个程序会对 GC 造成压力:
public static void main (String[] args) throws Exception
{
IntStream.rangeClosed(1, 10).mapToObj(i -> new Thread(() -> {
while (true) {
//每一个线程都是一个死循环,休眠10秒,打印10M数据
String payload = IntStream.rangeClosed(1, 10000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(payload.length());
}
})).forEach(Thread::start);
TimeUnit.HOURS.sleep(1);
}
将该程序进行打包放置到虚拟机下,然后使用 java -jar 启动进程,设置 JVM 参数,让堆最小最大都是 1GB:

完成这些准备工作后,我们就可以使用 JDK 提供的工具,来观察分析这个测试程序了。
首先使用jps命令得到Java进程列表(这会比使用ps来的方便)

然后根据jps所获取到的Pid(1556),使用jinfo命令打印JVM的各个参数:
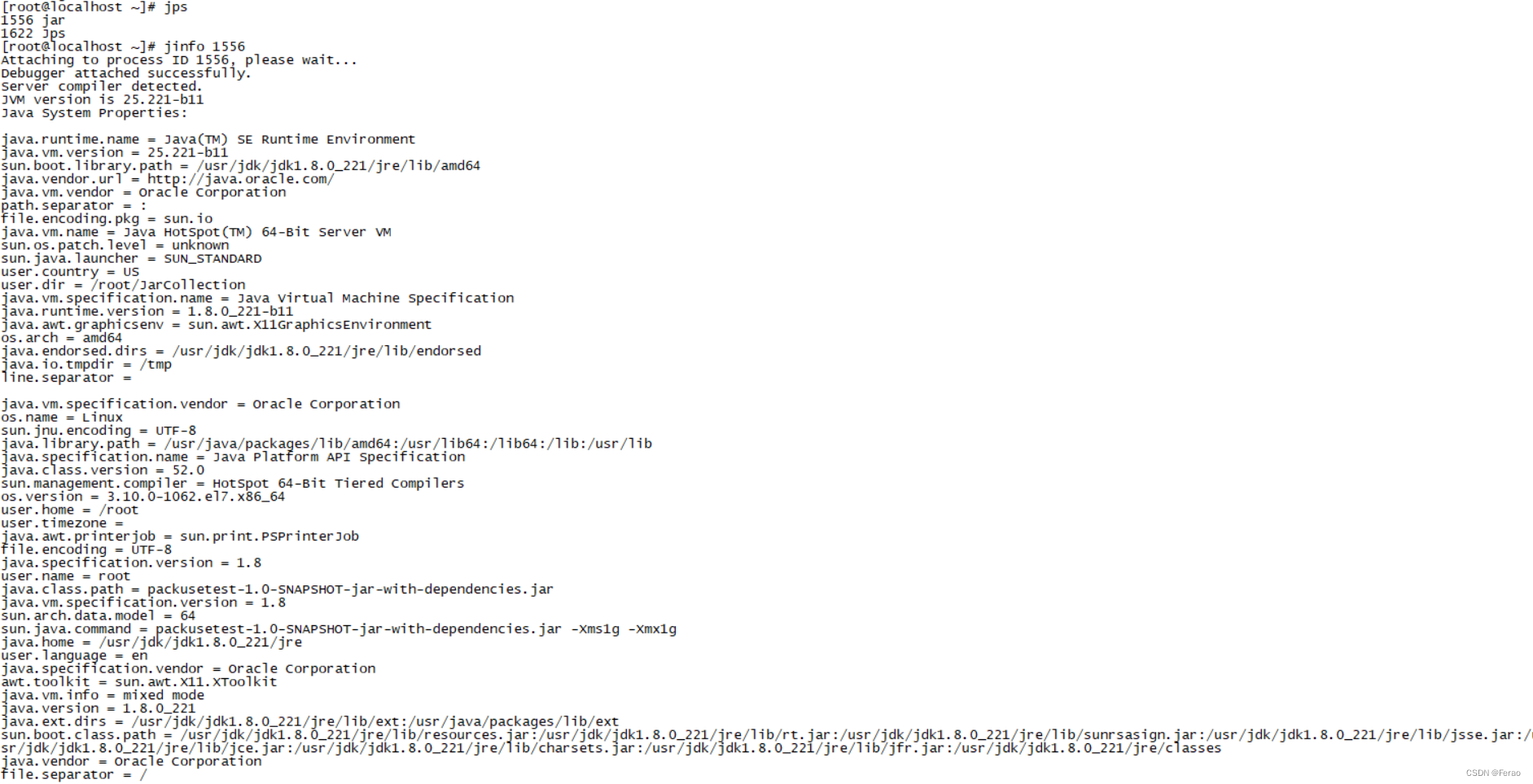
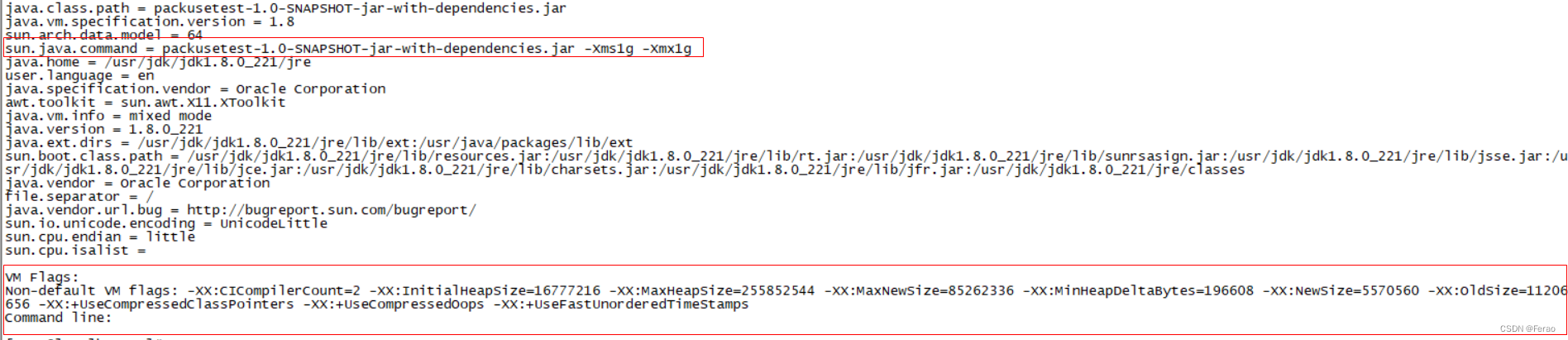
检查后发现如下图所示,我们设置 JVM 参数的方式不对,-Xms1g 和 -Xmx1g 这两个参数被当成了 Java 程序的启动参数,整个 JVM 目前最大内存是 4GB 左右,而不是 1GB。
把 JVM 参数放到 -jar 之前,重新启动程序,可以看到如下输出:
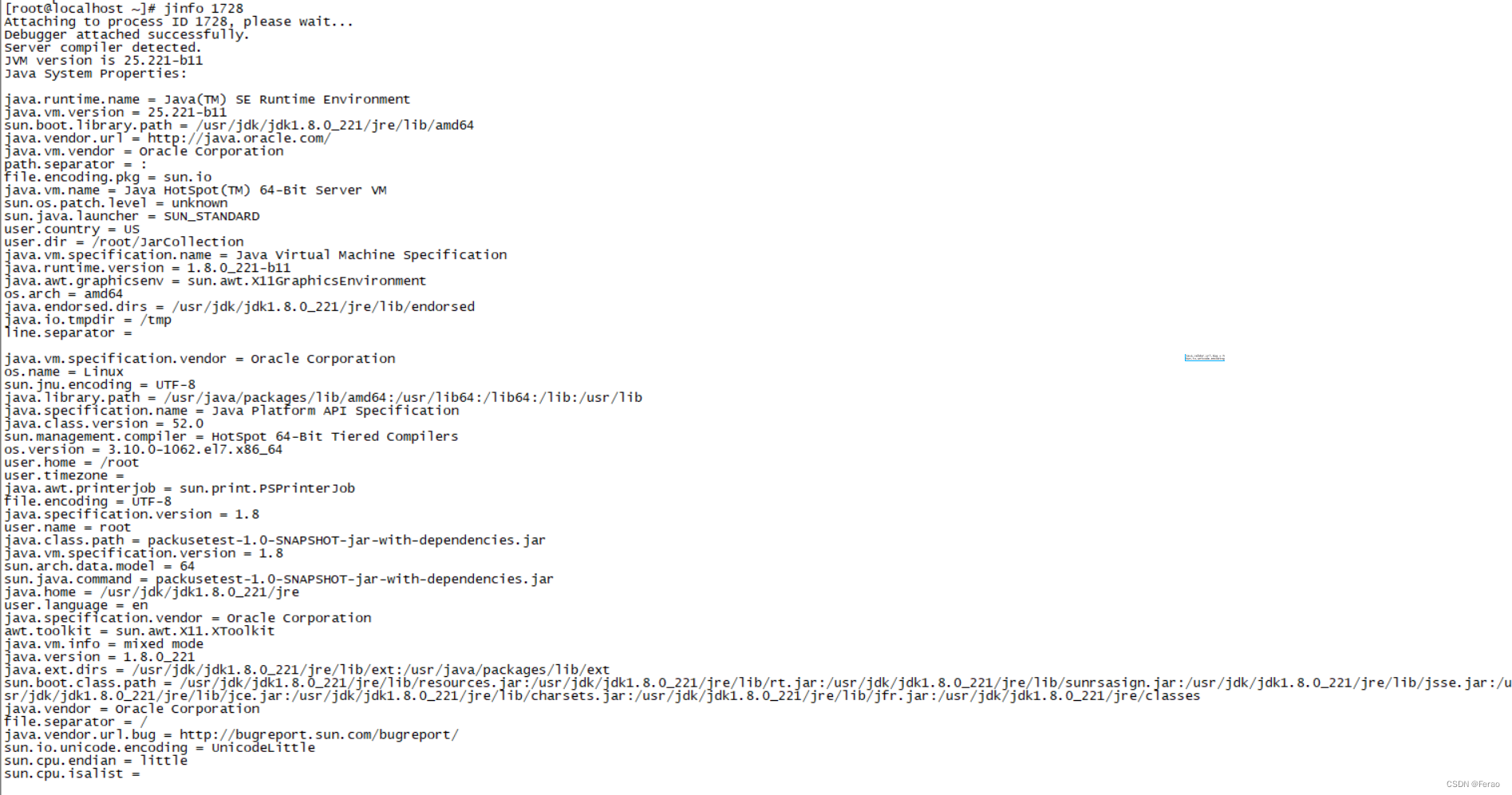
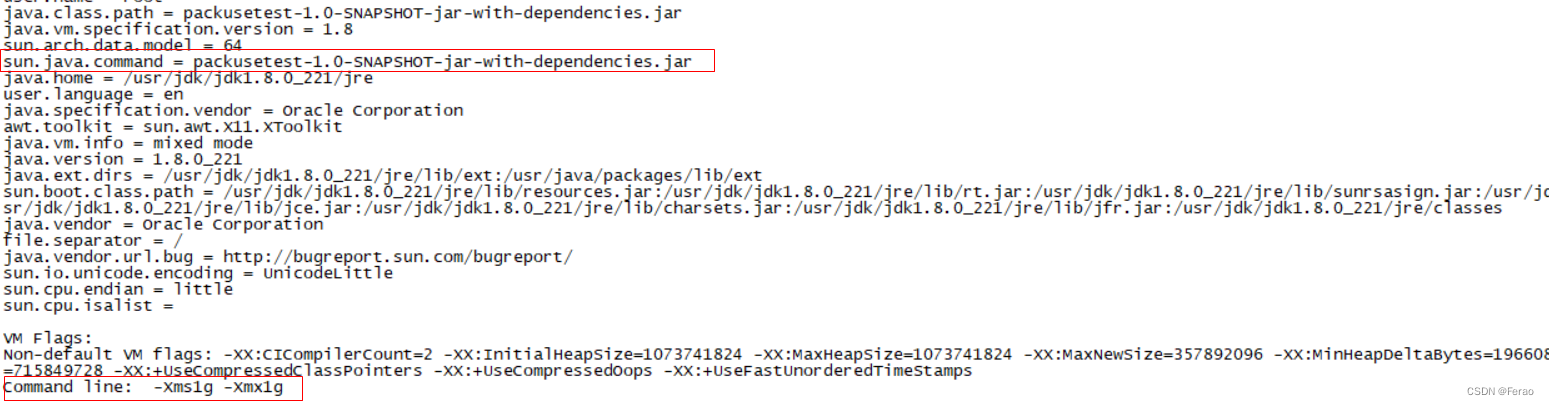
此时可以确认这次 JVM 参数的配置正确了
接着使用jstat命令查看GC趋势,jstat命令允许以固定的监控频次输出JVM的各种监控指标,比如使用-gcutil 输出GC和内存占用汇总信息,每个5秒输出一次,输出100次。
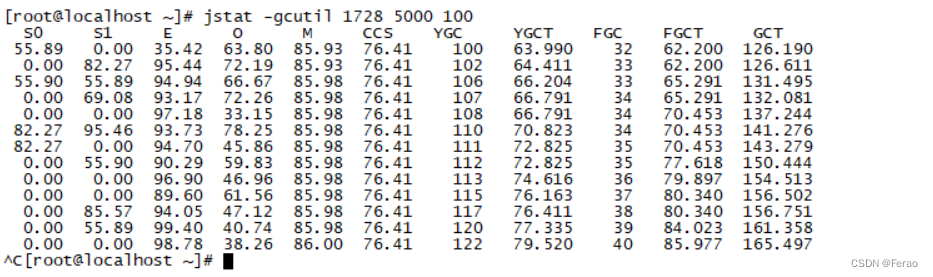
可以看到 Young GC 比较频繁,而 Full GC 基本 10 秒一次;
其中,S0 表示 Survivor0 区占用百分比,S1 表示 Survivor1 区占用百分比,E 表示 Eden 区占用百分比,O 表示老年代占用百分比,M 表示元数据区占用百分比,YGC 表示年轻代回收次数,YGCT 表示年轻代回收耗时,FGC 表示老年代回收次数,FGCT 表示老年代回收耗时。
交互工具
secureCRT
- secureCRT
(1)本地与远程传输文件方式
①通过SFTP标签页
secureCRT按下ALT+P 或[文件]–[连接SFTP标签页] 开启新的会话 进行ftp操作。
查看本地和远程对接目录可以通过:[选项]–[会话选项]–[SFTP标签页]
输入:help命令,显示该FTP提供的所有命令
pwd :查询linux主机所在目录(也就是远程主机目录)
lpwd:查询本地目录(一般指windows上传文件的目录:我们可以通过查看”选项“下拉框中的”会话选项“知道本地上传目录为:D:/我的文档)
ls:查询连接到当前linux主机所在目录有哪些文件
lls: 查询当前本地上传目录有哪些文件
lcd:改变本地上传目录的路径
cd: 改变远程上传目录
get 文件名称:将远程目录中文件下载到本地目录
put 文件名称:将本地目录中文件上传到远程主机(linux)
quit:断开FTP连接
②通过rz命令与sz命令
rz命令(Receive ZMODEM),使用ZMODEM协议,将本地文件批量上传到远程Linux/Unix服务器,注意不能上传文件夹。
当我们使用虚拟终端软件,如Xshell、SecureCRT或PuTTY来连接远程服务器后,使用rz命令可以上传本地文件到远程服务器。输入rz回车后,会出现文件选择对话框,选择需要上传文件,一次可以指定多个文件,上传到服务器的路径为当前执行rz命令的目录。
此外,可以在虚拟终端软件设置上传时默认加载的本地路径和下载的路径。如SecureCRT软件 -> Options -> session options -> X/Y/Zmodem 下可以设置上传和下载的目录。
命令格式:rz [选项]
| 选项 |
说明 |
| -a |
ascii:以文本方式传输 |
| -b |
binary:以二进制方式传输,推荐使用 |
|
|
|
|
|
|
|
|
环境安装
-
软件安装方式
-rpm JDK示例,并在线发布一个项目
-解压缩 tomcat示例,启动并通过外网访问,发布网站
-yum在线安装 docker示例,直接安装运行跑起来docker即可
JDK安装
MYSQL安装
elasticsearch安装
-
JDK安装
(1)下载jdk8的压缩包
(2)上传压缩包到Linux
① 从windows本地上传压缩包到Linux: rz -b
(3)相关linux安装命令
① 检测当前系统是否存在java环境: java -version
② 检测jdk的版本信息:rpm -qa|grep jdk
③ 删除JDK环境:rpm -e --nodeps jdk_*
④ 开始安装java rpm:rpm -ivh jdk包名
⑤ 添加环境变量配置:vim /etc/profile
[拓展] JDK自带工具
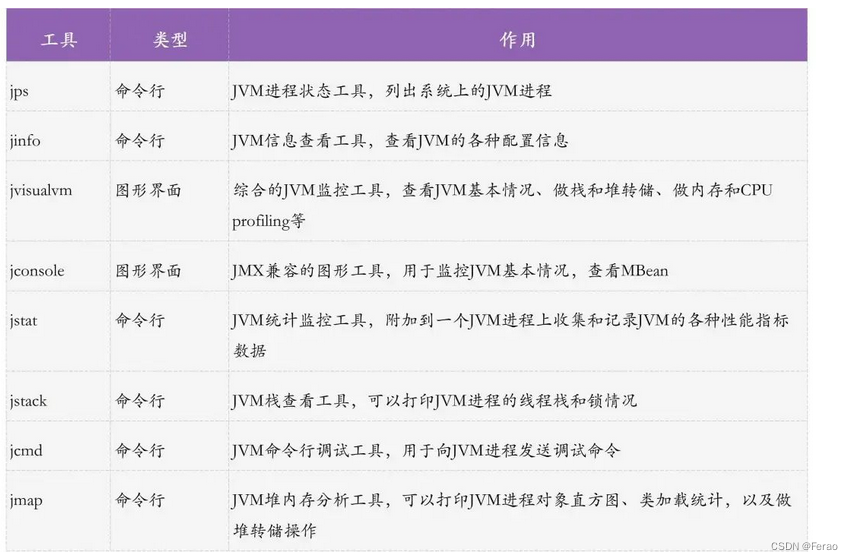
JDK自带了很多命令行甚至是图形界面工具,帮助我们查看JVM的一些信息。

通过下面这张图可了解各个工具的基本作用:
(1)Jps命令
jps是jdk提供的一个查看当前java进程的小工具。其全程为JavaVirtual Machine Process Status Tool。


Jps命令(拓展)
含义
命令格式
jps [options ] [ hostid ]
-[options ]选项
-q:仅输出VM标识符,不包括classname,jar name,arguments in main method
-m:输出main method的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption:传递参数到vm,例如:-J-Xms512m
-[hostid]选项
-jps
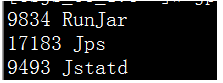
-jps –l:输出主类或者jar的完全路径名

jps –v :输出jvm参数

jps –q :仅仅显示java进程号
MYSQL安装
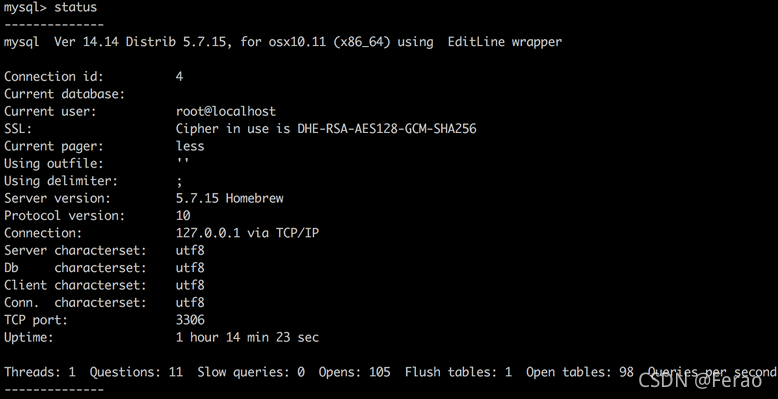
(5)检查MYSQL相关配置状态
在mysql内执行状态命令:status
- tomcat安装
步骤一 : 官网下载tomcat9即可 ,apache-tomcat-9.0.22.tar.gz
步骤二 : linux命令
tar -zxvf apche-tomcat... 解压压缩包
./startup.sh 执行tomcat
./shutdown.sh 停止tomcat
[注]
1.上传完毕的项目直接购买自己的域名,备案解析过去即可。
2.域名解析后如果端口是80,http或者443-https 可以直接访问,如果是9000 8080,就需要通过apache或者niginx做一下反向代理即可,配置文件即可
- docker安装
cat /etc/redhat-release 检测CentOS 版本
yum -y install gcc 编译C工具
yum -y install gcc-c++ 编译C++工具
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine 官网版卸载旧版本
yum install -y yum-utils device-mapper-persistent-data lvm2
安装必须的软件包
yum-config-manager --add-repo http://mirrors.
aliyun.com/docker-ce/linux/centos/docker-ce.repo
设置stable镜像仓库(这里使用的是国内的)
yum makecache fast 更新Yum软件包索引
yum -y install docker-ce docker-ce-cli containerd.io
安装Docker CE
systemctl start docker 启动docker
docker version 查看docker版本
docker pull hello-world 从docker镜像仓库中拉去hello-world镜像
docker images 查看下载好了的情况
docker run hello-world 运行helloworld
ps -ef|grep docker 查看docker进程
[注]
1.gcc是拿来编译各种源代码的软件 所谓GCC包,就相当于安装GCC的安装包啦,类似WIN下的setup.exe
2.RPM是不需要GCC就可以装的,不过TAR包里都是源代码,你得自己编译才能装,所以一定要装GCC,不然无法装
3./usr/bin查看是否有gcc包
4.安装yum-utils,它提供一个yum-config-manager单元,同时安装的device-mapper-persistent-data和lvm2用于储存设备映射(devicemapper)必须的两个软件包。
-
elasticsearch安装
下载安装包:https://www.elastic.co/cn/downloads/elasticsearch
将下载的安装包上传至linux里,然后进行接下来的配置环节:
①创建elasticsearch数据文件和日志文件
–>在linux根路径下创建一个path文件夹:mkdir /path
–>将该文件夹更改为elsearch用户下且elsearch组:chown -R elsearch:elsearch /path/
–>进入elsearch用户中:su -elsearch
–>创建多级目录也就是创建to目录和data目录:mkdir -p to/data
–>创建多级目录也就是logs目录:mkdir -p to/logs
②更改elasticsearch配置文件
–>进入elasticsearch的配置文件:vim elasticsearch.yml

 此处进行设置跨域访问支持,默认为false,跨域访问允许的域名地址,(允许所有域名)以上使用正则http.cors.allow-origin: /.*/
此处进行设置跨域访问支持,默认为false,跨域访问允许的域名地址,(允许所有域名)以上使用正则http.cors.allow-origin: /.*/
③
④运行elasticsearch
–>进入es文件夹下的bin目录
–>开始执行elastcsearch服务:./elasticsearch
–>若上面没有报错,可后台执行elasticsearch:./elasticsearch -d
–>测试elasticsearch:curl 'http://自己配置的IP地址:9200/'
⑤windows安装elasticsearch head
参考:https://blog.csdn.net/Zereao/article/details/89362105
参考:https://blog.csdn.net/Sunshine_liang1/article/details/96328301
cmd进入elasticsearch-head 执行cnpm run start
⑥
⑦⑧⑨
-
linux操作
Liniux下配置elasticsearch文件夹
getconf LONG_BIT 查看Linux是32位还是64位
groupadd elsearch 创建一个elsearch用户组
useradd elsearch -g elsearch 创建一个elsearch用户并放入elsearch用户组
chown -R elsearch:elsearch [解压后文件名] 将该elasticsearch文件更改为elsearch用户下
Liniux下更改用户空间
su -root 切换到root用户下
sysctl -w vm.max_map_count=262144 将内存设置为262144
sysctl -a|grep vm.max_map_count 查看内存设置结果
vim /etc/sysctl.conf 进入系统设置文件内
加一行:vm.max_map_count=262144
程序员常用开发命令组合
(1)本地与远程传输文件方式