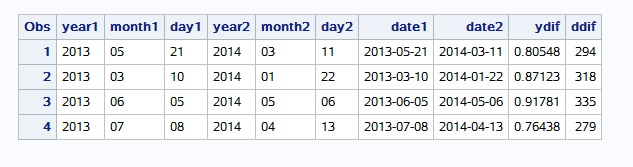@[TOC] (目录)
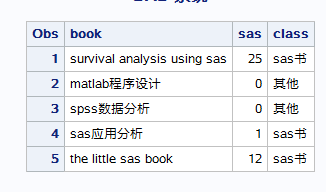
数据集的命名
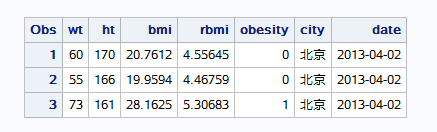
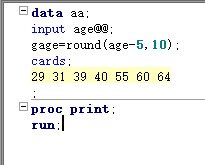
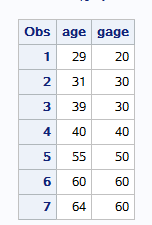
sas先根据设定的总位数来读取数据,然后继续考小数位数的设定 sas读整数,没有小数点就自动把自己降为小数 == proc print输出数据集==把读取的数据显示到输出窗口
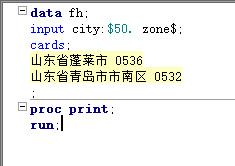
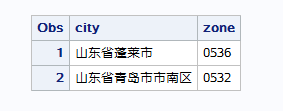
sas默认对字符只读取8位,如果变量宽度超过8字节,最好加上宽度值,以保证sas能全部读取
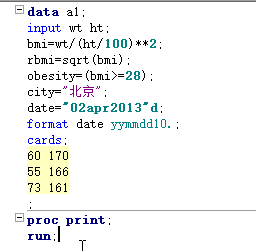
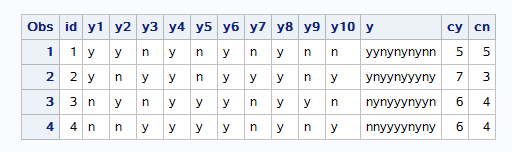
常用的分隔符 - / .等sas都可以识别,但是分隔符也占宽度 如果年月日之间没有任何分隔符,此时sas要求输入的月和日都是2位(130508)(2013-5-8) == 日期型变量的宽度最大不能超过32==
sas默认以空格作为变量分隔,但是一旦对变量指定了宽度,sas就不在以默认的空格作为变量区分标志,而是按指定的宽度识别 == 在变量和输入格式之间加冒号:==告诉sas如果要读取下一个变量,需要满足小面任一条件:要么遇到空格,要么变量的宽度读完了 当同一变量的不同数据有不同宽度时,可以指定数据中最大或更大的一个宽度值,然后结合冒号读取
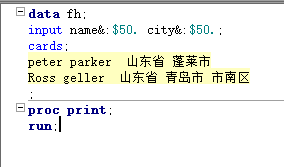
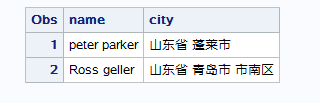
== 变量包含空格==在变量后多加一个&符号 因为每个变量本身有空格,所以变量之间就需要2个或2个以上的空格隔开,这样sas就会把2个及以上的空格作为变量分隔符
== 指定输入格式会改变变量的值,而指定输出格式不会改变变量的值,只是改变显示的样子== input format 变量1 格式1 变量2 格式2
w.d commaw.d:将数值的整数部分自右向左每三位用逗号隔开== w包含逗号和小数点在内== percentw.d:将数据显示为百分位形式,自动将变量值乘以100,并加上%== 指定w时要预留3个字节的位置显示%==
对于字符型变量来说,只要把正确读取进来,sas就会原模原样的把它输出出去
== proc format==
== low-high的范围就是从最低值到最高值==
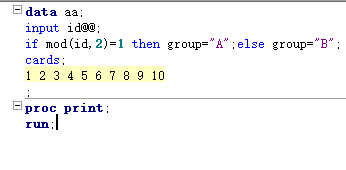
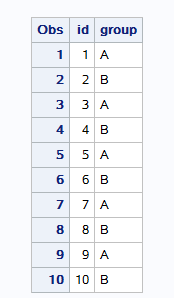
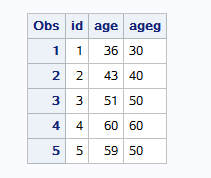
== 变量名=表达式或函数== 新变量一定要写在input和cards之间
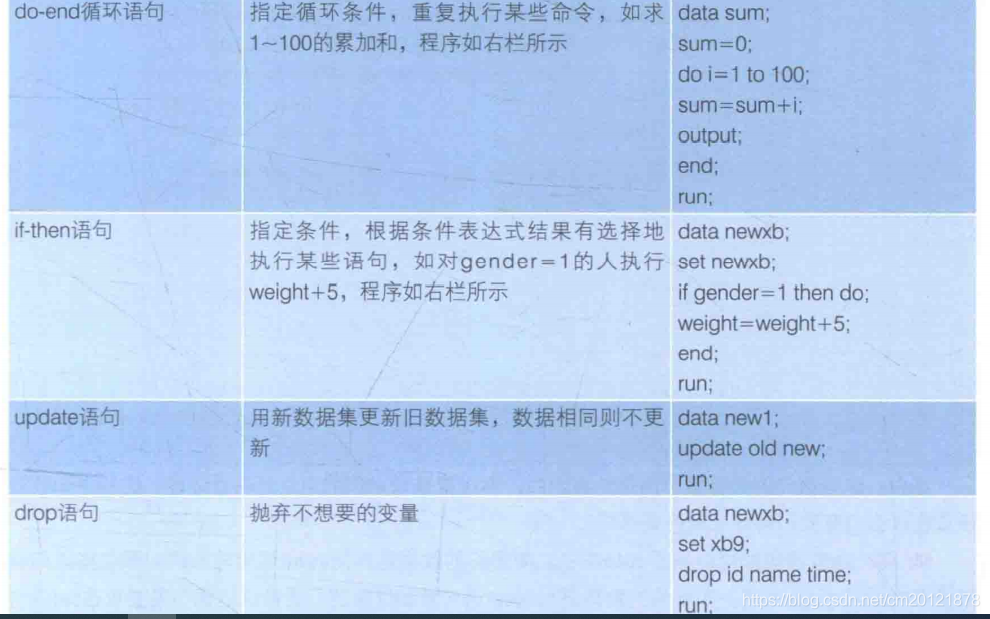
== if 表达式 then 新变量= ; else 新变量= ; ==
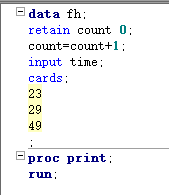
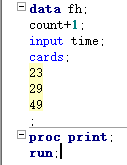
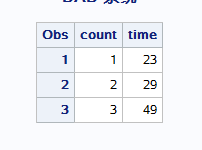
== retain 变量 <初始值>;== == 变量+表达式;==
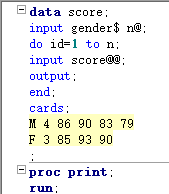
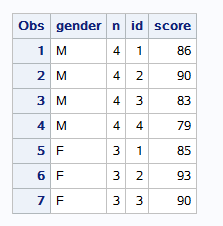
==do 变量=初始值 to 最终值 <by 增加量>; sas语句; output; end; ==
== length 变量1 <$> 长度1== length与一定要在新变量产生之前就设定好,否则是不起作用的。 字符变量的长度由第一个遇到的值的长度决定,而且字符变量一旦产生,它的长度就无法改变
== @@是强制sas往右读取数据== @也是强制sas往右读取数据,不过它只在一定条件下才起作用,只有data不=步中有两个input语句的时候,才对第二个input语句才起作用,如果只有一个input语句,@就不起作用
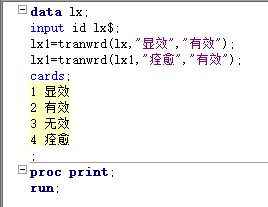
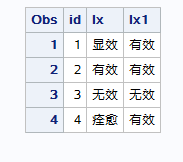
1.计算变量的长度 length lengthn == 如果要对一个变量的所有值进行同样的操作,而这个变量中的值长度不同,那就需要先判断变量长度,然后对不同长度设置不同的添加== 2.提取变量中的字符 substrn:指定一个变量,对该变量从起始位置开始,提取指定长度的字符 3.查找变量中的字符 find findc:根据指定的起始位置,查找相应的内容,如果找到就返回找到的位置,找不到就返回0 anyalpha:查找变量中任意的字母,并返回第一个字母的位置 anydigit:查找变量中任意的数字,并返回第一个数字的位置 anyalnum:查找变量中任意的字母或数字,并返回第一个字母或数字的位置 4.替换变量中的字符 tranwrd(变量,查找值,替换值):从变量中找到“查找值”,并用“替换值”替换掉。 tranwrd一次只能替换一个字符串
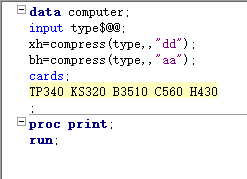
5.去除变量中的字符 compress(变量<,欲去除的字符><,“修饰符”>):从变量中去掉“欲去除的字符” == 修饰符== a去掉变量中所有的字母 b去掉所有的数字 s去掉所有的空格 i忽略大小写 k保留“欲去除的字符”,去掉其他的字符
6.变量的合并 cats:将几个变量合并为一个变量,删除前后空格 catx(“分隔符”,变量1,变量2…):将几个变量合并为一个变量,中间用分隔符隔开 ==||==常规的连接符连接变量
7.清点变量中某字符的个数 count(变量,欲清点的字符<,“i”>):从变量中找到欲清点的字符,返回字符个数,如果没有找到返回0
8.查找变量中的缺失值 missing(变量):判断变量是否为缺失值,是则返回1,不是则返回0 missing对数值型变量和字符型变量都是通用的 missing函数一次只能查找一个变量的缺失值,但不意味着多个变量的查找需要写多个函数
1.日期的合并与差值 mdy:将年、月、日合并为一个日期格式的变量或值有人 yrdif(开始日期,结束日期,“计算依据”):计算两个日期之间以年为单位的差值 datdif(开始日期,结束日期,“计算依据”):计算两个日期之间以天为单位的依据 计算依据指定计算差值的依据,通常指定’actual",也就是按照当年的实际天数计算
2.日期的提取
用input函数和put函数转换已有变量的格式,一定要赋值给另一个变量,而不能是原有变量 input(变量,输入格式):字符型转为数值型,或将字符型转换为其他格式的字符型 put(变量,输出格式):把数值型转为字符型, 靠左显示说明变量是字符型,靠右显示说明是数值型 put函数输出的值一定是字符型,不管它看起来是数字还是其他样子
cdf(‘分布’,分位数,参数):返回指定分布的累积概率分布与分位数对应的概率
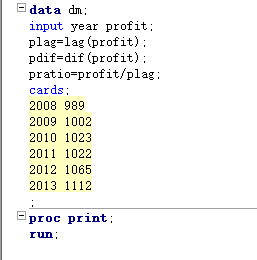
lag函数的作用是返回指定变量的前一个(或前几个)记录 dif函数返回当前记录与前一个(或前一个)记录的差值
set语句的作用是将若干个数据集依次纵向连接,并存放到data语句建立的数据集中。 如果set后面只有一个数据集,此时相当于复制 data 数据集; set 数据集1(数据集选项) 数据集2(数据集选项)…; run; 数据集选项 数据集1(in=临时变量1):针对数据集1产生一个临时变量1,当合并的记录属于数据集1时,该临时变量值为1,否则为0.所以可以利用in=选项判断合并记录哪些属于数据集1 ,哪些属于数据集2. 临时变量可以调用,但不会再结果中显示,所以可以把他们赋值给另外的新变量就可以显示出来了。 数据集1(rename=(原名1=新名1)):把数据集1中的变量改一下名字。当准备合并的2个数据集变量名不同时需要用这个选项把名字改为相同。
sas的数据集一旦建立成功,就没法用命令修改了 如果想对已有数据集进行修改,只能用data语句新建一个数据集,然后用set语句把已有的数据集复制过来,然后在新建相应操作。 data语句的作用是创建新的空白数据集,而不是打开数据集
data 数据集; merge 数据集1 数据集2; by 变量1 变量2; run; 在利用by语句横向合并时,如果两个数据集事先没有按id排序,一定要先对他们分别进行排序才能合并
数据集的并集 数据集的交集
proc compare <base=数据集 compare=数据集> ; by变量1 变量2; id变量1 变量2; run;
nosummary:不显示一些概括性的结果 transpose:按记录显示不一致的结果,如果不指定该选项,默认的是按变量显示不一致的结果 by:指定索引变量,如果两个数据集的记录不同,通过by语句可以避免错位比较的情况 id:指定索引变量,让你很方便地根据该变量找到相应的观测,如果不指定,默认结果只显示第几行
proc sort <data=数据集> <out=数据集> ; by 变量1 变量2; run;
proc sort语句调用排序过程 data=数据集指定对哪个数据集进行排序 out=数据集把排序后的数据集输出到指定数据集中,此时原数据仍然保留 nouniquekey输出重复值 nodupkey删除重复值,也就是输出唯一值
重复值的定义需要在by中指定,如果要查找重名的人,那就在by语句中指定代表姓名的一个变量就行,如果姓名和性别都相同才算重复值,那就在by语句中指定代表姓名和性别两个变量。
sort过程自动产生两个变量:first.变量和last.变量,分别表示某变量某个值的第一个和最后一个观测
只要想对多个变量执行完全相同的操作,就可以考虑用数组批量执行这些操作 array 数组名[下标] <$> <数组元素><(元素初始值)>;
array是定义数组的标志 数组名就是给数组起个名字 下标指定数组中包含的变量个数 数组元素主要是列出数组中包含的一个或多个变量,这些变量可以是数据集中已有的变量,也可以是新变量。如果新建的变量是字符型,需要在前面加上$符号 元素初始值是指定新变量的值,如果不指定元素初始值,默认新变量的值为缺失值。
数组定义注意事项 数组名不能与数据集中已有变量名重名,也不要与已有函数同名。 一个数组中的变量类型必须相同,不能既有数值型,又有字符型。 数组下标既可以用[],也可以用{}或()。 数组中下标可以是个范围,如[11:15]。 数组中的下标可以不写,而用代替,如[]。 数组中的数组元素可以不写。 元素初始值一定要用()括起来,各个值之间可以用逗号或空格隔开。
自动变量:sas在运行某些过程中自动产生的变量,这些变量不会直接在结果中显示,但确实存在,可以调用。 _n_表示观测或记录的序号 _numeric_表示数据集中的所有数值型变量 _character_表示数据集中所有字符型的变量 _all_表示数据集中所有的变量
dim()函数是专门针对数组的函数,他的作用是返回指定数组所含元素的个数
data 新数据集; set 已有数据集; if | where 条件语句; proc print; run;
作用一样,都可以根据指定的条件选择观测,但在某些具体用法上有细微差别。 1.都可以使用的场合 利用set语句有条件地复制数据集时,set后紧跟着条件语句,此时两者都可以。(where运行速度快,因为在读入数据之前就执行选择条件) 2.只能用if 的几种场合(并非全部场合) a。使用sas的自动变量 b。如果指定的条件变量是新产生的变量 3.只能用where的几种场合(并非全部场合) a。使用某些特殊运算符 between…and…指定介于数值变量两个观测值之间的观测 contains“指定字符”:指定字符型变量中包含字符的观测 like“指定字符”:指定字符变量中与指定字符相似的观测,模糊部分可以用%(代表多个字符)或_(代表一个字符)代替 is null或is missing:指定包含缺失值的观测 b。调用某一个proc过程时,如果要选择部分观测执行该过程 c。当作数据集选项使用时
多重填补法:首先利用数据集中的其他变量来预测具有缺失的变量值,然后用模拟的方法产生一个预测值的分布,从预测值的分布中随机抽取数据作为缺失值的填补。由于缺失变量可能是另一个缺失变量的预测变量之一,所以该过程需要重复多次,循环产生预测值并使用每次更新后的值,最终该过程产生一个没有任何缺失值的数据集。 proc mi <out=数据集> <round=> ; mcmc; var 变量1 变量2 …; run;
proc mi语句调用缺失值填补过程 out=是把填补后的数据保存到自定义的数据集中 round=指定填补值的小数位数 minimum> <maximum指定填补值的最大值和最小值 mcmc语句采用蒙特卡洛模拟方法来产生一个抽样分布,作为缺失值的填补技术 var语句指定哪些变量需要填补
由于多重填补利用的是模拟分布和随机抽样技术,每次产生的填补值都是不一样的 sas默认产生5个填补完整的数据集 proc mianalyse可以直接对mi过程产生的5次填补结果进行综合分析
data 新数据集; update 旧数据集 新数据集; by 索引变量; run;
用update的时候,新建的数据集无需包含所有数据和变量,只要有打算修改的就行,其他作为缺失值即可
这些语句都可以用于data步中,如果数据是利用input语句输入的,那这些语句通常放在input和cards之间;如果是利用set语句复制进来的,则放在set语句后面。
1选择具有相同特征的人群子集 data 新数据集; set 已有数据集; if | where 条件语句; run;
2选择连续记录的数据子集 proc print data=数据集(firsttobs= obs=); run;
firsttobs=指定第一个记录号 obs=指定最后一个记录号
data 新数据集; set 已有数据集; keep | drop 变量1 变量2; run;
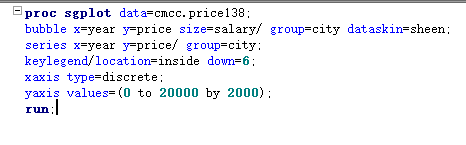
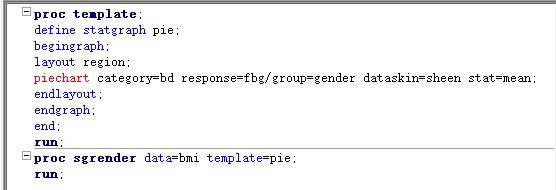
proc sgplot过程,主要用于绘制线图、点图、柱状图、箱式图、散点图、密度分布图、气泡图、瀑布图、带状图、阶梯图等。 proc template和proc sgrender过程,可自行定义绘图模板,设计自己想要的任意图形。 proc gradar 过程,可用于绘制雷达图、日历图、风玫瑰图等。 proc gmap和proc mapimport过程,可用于绘制各种地图。
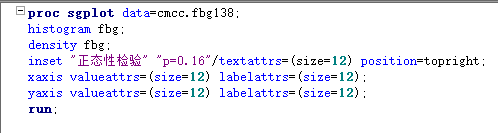
“ODS图形设计器”—直方图----选择数据集和变量 可以在当前图上叠加其他图“添加元素” 分年龄、性别看各组的分布—面板变量
箱子中间的圆圈或加号为均值 横线为中位数 箱子两端分别是上下四分位数 箱子外面横线是最大值最小值或上下四分位数+1.5*四分位数间距 超出横线为异常点
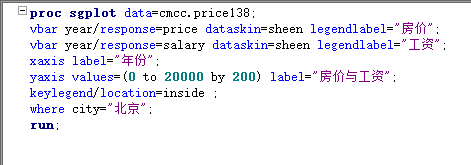
如果指只想分析某一部分人群,可以使用where语句
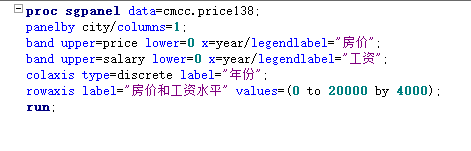
当我们想要在一幅图中同时显示两个指标,而这两个指标的数值又相差很大,就可以考虑增加第二个坐标轴,设置另一套刻度,这样就不会出现两条线相差悬殊的情况了。
根据一定的标准值将图划分为多个不同颜色的区域,每个区域代表不同等级的风险。根据个体落在不同的区域,可以判断个体的风险程度。
饼图不仅可以显示分类变量各类的百分比,也可以用来展示连续变量,显示各块饼中某变量的均值
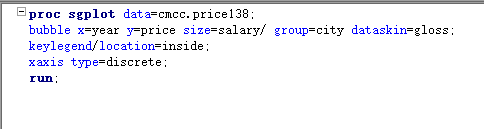
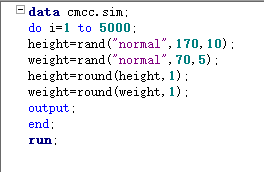
可以同时反映两个变量的分布 对于三维直方图,数据太少会不好看,因为它需要利用两个变量不同组合的频数来绘制。 rand函数产生随机数
日历图是将一个圆圈划分为面积相等的12份,分别表示1-12月,每部分用不同的颜色表示各月份中某指标值的情况
1.proc mapimport过程 proc mapimport datafile=文件路径和名称 out=数据集名 ; id 变量 ; select 变量1; exclude 变量1; rename 变量1=新变量1;
proc mapimport调用地图文件导入过程 datafile=指定要导入的地图文件路径和名称 out=指定将导入的地图文件输出的数据集名 选项contens会在log窗口显示导入数据集的基本信息,如变量名称及其类型等。 id指定作为索引的id变量 select指定保留的变量名 exclude指定去除的变量名 rename用于修改原有数据集中的变量名
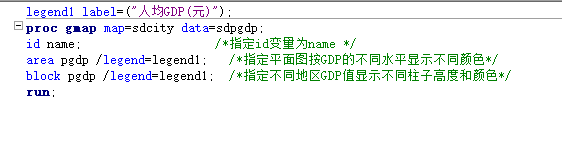
2.proc gmap 过程 proc gmap data=数据集名 map=地图文件名; id 变量; choro 反应变量<选项>; block 反应变量<选项>; prism 反应变量<选项>; area 反应变量<选项>;
proc gmap调用绘制地图过程,该语句必须指定data=和map= map=指定地图数据集,包含绘制地图所需的各种变量 data=指定分析数据集,包含打算在地图上显示的反应变量 id指定作为索引的变量 choro绘制二维地图不同区域用不同颜色显示 block绘制三维地图,不同区域用不同颜色和高度的柱子显示 prism绘制三维地图,不同区域用不同颜色和高度的凸出显示 area需与block或prism语句一起使用,在不同区域显示不同颜色的柱子或凸出的同时,在地图的平面图也显示不同的颜色
sas自带的地图文件虽然方便,但它的数据太局限,只有省的数据,而没有具体到市县的数据
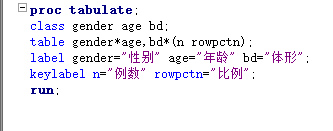
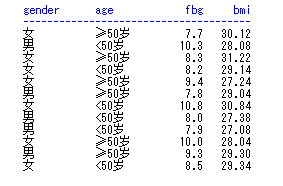
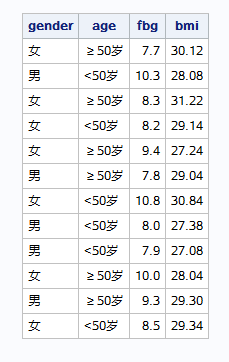
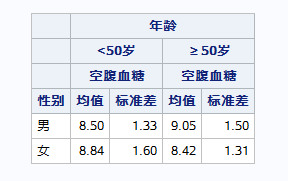
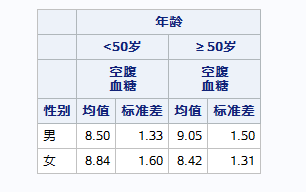
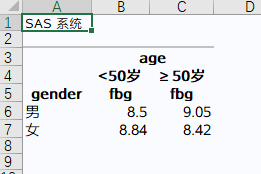
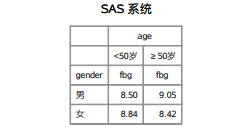
proc tabulate/选项; class 分组变量1; var 分析变量1; table 变量布局; keylabel 关键词1=“标签1” ; run;
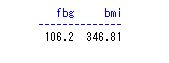
如果关键词什么都不指定,默认对分类变量输出例数,对连续变量输出总和。
1.为变量添加标签
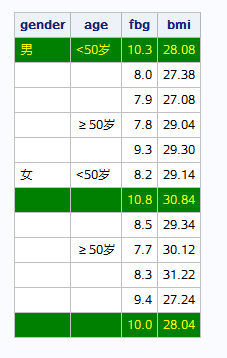
2.消除表格中单元格的自动合并 3.不显示变量名 去掉变量名与指定变量名的格式是一样的 ="" 里面什么不填相当于去掉标签 4.修改缺失值的显示方式 5.增加合计项 6.修改表中数据的显示形式 一般的布局规律从大道小,先安排总体的大布局,在安排局部的小布局,最后再对变量或关键词进行名称或格式的修饰
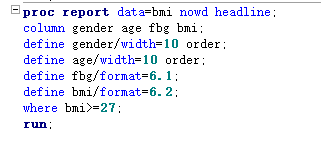
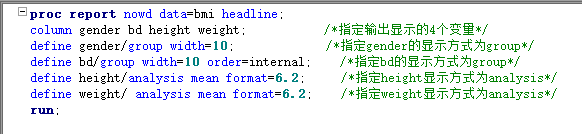
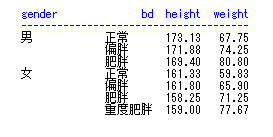
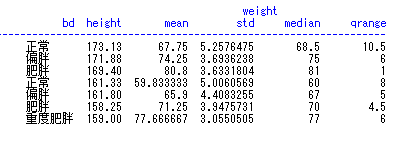
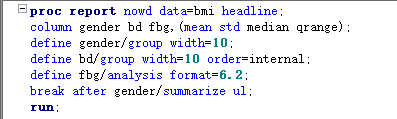
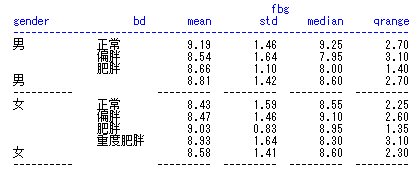
proc report; column 变量1; define 变量/选项; break after/before 变量/选项; rbreak after/before /选项; compute after/before 变量; line “描述”; endcomp; compute 变量; call define(列标识,格式,格式设定值); endcomp; by变量; run;
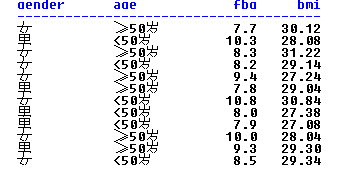
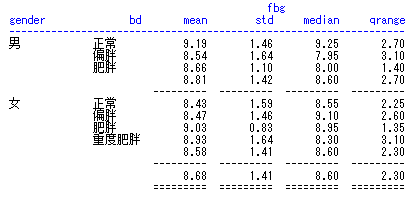
由于指定的变量既有字符变量,也有数值变量,因此最终显示的是所有符合条件(bmi>=27)的每一条观测 字符变量的默认显示方式是diaplay,即显示每一条观测,而数值变量默认的显示方式是analysis,即显示变量的统计量,默认的统计量是sum 如果想显示数值变量的每一条观测加上display选项就行。
如果想要同时显示多个统计量,需要在column语句中指定,而不是在define语句中,define语句一次只能指定一个统计量。
report过程还可以加上自己的总结性文字描述,并在文字中穿插自动变化的统计量
修改变量的输出名字,只要在define语句中直接加引号就行 如果想要让输出的名字分行显示,只要加上/就可以
把sas的结果直接传送到word或Excel,PDF 把输出结果的全部或者一部分保存到另一个数据集中,以备后用 选择性的输出结果,根据自己的需要只输出想要的部分结果
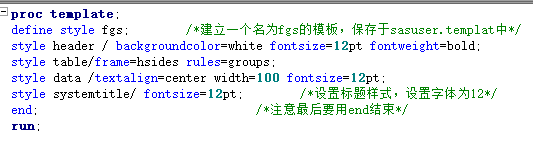
proc template; define style 模板名; style 样式元素/样式属性; end ; run ;