序言
数统治着宇宙。――Pythagoras
数学一词在西方源于古希腊语μάθημα,意思是通过学习获得知识,显然,早期数学涵盖的范围比我们今天要广得多。人类科学发展至今,衍生出生物科学、信息科学、金融学、计算机科学等不胜枚举的领域与分支。而数学模型正是数学应用到各个领域的桥梁,数学模型的作用几乎渗透到现代科学的每一个角落,本文并非枯燥乏味的学术论文(并非贬低枯燥却严谨的学术论文,只是不同的表现形式),而通过科学史上真实的例子,让读者感受数学模型在科学发展中的强大力量。这些例子,包括时间跨度很大的天文学研究,也包括时下热点领域人工智能,试图让读者从中窥见数学模型设计的一些基本原则与数学思想,而这些原则与数学思想,往往非常简单又极具普适价值,希望能让各个领域的读者获得一点点思路上的启迪。
特别鸣谢
本文的一些例子(托勒密的例子,Adwait Ratnaparkhi的例子,华尔街的例子)参考了著名学者、投资人、人工智能与语音识别专家吴军博士所著的《数学之美》(第三版,人民邮电出版社)一书,很多思想也备受该书的启迪,谨向吴军博士以及为该书的出版工作做出贡献的人们表示诚挚的敬意。
数学模型的重要性——从“地心说”谈起
在天文学中,地心学说1的起源很早,最初由米利都学派形成初步理念,后由古希腊学者欧多克斯提出,经亚里士多德完善,又由托勒密进一步完善成为“地心说”。本文关心的并非地心说的起源,而把时间刻度的侧重放在托勒密的完善以及之后的发展过程,因为正是从托勒密开始,人们才开始尝试使用数学模型,对地心说进行定量计算与完善。
克罗狄斯·托勒密(Claudius Ptolemaeus)“地心说”的集大成者,公元90年生于埃及,父母都是希腊人。他是著名的天文学家和数学家,几何学上著名的“托勒密定理”也是以他的名字命名。之于地心说,托勒密的伟大之处是用40-60个在大圆上套小圆的方法,精确地计算出行星的运算轨迹。他继承了毕达哥拉斯的一些思想,认为圆是最完美的几何图形(帮助,还是桎梏?),因此用圆来描述行星运动的轨迹,如下图。
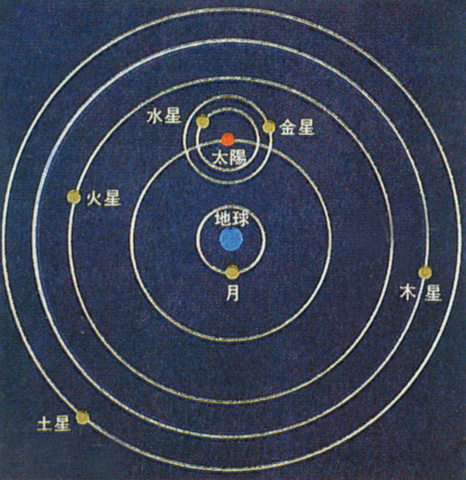
托勒密模型的精度之高,让后来的科学家们(当然是指地心说时期的科学家)惊叹不已,以此为基础,凯撒制定了儒略历2,即每年365天,每四年增加一个闰年,多一天。1500年来,人们根据他的计算决定农时,但是经过1500年,托勒密模型的累计误差,已经超过了10天,由于这个差距,欧洲农民从事农业生产的时间差出了一个节气,很影响农业发展。1582年,教皇格里高利十三世在儒略历的基础上删除了10天,然后将每世纪最后一年的闰年改为平年,然后每400年再补回一个闰年,这就是我们今天用的日历3,小时候就曾背过的口诀“4年一闰,100年不闰,400年又闰”说的就正是这个规则,这个日历几乎没有误差。
但是想一想,40-60个套在一起的圆的模型,用今天的计算机也很难求解;对于模型的内在原理,当然就更没有人能给出解释(恐怕包括托勒密自己,从现代的观点来看,地心学说本就是无法解释的)。虽然格里高利十三世“凑”出了相对准确的算法,但他并没有从理论上找出原因,因为这种凑的做法很难举一反三。纠正地心说错误不能只靠在40几个圆的模型上再多套几个圆,而要进一步探索真理。波兰天文学家哥白尼发现如果以太阳为中心,只需要8-10个圆,因此他提出了日心说4,然而遗憾的是,哥白尼正确的假设并没有得到比托勒密模型更好的结果,相反,他的模型误差要大不少。哥白尼生前害怕惹怒教会,迟迟不敢发表自己的学说,直到临终前才发表;同时由于准确性的原因,这个正确的模型在当时又很难被人接受,甚至被当作“邪说”。
想让日心说被人们心悦诚服地接受,需要用它准确地描述行星行动,完成这一使命的是约翰内斯-开普勒。在所有一流天文学家中,开普勒资质较差,一生犯了无数错误,但他有两样别人没有的东西:从老师第谷手中继承的大量精确的观测数据,和运气(有时候,运气也是科学研究实力的一部分)。开普勒很幸运地发现了行星围绕太阳运转的轨道实际上是椭圆形的,这样不需要用多个小圆套大圆,只要一个椭圆就能将运动规律描述清楚了。(从现代的视角回望,托勒密继承了毕达哥拉斯“圆为至美”的思想,获得了思维上的引导,或许也带来了持续千年的桎梏。)由此,开普勒提出了三大行星运动定律5,大部分高中生就能从高中课本中学到,形式非常简单,不过开普勒的知识水平还不足以解释为什么行星的轨迹是椭圆形的。这一行星运动轨迹为什么是椭圆形这个伟大而艰巨的任务,最后由牛顿用万有引力解释得清清楚楚。
许多年后,日心说的故事又起了小的波澜,1821年法国天文学家瓦布尔发现,天王星的实际轨迹与借助椭圆模型算出来的不太符合。当然,偷懒的办法是借助小圆套大圆的方法修正,但不少严肃的科学家却努力寻找真正的原因。不久,天文学家们发现了吸引天王星偏离轨道的海王星,这正是好的数学模型应用于天文发现的优秀例证。
从这个天文学的例子中,可以总结出关于建立数学模型的以下几个结论:
1.一个正确的数学模型,在形式上应当是简单的。这一点在逻辑学上有一个专门的表述——“奥卡姆剃刀原理”:这个原理可简单表述为“如无必要,勿增实体”,或者说如果一个事情有多种解释,那么最可能的正确的解释就是最简单的那个,即假设更少的那个。这一点在很多自然学科中是得以印证的,物理学家很早就形成了共识:越是简单的物理公式,越有可能接近真相。自然的规律本就是以简单为美,“简单性”也为后面的结论提供了理论基础。
2.一个正确的模型可能一开始还不如一个精雕细琢过的错误模型来的准确,我们如果认为一个模型的大方向是对的,就应该坚持下去。(“精雕细琢过的错误模型”是不是违背了结论1中“简单性”的原则呢?所以它很有可能是错误的。)
3.正确的模型也可能受到噪声干扰而显得不够准确,这时不应该用凑合的修正方法加以弥补,而要找到噪声的根源,或许能通往更大的发现。(参考海王星的发现,如果只是用小圆套大圆继续修正,是不是就错过了发现的机会?反复的修正,是否也违背了结论1“简单性”的原则呢?)
4.大量的数据对研发很重要。
上面的4个结论是从天文学的发展中总结出的,却在自然科学中极具普适性。在本文后面的部分中会多次印证这些结论(尤其是第一条)在科学研究中对建立数学模型的指导意义。
“不要把鸡蛋放在一个篮子里”——最大熵模型
数学模型的应用在各个领域数不胜数,这里我想谈谈在经济学以及机器学习领域应用广泛的最大熵模型。
知名投资人、人工智能与语音识别专家吴军博士在AT&T实验室作关于最大熵模型的报告时,拿出一个骰子,问听众“每个面向上的概率是多少”,所有人都说是等概率,每个面六分之一。他问听众们为什么,得到的回答都是:对于“一无所知的骰子”,假设它每个面向上的概率是均等的是最安全的做法。接着,吴军博士又告诉听众,他对这个骰子做过特殊处理,使得四点朝上的概率是三分之一,然后又问听众“在这种情况下,其它各面朝上的概率又是多少”。这次,大部分人认为其他五个面的概率均为剩下2/3的五分之一,也就是2/15,也就是说除去已知的条件必须满足,而对其余各点的概率无从知道,只好认为它们相等。在猜测上述两种不同情况的概率分布时,大家都没有添加任何主观假设(比如骰子是韦小宝的灌了铅的骰子,或者4点的背面一定是3点,等等)。这种基于直觉的猜测之所以正确,正是因为最大熵原理。
最大熵原理指出,对一个随机事件的概率分布进行预测时,我们的预测应该满足所有的已知条件,而对未知的情况不作任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。我们常说“不要把鸡蛋放在一个篮子里”,也正是这个原理的一个朴素的提法。
显然,前面的定义对于投资人或者神经网络的工程师来说,已经很具有指导意义,但是对于一个十分重视逻辑严谨性的数学研究者,前面的定义是不可接受的(什么叫“主观假设”?什么是“预测的风险”?)。甚至,什么是“熵”,也还没有一个明确的定义。熵(entropy),是从热力学中的概念, 由香浓引入到信息论中。在高中物理热力学这一章节,老师可能说过:熵是用来衡量分子运动混乱程度的物理量。熵之所以重要,因为它总结了宇宙的基本发展规律:宇宙中的事务都有向着混乱发展的趋势,也就是熵增原理(比如我的寝室,我的书桌) 。在信息论和概率统计中,扩展了熵的内涵,用来表示随机变量不确定性的度量。这样的描述显然还是不能满足数学家的要求,概率统计中对熵有如下的定义:

可以看出,H(x)依赖于X的分布,而与X的具体值无关。H(X)越大,表示X的不确定性越大。在此基础上,又扩展出条件熵:

现在已经对熵的定义有了初步的认识,但还是远远不够的。最大熵原理具有相对复杂和深奥的定义基础和推导过程(如拉格朗日乘子,贝叶斯定理,特征函数等),限于本人的水平和本文的篇幅,只能对其作大致的解释,详细的讲述可参考文末列出的参考资料6。这里仅直接给出最大熵模型的定义:对于给定的数据集T, 特征函数 f i (x,y),i=1,…,n ,最大熵模型就是求解模型集合C中条件熵最大的模型。
匈牙利著名数学家,信息论最高奖香农奖得主I.Csiszar证明,对任何一组不自相矛盾的信息,最大熵模型总是存在且是唯一的。此外它们还具有一个非常简单的形式——指数函数。最大熵模型在形式上具有的简单和优美,使得其在自然语言处理(多义词的理解)和金融领域(对冲基金,风险预测)大展拳脚。很多之前的问题,科学家们通过复杂的参数补丁(类比前面的大圆套小圆)都很难有效解决,却被最大熵模型完美地解决了,这一点,也再一次体现了自然规律中“简单即是美”的特点。下面列举自然语言处理和金融领域各一例来例证最大熵模型的应用场景。
(1)原微软研究员Adwait Ratnaparkhi在研究词性标注和句法分析等自然语言处理问题时,将上下文信息、词性,以及主谓宾等句子成分,通过最大熵模型结合起来,做出了当时世界最好的词性标识系统和句法分析器,这一模型至今仍是使用单一方法的系统中效果最好的。
(2)华尔街的金融巨鳄们向来喜欢用新技术提高他们的收益(对于他们来说,几个百分点的期望提升收益或许都将是不可想象的),证券交易需要考虑非常多的复杂模型,之前仅依靠权重参数的方法收益率貌似已经到达了瓶颈,因此,在最大熵模型提出之后,很多对冲基金开始使用最大熵模型,并且取得了很好的成果。
总结来说,最大熵模型将各种信息整合到一个统一的模型中,它有很多良好的特性:形式简单,非常优美;能满足各个信息源的限制又保持平滑。因此其应用范围极广。而这个模型的灵感源泉,或许正是“不要把鸡蛋放到一个篮子里”这样一个简单朴素的生活经验。
能“思考”的机器——人工神经网络
浅谈神经网络
在科幻小说中,我们的未来有时被描绘成这样的乌托邦:机器助手能只需要一句指示就能为主人完成各种工作;自动驾驶汽车在道路甚至是半空中快速飞驰,而丝毫不出差错;智能机器人能够胜任大部分工作,人们只需享受轻松的生活。有时这一未来又被渲染成恐怖的场景:高度智能化的机器人不受人类的控制,拥有独立思考的能力,最终统治、甚至毁灭人类。科幻小说难免有夸张的成分,但还是足以证明人工智能的发展对于人类世界的重大影响力。尤其是20世纪80年代人工神经网络技术兴起以来,基于神经网络的深度学习技术发展迅速,尤其是近年来,深度学习、神经网络的研究已然掀起了又一波热潮,吸引着大量的人才和资金投资;而且统计数据表明,深度学习目前似乎还正处于科学发展S型曲线的前半部分7,在不久的将来可能还将大有发展。如今,人工神经网络已经在自动控制、生物、医学、经济等等领域都大有作为。
如今(2020年)的机器学习或深度学习大多是基于人工神经网络进行的,本文将侧重点放在人工神经网络体现出的数学模型和数学方法上。人工神经网络这个词乍一听是用人工的办法模拟人脑,似乎是仿生学或者认知科学的问题,让人感觉十分神秘,毕竟到目前为止,人脑的工作方式还没有被人类完全搞懂(甚至可以说一无所知?而这会不会是神经网络的极限所在呢?)。然而,其实除了借用一些生物学的名词,做了一些形象的比喻以外,目前的人工神经网络和人脑没有半点关系,其本质上是一种分层的数学模型,最终目标是通过一系列简单的数学变换(层)实现从输入到目标的映射,而这种数据变换的方式是通过观察示例学习得到的。神经网络每层对输入数据的操作保存在该层的权重参数中,而“深度学习”中,”深度“的意思正是指的神经网络模型"分层"的这一特点;”学习“,指的正是通过示例修正这些参数的过程(简称调参,一些智能科学研究人员喜欢形象地称之为”炼丹“)。下图是一个三层的神经网络。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jwjags6i-1609590996789)(/image-20210102110646792.png)]](https://img-blog.csdnimg.cn/20210102204106322.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FoYWFoYQ==,size_16,color_FFFFFF,t_70)
神经网络模型在数学上实际就是一种特殊的有向图,其节点被称之为”神经元“,而前面所说的权重参数由边权来表示。除此之外,神经网络模型还有一些基本的要求:
(1)所有的节点都是分层的,每一层节点可以通过有向弧指向其下一层,不能跃层连接,同一层的节点之间也没有弧相连。
(2)每一条弧有一个边权,表示弧尾节点之于弧头节点的权重,根据这些值,可以用一个简单的公式计算下一层节点的值,更详细地讲,从前一层计算后一层的公式应该满足(粗体表示向量或张量):Y = f(XW)的形式,即Y由前一层X做一次线性变换,然后使用一个激活函数f得到。这么做是为了保持模型每一层的简单性——一次线性变换+一次映射,利于大规模训练时的分布式计算。
神经网络训练
对于一个具体的深度学习任务,还有一点是必不可少的,那就是定义损失函数。损失函数用来衡量网络预测值与真实目标值的差距。在训练过程中,往往会根据损失函数的值来代表模型预测与期望的差距,对前面的权重参数进行修正(通过梯度下降,反式微分的方式)。本文探讨的重点不是具体的计算,而是如何选择一个好的神经网络模型,当然这是一个很复杂的问题,没有一个确定的答案,我们能做的是从大的方向上概述模型选择的原则。我们将使用一个具体的例子:有一份1000个样本的新闻数据集,我们希望得到一个新闻分类器:输入一篇文章,分类器将新闻分为”时政“、”娱乐“、”金融“三类之一。(当然现实中会有更多种类,但是作为一个例子,三类已经足够了。)我们希望使用关键词(最常出现的20个)是否出现作为特征,也就是输入向量是一个二进制的序列[x1,x2……x20], xi = 1代表第i个关键词出现在本文中,xi = 0代表并未出现。最终输出的应该是一个取值1~3的数字,代表分类结果。那么我们需要做以下几步工作:
(1)将数据集分为训练集和测试集,分别用来训练模型和测试最终的模型正确率。我们例子中假定样本是带标注的,即每一篇文章都已经对应好一种预期的分类。
(2)对样本进行预处理,即处理数据集中的文章,变为前述20维0/1向量的输入形式。
(3)设计模型。主要包括:模型的层数,每一层的初始参数和激活函数,损失函数,以及每一轮迭代过后对参数的修正幅度(梯度下降法中的步长)。同时还要确定训练过程的迭代轮数。
(4)在训练集上训练。
(5)根据效果修正模型反复训练。
(6)在测试集上测试。
模型设计的原则
我们重点关注的是第三步——设计模型。在模型的设计中,有以下几点需要说明:
(1)如何设定模型的层数和参数数量。
是越多越好吗?答案显然是否定的,一个显而易见的原因就是算力资源,越多的层数和参数势必会带来更大的计算复杂度,这也是上世纪机器学习发展缓慢的原因之一。在不考虑算力资源的情况下,层数和参数越多模型的正确率就一定会越高吗?答案也是否定的。这一点可能会有些违背人的第一感觉,一些人可能会觉得参数变多,势必能在数学上获得更好的拟合效果,模型也就更加”准确“。但值得注意的是,这个准确是在训练集上的,而我们训练模型的最终目的显然不是为了让其只能应用于训练集中,而是任意的类似问题。实际上模型的层数和参数数量设计的关键不是数量,而是提取的特征是否是真正有用的信息。举一个极端的例子,在前面的分类模型中,我们如果将输入参数的维度设置为1,也就是一个数字,使得其取值范围为1900,正好对应900个训练样本,那么是不是只需要一个1900到数集{1,2,3}的映射,就可以正确率100%的解决训练集上的分类?但这个模型显然对于任何新的文本是没有效果的。或者,如果一味加大中间层的参数数量,这个模型就可能会学到只适用于训练集中的模式,比如”姓王的记者报道的是娱乐新闻“,这种看起来无厘头但是训练集中又恰巧出现的模式。
这正体现了深度学习过程中优化与泛化的矛盾性,机器学习的目的是获得良好的泛化,而我们无法调整泛化,只能基于训练数据调整模型。过度的优化是不是又很想文章开头”地心说“例子中大圆套小圆的做法?这又一次体现了简单性在模型设计中的指导意义。
(2)激活函数和损失函数的选择
这与本文的主旨关系不大,但又是十分重要的一部分,激活函数和损失函数往往具有平滑曲线或是归一化的作用,常用的有sigmoid函数、softmax函数等。
(3)迭代的次数是越多越好吗?
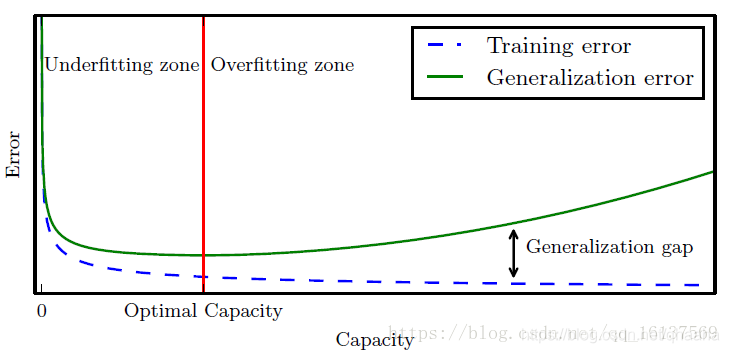
答案是否定的。这个问题和前面的增加层数和参数数量有很大的相似性。在训练过程中有一个很常见的现象就是过拟合,在迭代的初期,随着迭代次数的增加,在测试集(实际上应该是验证集)和训练集的损失都在下降,此时是欠拟合状态,可以理解为模型还在识别对于目标任务有用的模式信息;随着迭代的进行,测试集的损失值会到达一个下限,之后,随着迭代次数的增加,在训练集上的损失还会下降,但是在测试集上的损失会逐渐上升(如下图)。为什么会逐渐上升?答案正是发生了过拟合,模型自动识别了训练集上特有的模式,就比如前面的”姓王的记者报道的是娱乐新闻“,而这在测试集上很可能是没有的。
为什么有多余的模式就会带来更大的损失呢?这一点恰恰可以由前面的最大熵原理来解释:最大熵原理指出,对一个随机事件的概率分布进行预测时,我们的预测应该满足所有的已知条件,而对未知的情况不作任何主观假设。显然,多余的模式违背了对未知情况不作主观假设这一要求,因此在测试集上性能显著下降。考虑之前天文学中通过打补丁的方式修正模型,最终获得的模型势必在其它的星系也不会获得理想的收获。
神经网络模型的建立是复杂的过程,需要大量的经验和尝试,本文只是管中窥豹,试图从神经网络模型中寻找其蕴含的数学哲理,以及数学模型的一些法则——比如”简单性“与”普适性“。我的水平十分有限,从大处着眼泛泛地讲述了神经网络模型,希望能传播这样一个道理:即使像神经网络这样听起来很”高大上“且抽象的现代技术,其本质上也是通过非常朴素的数学模型设计和建立,正如高斯所言”数学,科学的皇后;算术,数学的皇后“,掌握数学模型的原则和方法,将会使各行各业的研究人员从中获益匪浅。
结语
本文从地心学说的兴废、最大熵模型的应用、人工神经网络模型三个很贴近应用领域的例子出发,浅谈了数学模型在其中发挥的至关重要的作用,以及一些基本设计原则。一方面希望给各个领域的科学工作者们一点点思路的启迪;另一方面也希望能让更多的科学工作者看到数学在科技发展中的不可忽视的重要作用,激励更多的研究者沉心静气,做一些底层的、或许与时下应用无关的、更接近数学本质的工作。
-
地心学说的主要观点以“地球位于宇宙中心静止不动”为基础。
-
根据天文学家索西琴尼的计算。
-
为了纪念他,这种历法也叫“格里高利日历”
-
相对于“地心说”,日心说的主要观点以“太阳为宇宙中心”为基础。
-
①椭圆定律:所有行星绕太阳的轨道都是椭圆,太阳在椭圆的一个焦点上。②面积定律:行星和太阳的连线在相等的时间间隔内扫过的面积相等。③调和定律:所有行星绕太阳一周的恒星时间的平方与它们轨道半长轴的立方成比例
-
关于最大熵模型,可参考:李航 《统计学习方法[M]》 清华大学出版社; 概述网址:https://zhuanlan.zhihu.com/p/29978153
-
科学发展的S型曲线:科技发展常会呈现出S形曲线。开始增长缓慢,直到引爆点突然加速,然后逐渐减速被新的技术替代。