在软件领域内,有诸多编码解码的应用场景,而对于编码一词的使用,在不同场景下也会有不同的语义表达,很多软件开发人员不堪其困扰,至少我本人是经历了很波折的一些过程。
举几个场景,比如:
- 字符集跟字符编码有什么关系,字符集就是字符编码么?
- 乱码,从网络上下载的文件,本地打开乱码到底是为何?
- dubbo请求链路中,编解码是怎么处理的,dubbo的编解码跟其他场景的编解码有何不同?
- Http body中header中定义的charset跟编码,压缩的关系是什么?
- Http url中文场景下,在浏览器中为何会出现百分号?
- http协议中定义的编码方式和字符集,分别是什么意思?
- http的请求过程中,到底哪些地方有编码,序列化,整个过程是怎样的?
本文总结并梳理在日常工作过程中,编解码的一些场景以及不同场景下编解码语义上的一些差异,希望在沟通对焦以及阅读相关文档的过程中对于编解码的含义,更聚焦和明确,对大家的日常工作有所帮助。
一,编码与解码
哲学中成对出现的概念。
在讲清楚这一对矛盾体之前,先试着给它们下个定义:
- 编码是信息从一种形式或格式转换为另一种形式的过程;
- 解码是编码的逆过程。
在计算机领域,1和0是计算机存储和识别的最小单元,计算机外的信息转化成计算机能识别的形式就需要编码了。当然在计算机领域内部,也存在着各种格式转换(也称为编码),比如TCP/IP四层协议转换,各层的格式是不同的;应用进程中,对象转成字节码,转成json,xml等。
区分在各种不同的场景下编码的具体语义,可能会有点让人头疼!我们把范围画小些,聚焦下,我们讲述的是计算机应用内,应用间,网络通信,数据存储等场景下的编码;该种形式的编码最终目的是存储(持久化到磁盘)和传输(网络通信,或应用进程通信)。
我们以软件从业人员常见的几种场景开始讲起:
1.1 字符编解码
我们规范下本文的语义:字符编码指的是字符转换成字节,字符解码是从字节转换成字符。
所有的软件开发人员都遇到过乱码的问题,比如:在文本存储时,选择gb2312编码保存中文汉字,这时候使用utf-8编码格式打开文本,就会出现乱码,如下:
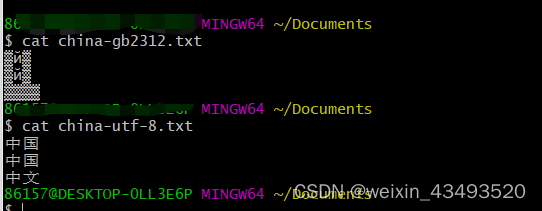
字符集和编码
至于为何会乱码,在讲清楚乱码原因之前,我们先对焦两个概念:字符集和编码格式, 这两个概念在很多场景下总是混在一起,我们有必要先对齐,讲清楚。
● 字符集用于用户展示,比如:“中国”二字使用gbk字符集时,映射为:D6D0 B9FA;而在unicode字符集下映射为:4E2D 56FD。 当使用错误的字符集去展示时,乱码就出现了。
● 编码用于存储以及网络传输,gbk既是字符集也是编码格式,unicode是字符集,utf-8是其常用的编码格式(其他还有utf-16,utf-32等)。
编解码过程分析
有点绕,我们以文本编辑器(vi等)为例,描述下整个过程:在mac os的LANG="zh_CN.UTF-8"的前提下,内存中的字符集使用unicode,我们使用vi编辑器打开一空文本,输入’中国‘二字,‘中国’两个字在内存中对应的字节为:4E2D 56FD,大家在屏幕上看到了‘中国’两个字;当保存时,使用utf-8进行编码,变成了:E4B8AD E59BBD,存储到磁盘。文件的字符集和编码方式为:UTF-8 Unicode text
admin@admindeMacBook-Pro ~ % cat test.txt
中国
admin@admindeMacBook-Pro ~ % file test.txt
test.txt: UTF-8 Unicode text
当我们重新打开文件时,数据从磁盘加载到内存,使用utf8解码, 使用unicode字符集,内存中存储为:4E2D 56FD,用户界面展示出 ‘中国’二字。
另外说明下,gbk既是一种字符集也是编码格式,当我们os环境是gbk且使用gbk编码存储时,内存以及磁盘存储都是D6D0 B9FA。
这里可能有同学会问了,为何unicode不使用4E2D 56FD直接存储而使用utf8存储呢,存储的字节反而更多更长了? 这是因为unicode是定长的编码方式,每个字符用16byte存储;而utf8是变长的编码方式,兼容Asccii编码,英文字符只需要8byte存储,对于大部分存储英文字节的场景,在空间上更有优势。
“中国”二字使用不同的字符集,对应的byte码如下:
● unicode表示为: 4E2D 56FD
● UTF-8表示为: E4B8AD E59BBD
● GBK表示为: D6D0 B9FA
编解码举例
我们仍然以mac系统(LANG=“zh_CN.UTF-8”)为例,分别对比下,英文字符“ab”和中文字符“中国”的存储以及显示器展示,
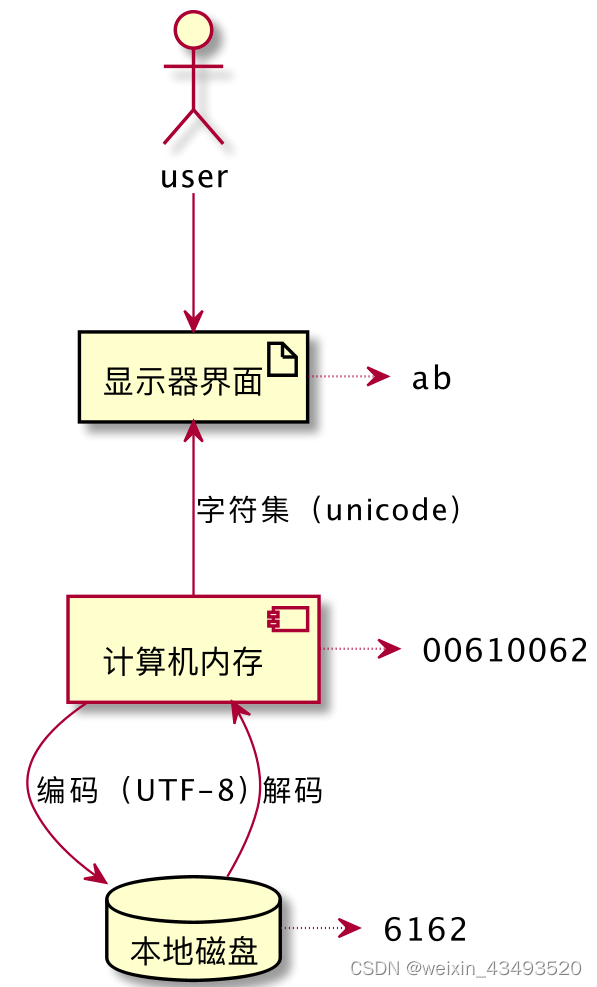
** 对于英文字符“ab”来说 **,
磁盘存储时使用utf-8编码,十六进制表示为“6162”;
读取到内存中时,十六进制对应的是 “00610062”;
显示器前,unicode字符集映射,用户看到则的是“ab”
“ab”字符的编码解码以及显示器展示的过程表示如下:
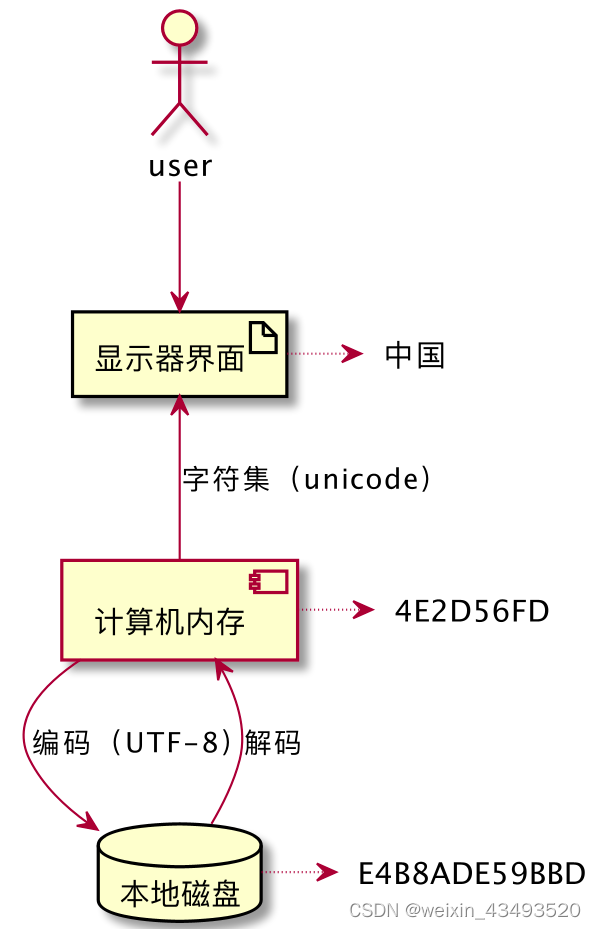
** 对于中文字符“中国”来说** ,
磁盘存储时使用utf-8编码,十六进制表示为“E4B8ADE59BBD”;
读取到内存中时,十六进制对应的是 “4E2D56FD”;
显示器前,unicode字符集,用户看到则的是“中国”
编码解码以及显示器的展示过程表示如下:
1.2 http url编码
讲完了文本字符编码后,我们再看一下另一种常见的编码方式:http url编码。
RFC3986文档对Url的编解码问题做出了详细的讲述,指出了哪些字符需要被编码,以及编码规则是什么,如下:
Url中只允许包含以下四类字符:
1、英文字母(a-zA-Z)
2、数字(0-9)
3、-_.~ 4个特殊字符
4、所有保留字符
关于保留字符,RFC3986中指定了以下字符为保留字符(英文字符): ! * ’ ( ) ; : @ & = + $ , / ? # [ ]。 Url可以划分成若干个组件,协议、主机、路径等。有一些字符(
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)