缩放的欧氏距离
(
L
1
−
L
2
)
2
+
(
10
R
1
−
10
R
2
)
2
\sqrt{(L_1 - L_2)^2 + (10R_1-10R_2)^2}
(L1−L2)2+(10R1−10R2)2
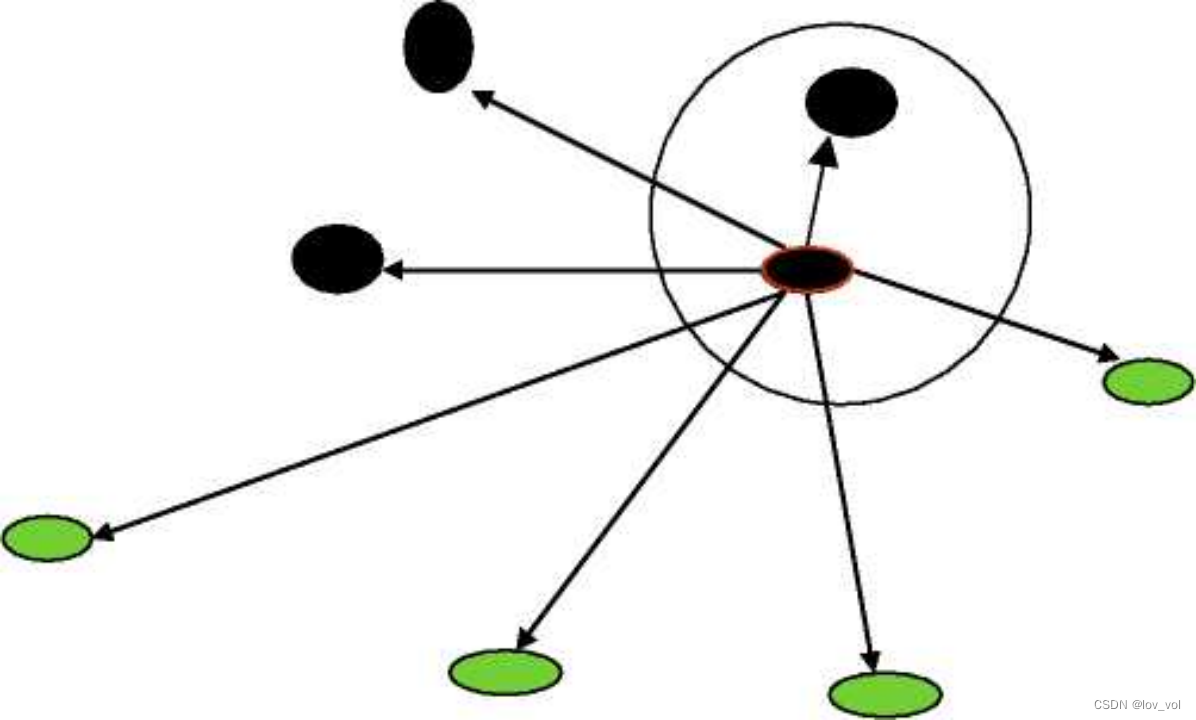
理论结果
无限多训练样本下1-NN的错误率界限:
E
r
r
(
B
y
t
e
s
)
≤
E
r
r
(
1
−
N
N
)
≤
E
r
r
(
B
y
t
e
s
)
(
2
−
K
K
−
1
E
r
r
(
B
a
y
e
s
)
)
Err(Bytes)\le Err(1-NN) \le Err(Bytes)\left(2-\frac{K}{K-1}Err(Bayes)\right)
Err(Bytes)≤Err(1−NN)≤Err(Bytes)(2−K−1KErr(Bayes))
Minkowski或
L
λ
L_\lambda
Lλ度量:
d
(
i
,
j
)
=
(
∑
k
=
1
p
∣
x
k
(
i
)
−
x
k
(
j
)
∣
λ
)
1
λ
d(i,j)=\left(\sum_{k=1}^{p}|x_k(i)-x_k(j)|^\lambda\right)^{\frac{1}{\lambda}}
d(i,j)=(k=1∑p∣xk(i)−xk(j)∣λ)λ1 k: 指的是维度,i和j指不同的数据点 计算在相同维度上不同点差值的绝对值的
λ
\lambda
λ次方,然后不同维度求和再开
λ
\lambda
λ次方 当
λ
\lambda
λ次方取不同值时,
L
λ
L_\lambda
Lλ距离表示的就是如下图形
欧几里得距离
(
λ
=
2
)
(\lambda=2)
(λ=2)
d
i
j
=
∑
k
=
1
p
(
x
i
k
−
x
j
k
)
2
d_{ij}=\sqrt{\sum_{k=1}^{p}(x_{ik}-x_{jk})^2}
dij=k=1∑p(xik−xjk)2
曼哈顿距离 Manhattan Distance 城市街区距离City block Dis. 出租车距离 Taxi Distance 或L1度量(
λ
=
1
\lambda=1
λ=1):
d
(
i
,
j
)
=
∑
k
=
1
p
∣
x
k
(
i
)
−
x
k
(
j
)
∣
d(i,j)=\sum_{k=1}^{p}|x_k(i)-x_k(j)|
d(i,j)=k=1∑p∣xk(i)−xk(j)∣ 在曼哈顿,街区都类似如下,不能走斜线,
切比雪夫距离(Chebyshev Distance) 棋盘距离(Chessboard Dis.)
L
∞
L_{\infty}
L∞
d
(
i
,
j
)
=
m
a
x
k
∣
x
k
(
i
)
−
x
k
(
j
)
∣
d(i,j)=\underset{k}{max}|x_k(i)-x_k(j)|
d(i,j)=kmax∣xk(i)−xk(j)∣ 国际象棋可以走斜线,因此两点之间取决于x差值和y差值的最大值
加权欧氏距离 Mean Censored Euclidean Weighted Euclidean Distance
∑
k
(
x
j
k
−
x
j
k
)
2
/
n
\sqrt{\sum_k(x_{jk}-x_{jk})^2/n}
k∑(xjk−xjk)2/n 欧氏距离每多一个维度,距离就更大一些,除以n后,维度的影响就降低了
Bray-Curtis Dist
∑
k
∣
x
j
k
−
x
j
k
∣
/
∑
k
(
x
j
k
−
x
j
k
)
\sum_{k} |x_{jk}-x_{jk}|\bigg/\sum_{k} (x_{jk}-x_{jk})
k∑∣xjk−xjk∣/k∑(xjk−xjk) 两个数据量点的差值和除以两个数据点的和的和 一般用于生物学上描述多样性用的比较多
堪培拉距离C anberra Dist.
∑
k
∣
x
j
k
−
x
j
k
∣
/
(
x
j
k
−
x
j
k
)
k
\frac{\sum_{k} {|x_{jk}-x_{jk}|\big/(x_{jk}-x_{jk})}}{k}
k∑k∣xjk−xjk∣/(xjk−xjk) 就是在Bray- Curtis Dist基础上做一些缩放
KNN 讨论2:属性
邻居间的距离可能被某些取值特别大的属性所支配
e.g.收入
D
i
s
(
J
o
h
n
,
R
a
c
h
e
l
)
=
(
35
−
45
)
2
+
(
95000
−
215000
)
2
+
(
3
−
2
)
2
Dis(John, Rachel)=\sqrt {(35-45)^2 + (95000-215000)^2+(3-2)^2}
Dis(John,Rachel)=(35−45)2+(95000−215000)2+(3−2)2 -对特征进行**归一化(Normalization)**是非常重要的(e.g.,把数值归一化到[0-1])
Log, Min-Max, Sum,Max…
log只是对数据进行了放缩,没有归一化到[0-1],有个优点:数据会变得相对均匀
Min-Max:
S
c
o
r
e
−
M
i
n
M
a
x
−
M
i
n
\frac{Score-Min}{Max-Min}
Max−MinScore−Min
Sum:
S
c
o
r
e
∑
S
c
o
r
e
\frac{Score}{\sum Score}
∑ScoreScore
Max:
S
c
o
r
e
M
a
x
\frac{Score}{Max}
MaxScore
KNN:属性归一化
顾客
年龄
收入(K)
卡片数
结果
John
35/63=0.55
35/200=0.175
3/4=0.75
No
Mary
22/63=0.34
50/200=0.25
2/4=0.5
Yes
Hannah
63/63=1
200/200=1
1/4=0.25
No
Tom
59/63=0.93
170/200=0.85
1/4=0.25
No
Nellie
25/63=0.39
40/200=0.2
4/4=1
Yes
David
37/63=0.58
50/200=0.25
2/4=0.5
Yes
KNN:属性加权
一个样例的分类是基于所有属性的
与属性的相关性无关——无关的属性也会被使用进来
根据每个属性的相关性进行加权
d
W
E
(
i
,
j
)
=
(
∑
k
=
1
p
w
k
(
x
k
(
i
)
−
x
k
(
j
)
)
2
)
1
2
d_{WE}(i,j)=\left(\sum_{k=1}^{p}w_k(x_k(i)-x_k(j))^2\right)^\frac{1}{2}
dWE(i,j)=(k=1∑pwk(xk(i)−xk(j))2)21
在距离空间对维度进行缩放
如
(
L
1
−
L
2
)
2
+
(
10
R
1
−
10
R
2
)
2
\sqrt{(L_1 - L_2)^2 + (10R_1-10R_2)^2}
(L1−L2)2+(10R1−10R2)2
wk = 0
→
\rightarrow
→消除对应维度(特征选择)
一个可能的加权方法: 使用互信息(mutual information)/(属性,类别)
I
(
X
,
Y
)
=
H
(
X
)
+
H
(
Y
)
−
H
(
X
,
Y
)
I(X,Y) = H(X)+H(Y)-H(X,Y)
I(X,Y)=H(X)+H(Y)−H(X,Y) H:熵(entropy) Y是类别,最后的标签
H
(
X
,
Y
)
=
−
∑
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
H(X,Y) = -\sum p(x,y)logp(x,y)
H(X,Y)=−∑p(x,y)logp(x,y) 联合熵 (joint entropy)(利用熵的公式
H
(
y
)
=
−
∑
p
(
y
)
l
o
g
p
(
y
)
H(y) = -\sum p(y)logp(y)
H(y)=−∑p(y)logp(y)) x和y接近关系不同,互信息不同,利用互信息来代表这个维度的重要性wk
一个加权函数(可选) e.g.
w
i
=
e
x
p
(
−
D
(
x
i
,
q
u
e
r
y
)
2
/
K
w
2
)
w_i = exp(-D(x_i, query)^2 / K_w^2)
wi=exp(−D(xi,query)2/Kw2) Kw :核宽度。非常重要
如何使用已知的邻居节点? 首先构建一个局部的线性模型。拟合
β
\beta
β 最小化局部的加权平方误差和:
β
‾
=
a
r
g
m
i
n
β
∑
k
=
1
N
w
k
2
(
y
k
−
β
T
x
k
)
2
\underline\beta=\underset{\beta}{argmin} \sum_{k=1}^{N} w_k^2(y_k-\beta^Tx_k)^2
β=βargmink=1∑Nwk2(yk−βTxk)2 那么
y
p
r
e
d
i
c
t
=
β
‾
T
x
q
u
e
r
y
y_{predict} = \underline\beta^T x_{query}
ypredict=βTxquery