Redis
文章目录
- Redis
- 基础
- 和memcache的区别
- 为什么单线程能有很高的效率
- 具体原因
- 连接过程
- 一次连接流程
- 多个socket,io多路复用程序,消息队列,文件事件分派器,事件处理器(命令请求处理器、命令回复处理器、连接应答处理器,等等)
- 哪些类型
- string
- list
- hash
- set
- sort set
- 从海量数据中查找某个key前缀
-
- 持久化
-
- 序列化方式
- JdkSerializationRedisSerializer
- GenericJackson2JsonRedisSerializer
- StringRedisSerializer
- GenericFastJsonRedisSerializer
- 数据过期/淘汰
-
- 思维导图
- 博客连接
- Redis的应用--分布式锁
- Redis的基础
- Redis的生产问题-缓存雪崩-缓存穿透-双写一致性--并发竞争
- Redis的cluster集群
- Redis的replication架构(主从+哨兵
基础
和memcache的区别
- 数据结构
- 内存使用率,key-value的话memcache更好
- 效率,单个value的大小100k以上redis更好
- 集群部署,redis有原生支持
为什么单线程能有很高的效率
具体原因
- 单线程模型,避免了上下文切换
- IO多路复用机制
- 纯内存操作
连接过程
文件事件处理器(网络事件处理器、file event handler),这个是单线程的采用IO多路复用机制监听多个socket。
socket进来之后,如果有事件(比如说连接),IO多路复用程序就会将这个socket(这时候连接已经和connect事件绑定) 推到消息队列中。
文件事件分派器从队列中取出socket,检查事件,根据不同的事件分给不同的处理器。
包括多个socket,io多路复用程序,消息队列,文件事件分派器,事件处理器(命令请求处理器、命令回复处理器、连接应答处理器,等等)

一次连接流程
- 服务端打开socket监听
- 客户端和服务端连接socket,这时候产生一个connect事件,后台表示为AE_READABLE
- io多路复用程序将这个socket推到消息队列里面
- 分派器判断是 连接应答处理器,进行处理,连接成功
- 这时候将socket和ae_writeable绑定,
- io多路复用程序看到这个又有事件了,就又推到消息队列
- 分派器判断是 命令回复处理器,就返回数据,然后和这个事件取消关联
多个socket,io多路复用程序,消息队列,文件事件分派器,事件处理器(命令请求处理器、命令回复处理器、连接应答处理器,等等)
哪些类型
string
- 字符串
- set key val,get key
- 简单的key-value存储,部门组织树,用户数据
list
- 数组
- lpush key val1 val2,lpop key,lrange key 0 10
- 存粉丝、评论、lrange可以分页,消息队列
hash
- 键值对
- hmset key key1 val1 key2 val2,hget key key1
- 用户信息-鉴权码-私钥
set
- 不重复无序列表
- sadd key val1 val2,smembers key
- 部门关系缓存
sort set
- 有序数组/带权重值列表
- zadd key score1 val1 score2 val2,zrangebyscore key
- 排行榜
从海量数据中查找某个key前缀
keys
keys pattern,
一次性返回全部满足条件数据,会阻塞redis
scan
scan cursor pattern count,
按pattern条件从下标cursor开始找count个数据,不一定会是count,大致相等。返回结果包括下一个游标位置和列表
持久化
持久化的意义
- 故障恢复
- 云备份到一个存储上
rdb
- 内存快照的形式
- RDB方式,sava 600 10,600秒内有10次写操作,则触发。
- 将数据快照保存,有可能丢失数据。
- 优点:适合做冷备份、性能(不需要每时每刻),恢复快
- 缺点:丢数据
aof
- 把所有操作指令保存下来,存到一个文件中
- 内存和文件中有一层os-cache,每隔1s会调用f-sync
- 一次只会写一个aof文件
- aof文件不可能无限增大,BG-REWRITE-AOF。会根据当前快照,进行重写aof文件
- 优点:数据丢少(1s),append-only模式写磁盘-速度快,记录是人可读的
- 缺点:占用磁盘大,qps写会降低,脆弱点,数据恢复比较慢
序列化方式
JdkSerializationRedisSerializer
使用JDK提供的序列化功能。 优点是反序列化时不需要提供类型信息(class),但缺点是需要实现Serializable接口,还有序列化后的结果非常庞大,是JSON格式的5倍左右,这样就会消耗redis服务器的大量内存。
GenericJackson2JsonRedisSerializer
StringRedisSerializer
不能序列化Bean,只能序列化字符串类型的数据,
如果value都是字符串类型,可以用该方式序列化
GenericFastJsonRedisSerializer
数据过期/淘汰
- 这个是缓存,有容量限制
- 过期之后,还是占用内存
过期策略
设置了过期时间的key什么时候删除?定期删除和惰性删除,
这2个结合起来还是有可能漏掉一些key,这时候就需要内存淘汰机制登场
定期删除
每隔100ms随机抽去一些设置了超时时间的key,检查是否过期
过期则删除
这个会导致有可能一些key已经过期,但是没有删掉
惰性删除
查询某个key的时候,惰性检查,是否过期
如果过期则返回空
内存淘汰机制
redis内存占用过多的时候,会进行内存淘汰
具体策略
- noeviction,报错
- allkeys-lru,所有key走lru算法
- allkeys-random,所有key走随机删除
- volatile-lru,设置过期时间走lru算法
- volatile-random,设置过期时间的key走随机删除
- volatile-ttl,设置过期时间的key走"按过期时间最短"的算法
LRU代码实现
链表+hashmap
add、remove、refresh用来操作链表
get、put用来提供api
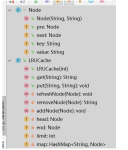
package com.lizhaoblog.code.io.redis;
import java.util.HashMap;
class Node {
public Node(String key, String value) {
this.key = key;
this.value = value;
}
public Node pre;
public Node next;
public String key;
public String value;
}
public class LRUCache {
private Node head;
private Node end;
//缓存上限
private int limit;
private HashMap<String,Node> map;
public LRUCache(int limit) {
this.limit = limit;
map = new HashMap();
}
public String get(String key) {
Node node = map.get(key);
if (node == null) {
return null;
}
//调整node到尾部
refreshNode(node);
return node.value;
}
public void put(String key, String value) {
Node node = map.get(key);
if (node == null) {
//key不存在直接插入
while (map.size() >= limit) {
//去除链表内的节点
String oldKey = removeNode(head);
//去除map中的缓存
map.remove(oldKey);
}
node = new Node(key, value);
//链表中加入节点
addNode(node);
//map中加入节点
map.put(key, node);
} else {
//更新节点并调整到尾部
node.value = value;
refreshNode(node);
}
}
private void refreshNode(Node node) {
//如果访问的是尾节点,无须移动节点
if (node == end) {
return;
}
//把节点移动到尾部,相当于做一次删除插入操作
removeNode(node);
addNode(node);
}
private String removeNode(Node node) {
//尾节点
if (node == end) {
end = end.pre;
} else if (node == head) {
//头结点
head = head.next;
} else {
//中间节点
node.pre.next = node.next;
node.next.pre = node.pre;
}
return node.key;
}
private void addNode(Node node) {
if (end != null) {
end.next = node;
node.pre = end;
node.next = null;
}
end = node;
if (head == null) {
head = node;
}
}
}
思维导图
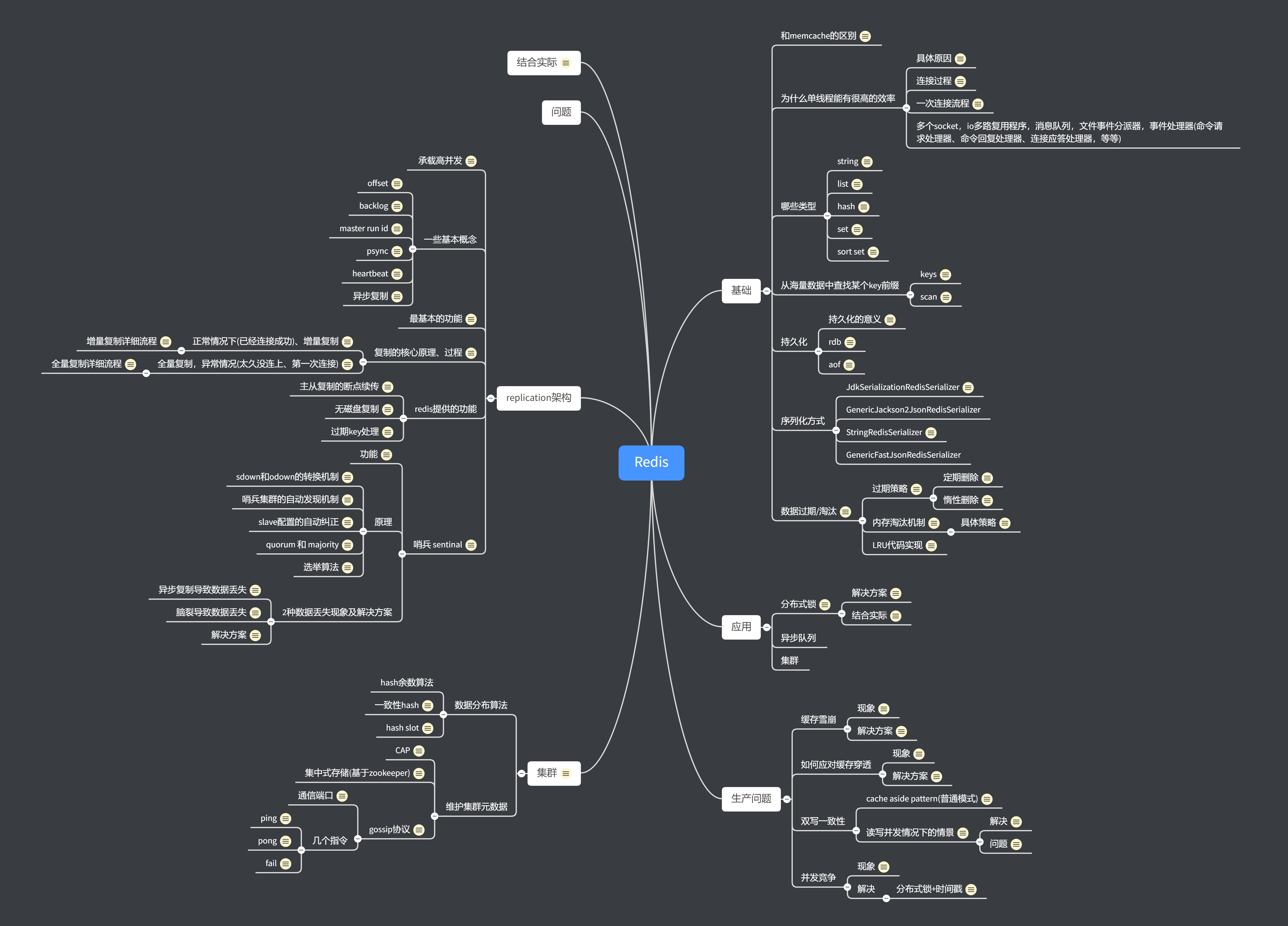
博客连接
Redis的应用–分布式锁
Redis的应用–分布式锁
Redis的基础
Redis的基础
Redis的生产问题-缓存雪崩-缓存穿透-双写一致性–并发竞争
Redis的生产问题-缓存雪崩-缓存穿透-双写一致性–并发竞争
Redis的cluster集群
Redis的cluster集群
Redis的replication架构(主从+哨兵
Redis的replication架构(主从+哨兵)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)