目录
一、需求说明
二、步骤
1、检查当前页面的URL所获得的响应的数据
①笨办法——程序验证(不建议)
②简单办法——抓包
③验证(抓包,推荐)
④动态加载验证
⑤查找页面的信息
2、获取排行页面数据
①操作
②源码
③信息解析
3、详情页面分析
①寻找URL
②验证URL
③获取URL
④获取内容
三、源码
一、需求说明
爬取华为应用市场排行页面下的APP的详情页
二、步骤
1、检查当前页面的URL所获得的响应的数据
①笨办法——程序验证(不建议)
将URL复制到python环境中,通过requests的四步去得到其相应的内容
②简单办法——抓包
通过检查页面找到当前页的相应内容,然后检查里面的内容是否是想要的
先在页面点鼠标右键,然后选项的最下面就是检查了,然后进行如下操作
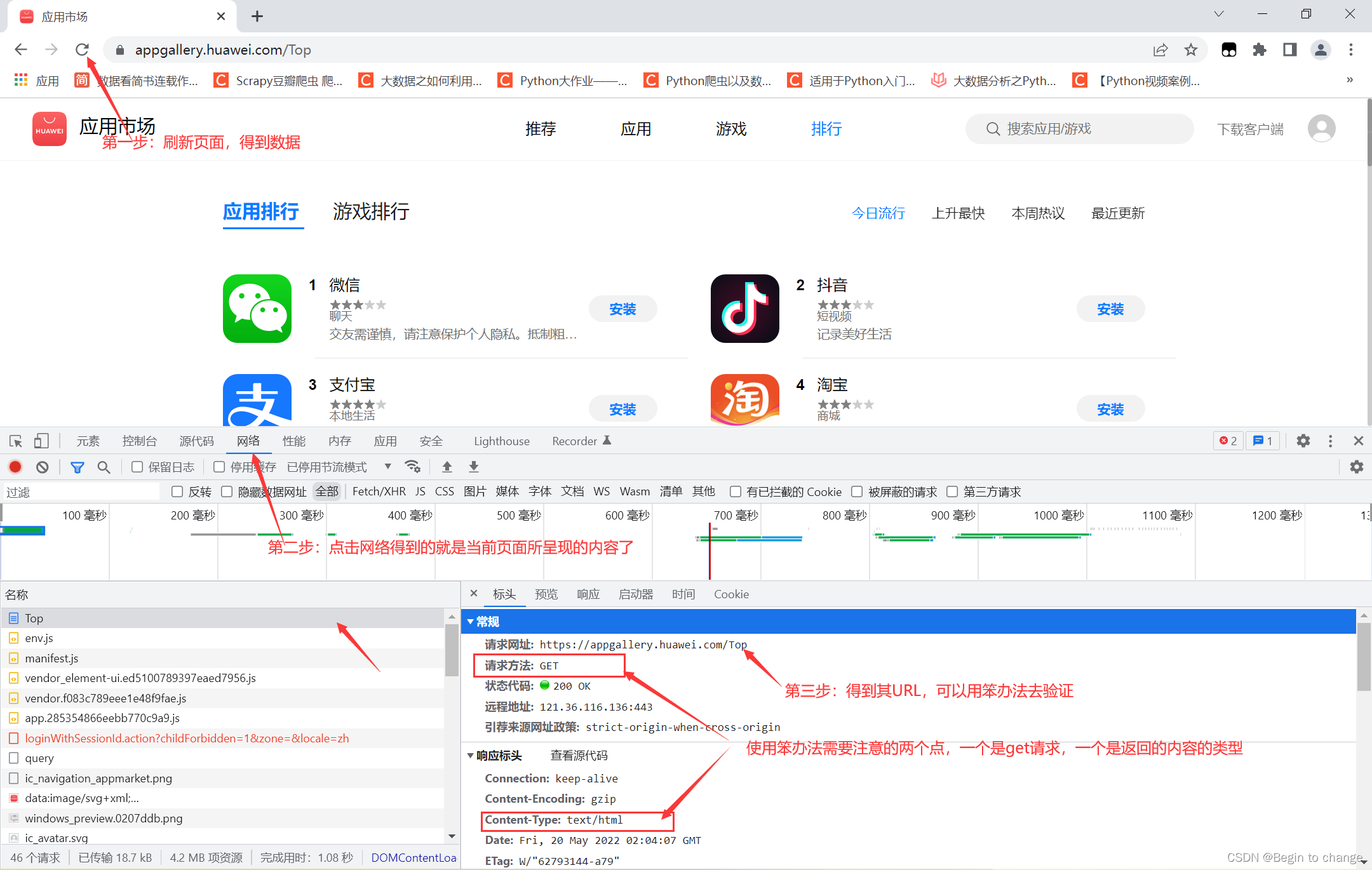
③验证(抓包,推荐)
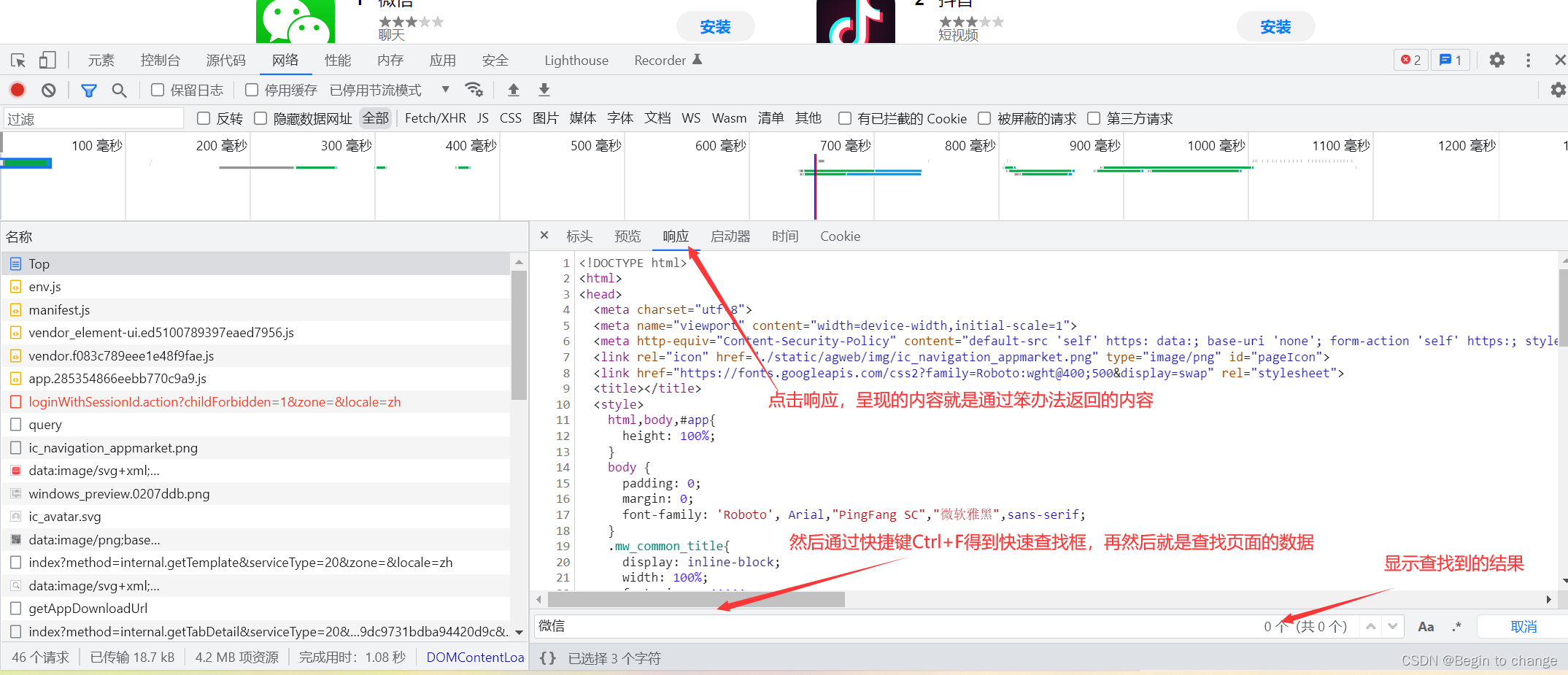
根据结果显示,通过URL得到的内容不是页面所呈现的内容,做出可能是ajax的动态加载
④动态加载验证

⑤查找页面的信息
通过上一步的验证发现,其得到的内容并不是页面的内容,所以加下来要继续查找;
查找方向为全部的响应信息
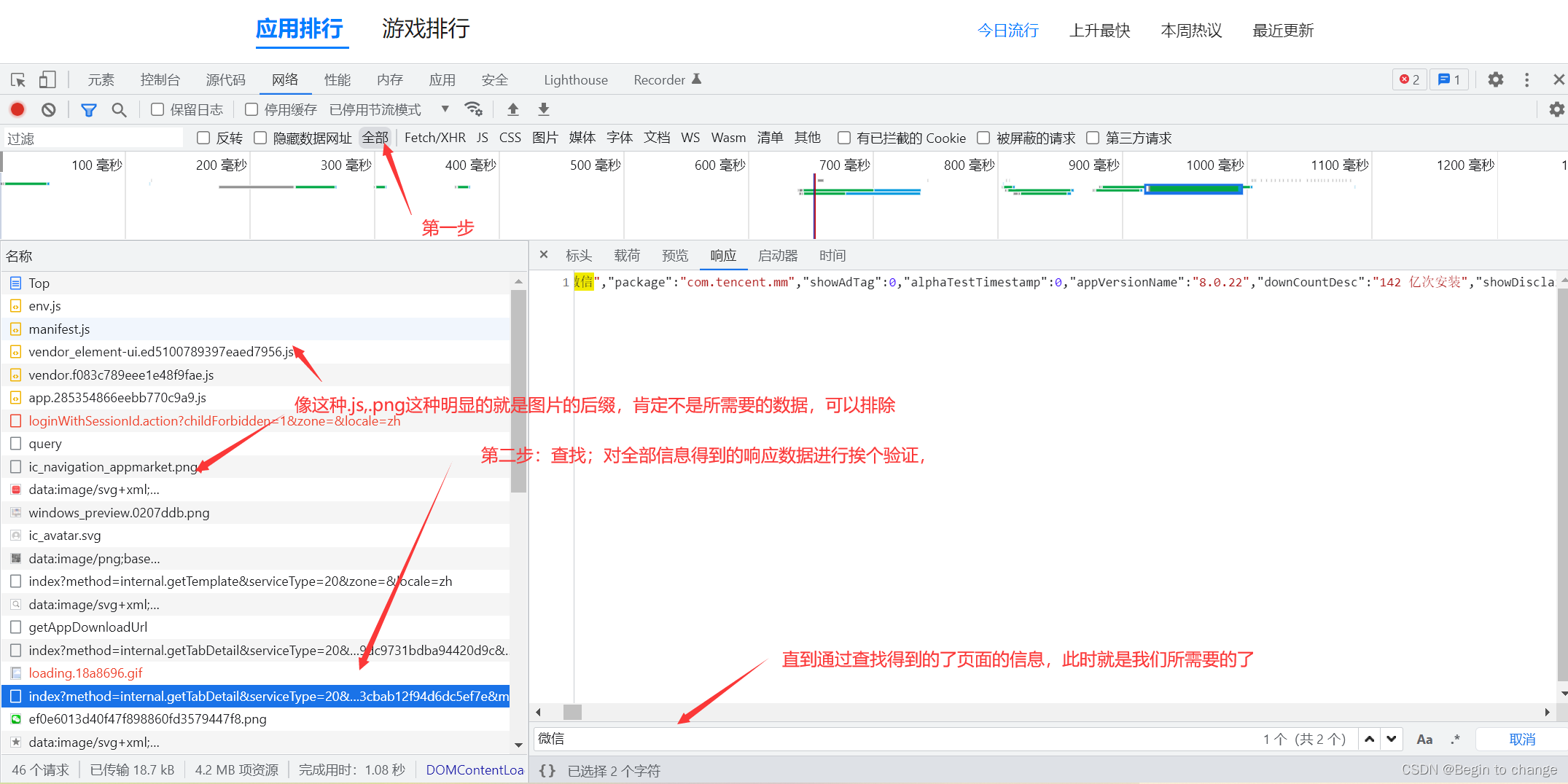
2、获取排行页面数据
①操作 

②源码
import requests
import json
if __name__ == '__main__':
url = 'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=1ca1964fe0c343cbab12f94d6dc5ef7e&maxResults=25&zone=&locale=zh'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'
}
'''
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app|C5683&shareTo=¤tUrl=https%3A%2F%2Fappstore.huawei.com%2Fapp%2FC5683&accessId=&appid=C5683&zone=&locale=zh
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app|C10652857&shareTo=¤tUrl=https%3A%2F%2Fappstore.huawei.com%2Fapp%2FC10652857&accessId=&appid=C10652857&zone=&locale=zh
'''
id_list = []
response = requests.get(url=url,headers=headers).json()
print(response)
③信息解析

3、详情页面分析
①寻找URL
重复上面的步骤去检查详情页的情况,找到所需要的数据,然后通过对比URL寻找规律,发现有一个编码是不一样的,而此编码保存在上一个页面的获取到的信息中(可以通过将获取到的数据保存到json文件中,然后通过快捷键去查找)


②验证URL
观察URL发现得到的区别是处在一大串的字符串中,也就是说无法将其分化出来;此时要进行的一个操作就是将区别后面的一长串字符串进行删除之后,然后将其拿到浏览器去验证跟删除前得到的页面是否一致;
通过验证发现是一样的,也就是说后面的数据是可有可无的,所以页面的URL就是基础的字符串拼接上ID

③获取URL
在知道了其结构之后,现在的需求就是获取ID的值了,而ID的值在排行页面获取到的数据中;
而排行页面获取到数据是字典的格式,所以接下来就是遍历字典,获得想要的值

④获取内容
得到URL之后,就按照爬取页面的四部曲去获得内容了,四部曲详情可以查看上篇文章
三、源码
# -*- coding: utf-8 -*-
import requests
import json
if __name__ == '__main__':
url = 'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&uri=1ca1964fe0c343cbab12f94d6dc5ef7e&maxResults=25&zone=&locale=zh'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'
}
params = {
'access-control-allow-credentials': 'true',
'access-control-allow-origin': 'https://appstore.huawei.com',
'Access-Control-Expose-Headers': 'session-valid',
'Cache-Control': 'no-store',
'Connection': 'keep-alive',
'content-encoding': 'gzip',
'Content-Type': 'application/json',
'Date': 'Thu, 19 May 2022 12:31:17 GMT',
'Pragma': 'no-cache',
'Server': 'elb',
'Transfer-Encoding': 'chunked',
'X-Content-Type-Options': 'nosniff',
'X-XSS-Protection': '1',
}
'''
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app|C5683&shareTo=¤tUrl=https%3A%2F%2Fappstore.huawei.com%2Fapp%2FC5683&accessId=&appid=C5683&zone=&locale=zh
https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app|C10652857&shareTo=¤tUrl=https%3A%2F%2Fappstore.huawei.com%2Fapp%2FC10652857&accessId=&appid=C10652857&zone=&locale=zh
'''
id_list = []
response = requests.get(url=url,params=params,headers=headers).json()
for dic in response['layoutData']:
for id in dic['dataList']:
id_list.append(id['appid'])
detail_url = 'https://web-drcn.hispace.dbankcloud.cn/uowap/index?method=internal.getTabDetail&serviceType=20&reqPageNum=1&maxResults=25&uri=app|'
all_content = []
for id in id_list:
url_new = detail_url + id
content = requests.get(url=url_new,headers=headers).json()
all_content.append(content)
fp = open('./content.json','w',encoding='utf-8')
json.dump(all_content,fp=fp,ensure_ascii=False)
print('over')
具体分析和思路详解见上篇博客
CSDN https://mp.csdn.net/mp_blog/creation/editor/124869764
https://mp.csdn.net/mp_blog/creation/editor/124869764