最近在学习transformer的知识,看了原论文,以及网上各式各样的材料,综合理解,之后写了这篇博客,这篇博客已经讲的非常非常细致了,因为我用了将近三天的时间,写完的,每一部分都尽可能的描述清楚。本博客只是论文中的模型框架展开分析,并没有对源码进行分析(这也是我下一步要做的),最后也会给出代码的实现。
Transformer和LSTM最大区别在于,LSTM的训练是迭代的,是一个接一个字的来,当前这个字过完LSTM单元后在可以进入下一个字,而transformer的训练是并行的,就是所有的字可以全部同时训练的,这样就大大加快了计算效率,transformer使用了位置嵌入positional embedding 来理解语言的顺序,使用自注意力机制和全连接层来进行计算。
本篇论文可以点击这里下载。这篇论文是Google于2017年在NIPS上发表的一篇文献,现在用Attention处理序列问题的论文层出不穷,本文的创新点在于抛弃了之前传统的Encoder-Decoder模型必须结合CNN或者RNN的固有模式,只用attention即可,正所谓大道至简。本文的主要目的是减少计算量和提高并行效率的同时,不损害模型效果。(之我见:其实就是摒弃了RNN(无法并行)和CNN(内存占用大,计算量大,参数多)各自的缺点,结合了RNN(保留长距离信息)和CNN(可以并行)各自的优点)。 本文提出了两个新的Attention机制,分别叫做Scaled Dot-Product Attention 和Multi-Head Attention。
目前主流的处理序列问题(如机器翻译、文档摘要,对话系统,QA等)大部分都是基于Encoder-Decoder框架(如seq2seq)。即:Encoder:from word sequence to sentence representation;Decoder: from sentence representation to word sequence distribution.传统的Encoder-Decoder一般使用RNN,大部分的神经机器翻译模型都选择使用RNN,但是正如我们所知道的,RNN难以处理长序列的句子,无法实现并行化(由于RNN处理序列的模式),并且面临对齐的问题。
之后这类模型的发展大多熊三个方面着手:
但是依旧存在一些潜在问题的制约,神经网络需要能够将源语句中所有必要信息压缩成固定长度的向量。这可能是的神经网路难以应付长时间(即长距离)的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
后来CNN被引入到seq2seq模型中,CNN不能直接用于处理变长的序列样本但是可以实现并行化。完全基于CNN的Seq2seq模型虽然可以并行实现,但是非常占内存,很多的参数,大数据量上对参数进行调整也是不容易的。
Encoder-Decoder模型的主要缺点就是,无论输入如何变化,Encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本的时候,每个词语所用到的语义向量都是一样的,这显然是过于简单的。为了解决上面提到的问题,一种可行的方案是引入attention mechanism。
深度学习里的Attention Model其实模拟的是人脑注意力模型,举个例子来说,
当我们观赏一幅画的时候,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,
其实眼睛聚焦只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,
也就是说这个时候人脑对整幅画的关注并不是均衡的,是有一定的权重区分的。
这就是深度学习里的Attention Model的核心思想。
所谓注意力就是说,在生成每个词的时候,对不同的输入词给予不同的关注权重。
将注意力加入到Encoder-Decoder中,Encoder不再生成一个固定大小的向量,
而是一个向量序列,并自适应地去选择这些向量的一个子集。
例如,where are you---->你在哪?我们正在翻译“你”的时候,
会给‘you’更多的权重,那么就可以有效解决对齐的问题。
这篇论文首先将注意力机制运用在NLP上,提出了Soft Attention Model,并将其应用到了机器翻译上面。其实,所谓的Soft Attention,是Softmax Attention,意思是在求注意力分配概率分布的时候使用的是softmax函数,对于输入句子中的每一个单词都给出一个概率,是个概率分布。加入注意力机制的模型表现确实更好,但是也存在一定的问题,比如,attention mechanism通常和RNN结合使用,我们都知道RNN依赖于t-1的历史信息来计算t时刻的信息,因此不能并行实现,计算效率比较低,特别是训练样本非常大的时候。
基于CNN的Seq2Seq+attention的优点:基于CNN的Seq2Seq模型具有基于RNN的Seq2seq模型捕捉 long distance dependency的能力,此外,最大的优点是可以并行化实现,效率比基于RNN的seq2seq模型高。缺点是:计算量大,与观测序列X和输出序列Y的长度成正比,参数比较多。
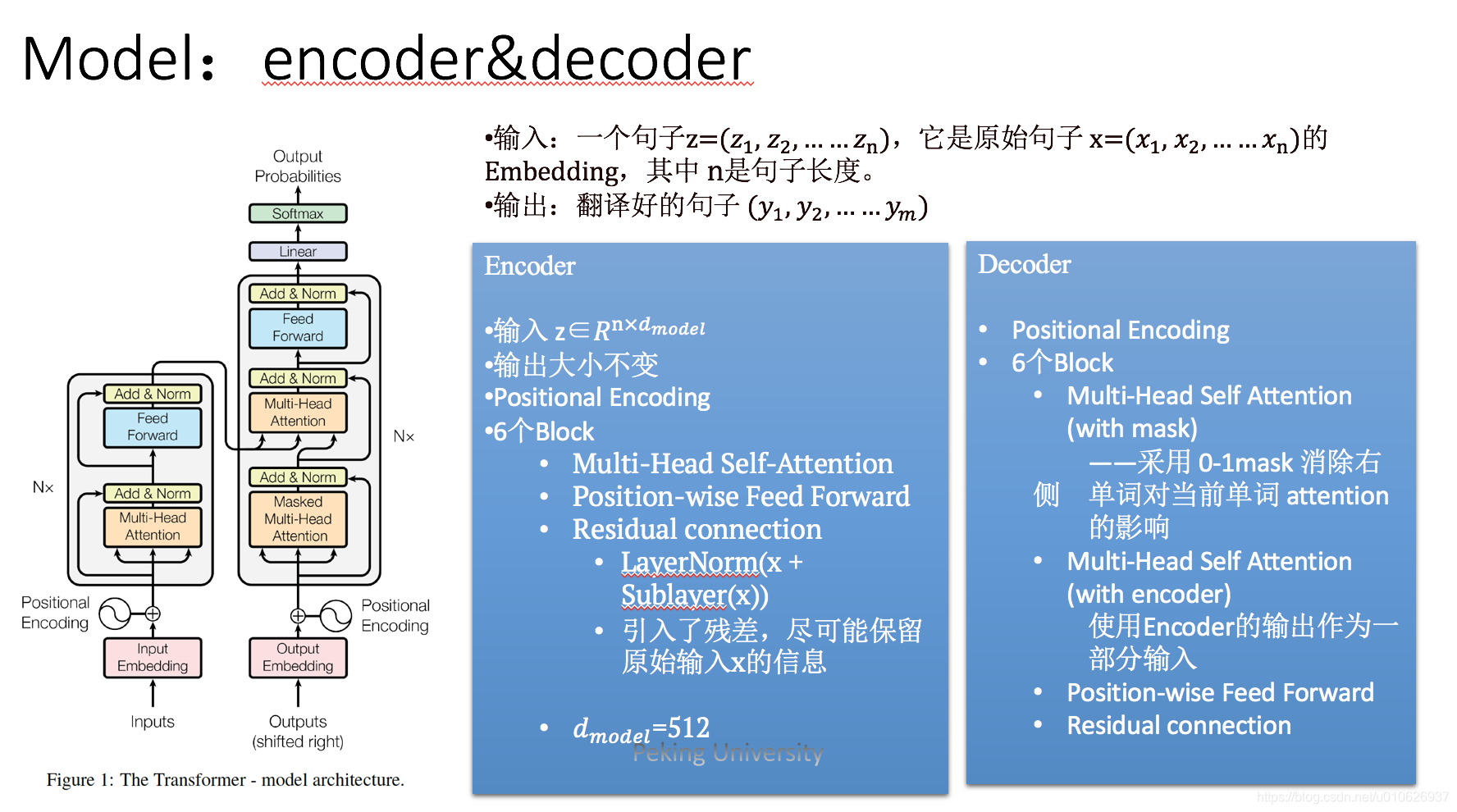
针对以上这两个问题,本文提出了Transformer模型,该模型也是一种Encoder-decoder的框架,只不过该模型完全不依赖于CNN和RNN;完全依赖于self-attention机制(一种堆叠式的self-attention)以及point-wise (逐点计算)的全连接层。
Encoder是由N=6个独立的层堆叠而成的,每个层有两个子层:
每个子层又引入了 residual connection,具体的做法为:每个子层的输出为这个子层的输入和输出相加:
x
+
S
u
b
l
a
y
e
r
(
x
)
x+Sublayer(x)
x+Sublayer(x),这就要求每个子层的输入与输出的维度是完全相等的,然后再使用layer normalization,作为最终的输出:
L
a
y
e
r
N
o
r
m
(
x
+
S
u
b
l
a
y
e
r
(
x
)
)
Layer Norm(x+Sublayer(x))
LayerNorm(x+Sublayer(x))
论文中限定了Embedding层的输出和两个子层的输入输出的维度都是
d
m
o
d
e
l
=
512
d_{model}=512
dmodel=512,即上图中的
e
m
b
e
d
d
i
n
g
d
i
m
e
n
s
i
o
n
embedding\ dimension
embedding dimension.
Normalization的作用是将数据归一化为均值位0,方差为1的数据。在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
经过Attention之后的输出维度和输入的嵌入表示维度,即
X
e
m
b
e
d
d
i
n
g
X_{embedding}
Xembedding,相同,也就是
[
b
a
t
c
h
s
i
z
e
,
s
e
q
u
e
n
c
e
l
e
n
g
t
h
,
e
m
b
e
d
d
i
n
g
d
i
m
e
n
s
i
o
n
]
[batch\ size,\ sequence\ length,\ embedding\ dimension]
[batch size, sequence length, embedding dimension],然后把它们加起来,做残差连接,直接进行元素相加,因为它们的维度是一致的。即,
X
+
S
u
b
L
a
y
e
r
(
X
)
=
X
e
m
b
e
d
d
i
n
g
+
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
(
此
处
的
A
t
t
e
n
t
i
o
n
为
后
面
将
要
提
到
的
M
u
l
t
i
−
H
e
a
d
A
t
t
e
n
t
i
o
n
)
X+SubLayer(X)=\\ X_{embedding}+Attention(Q,\ K,\ V)\\(此处的Attention为后面将要提到的Multi-Head Attention)
X+SubLayer(X)=Xembedding+Attention(Q, K, V)(此处的Attention为后面将要提到的Multi−HeadAttention)
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加(在此,运算即为Attention),从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层(这就是为啥要residual connection,也可以理解为residual connection的作用)residual connection。
L
a
y
e
r
N
o
r
m
a
l
i
z
a
t
i
o
n
Layer Normalization
LayerNormalization的作用就是把神经网络中隐藏层归一为标准正太分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用,同时也可以避免梯度消失和梯度爆炸的问题,相比Batch Normalization, Layer Normalization更适用于序列化模型比如RNN等,而Batch Normalization则更适用于CNN处理图像。
μ
i
=
1
m
∑
i
=
1
m
x
i
j
\mu_{i}=\frac{1}{m} \sum^{m}_ {i=1}x_{ij}
μi=m1i=1∑mxij
上式中以矩阵的行
(
r
o
w
)
(row)
(row)为单位求均值;
σ
j
2
=
1
m
∑
i
=
1
m
(
x
i
j
−
μ
j
)
2
\sigma^{2}_ {j} = \frac{1}{m} \sum^{m}_ {i=1}(x_{ij}-\mu_{j})^{2}
σj2=m1i=1∑m(xij−μj)2
上式中以矩阵的行
(
r
o
w
)
(row)
(row)为单位求方差;
L
a
y
e
r
N
o
r
m
(
x
)
=
α
⊙
x
i
j
−
μ
i
σ
i
2
+
ϵ
+
β
LayerNorm(x) = \alpha \odot \frac{x_{ij}-\mu_{i}}{\sqrt{\sigma^{2}_ {i}+\epsilon}} + \beta
LayerNorm(x)=α⊙σi2+ϵ
xij−μi+β
然后用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值,
ϵ
\epsilon
ϵ 是为了防止除
0
0
0;
之后引入两个可训练参数
α
,
β
\alpha,\beta
α,β 来弥补归一化的过程中损失掉的信息, 注意
⊙
\odot
⊙ 表示元素相乘而不是点积, 我们一般初始化
α
\alpha
α 为全
1
1
1, 而
β
\beta
β 为全
0
0
0.
其实,只要把Encoder每个子层都理解清楚了,Decoder的各个层就会很好理解。
Decoder也是由N=6个独立的层堆叠而成的,除了与Encoder层中的两个完全相同的子层外,在两层之间又加入了一个multi-head attention,这里是对Encoder的输出作attention处理。
与Encoder相同,每个子层之间也引入了residual connection,并且相加之后使用layer normalization得到每个子层的最后输出。
此外为了防止序列中元素的位置主导输出结果,对Decoder层的multi-head-attention层增加了mask操作,并且结合对output embedding结果进行右移一位的操作,保证了每个位置i的输出,只会依赖于i位之前(不包括i位,因为右移一位和mask)(加入了mask机制, masking 的作用就是防止在训练的时候 使用未来的输出的单词。 比如训练时,第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能基于比 i 小的输出)。
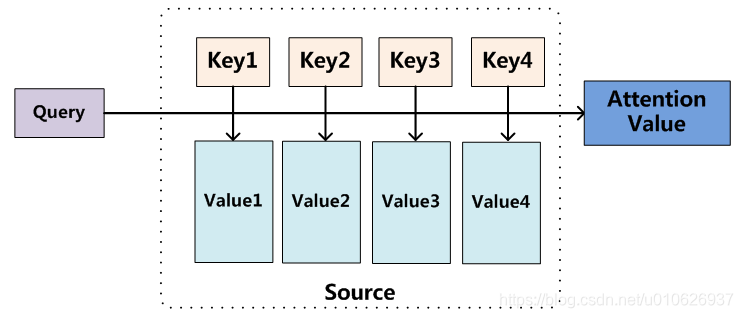
论文中将常用的Attention结构从新的一种角度进行了描述,Attention作为一种函数,接受的输入为:一个query,一组key-value pairs,三者都是向量;输出就是对组中所有values的加权之和,其中的权值是使 compatibility function(如内积),对组内的每一个keys和query计算得到的。
例如,对于常见的self-attention来说,这里就是指对序列中的某一个元素对应的向量,求得经过self-attention之后的对应的向量。query指的是这个元素对应的向量(例如NLP任务中句子序列中某一个单词对应的embedding向量),key-value Paris就是这个序列的所有元素,其中的每个元素对应的key和value是完全相同的向量,对于要比较的那个元素,与query也是完全相同的。然后使用当前向量和所有向量做内积得到权值,最后的数据就是这个权值和对应向量的加权和。
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
Self Attention 指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
在本文中使用了两种Attention方法,分别为Scaled Dot-Product Attention和Multi-Head Attention。
整个模型框架如下所示:
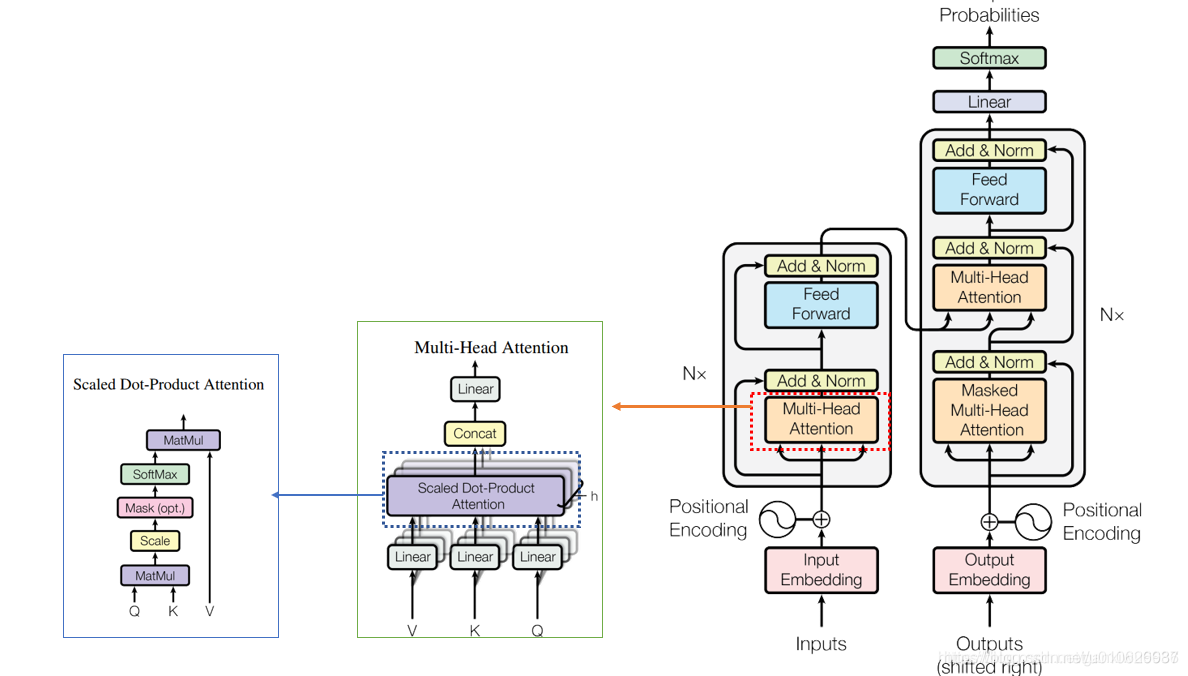
我们假设query和key这两个用来比较的向量,长度都为
d
k
d_{k}
dk;value向量的长度为
d
v
d_{v}
dv。对query和所有的key进行点积得到值,再对这个点积结果除以
d
k
\sqrt{d_{k}}
dk
,完成scale,最后应用一个softmax function获得每个value对应的权重(也就说这也是一种soft attention),加权求和求得最后的输出向量。
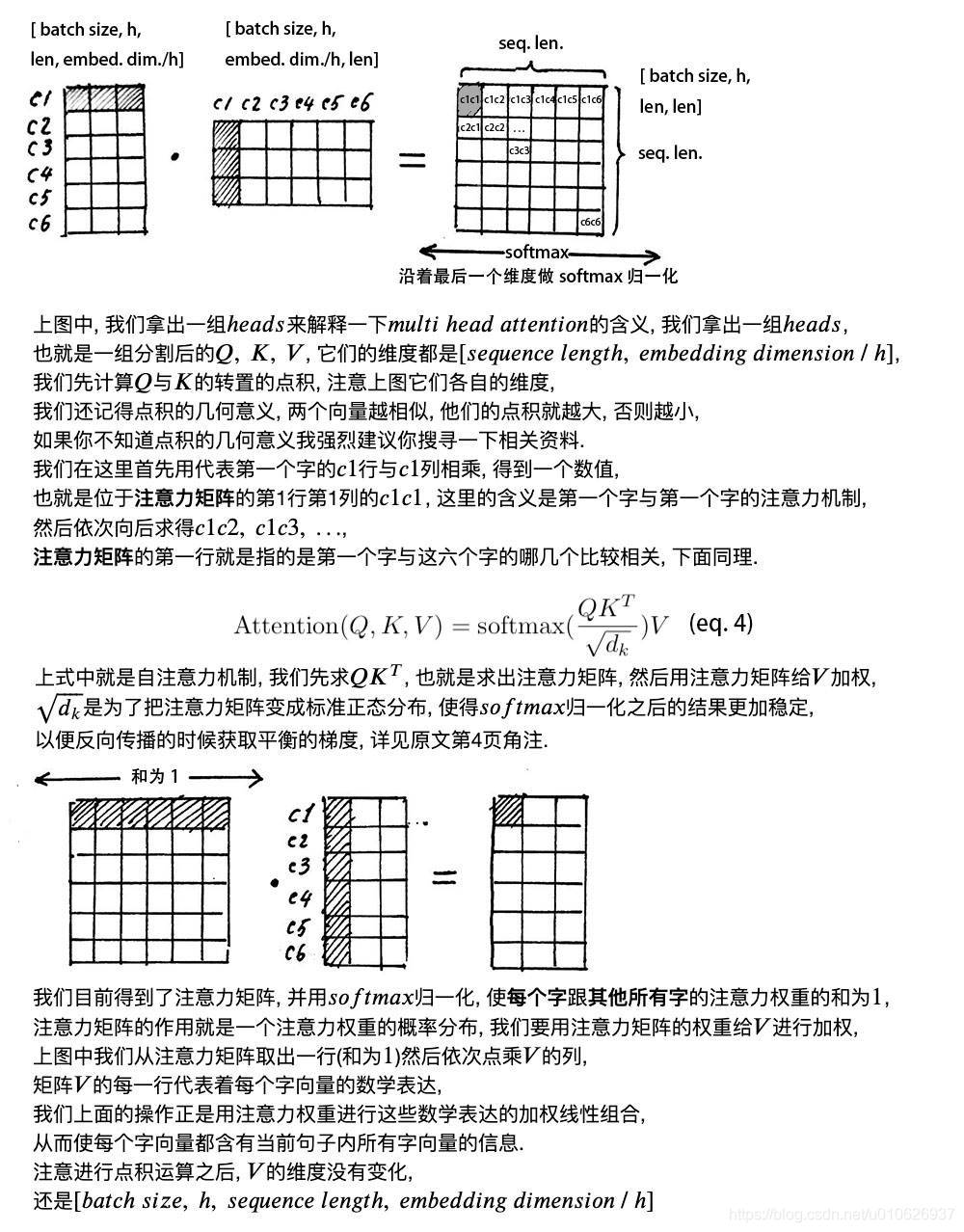
这是对于一个query的情况,实际中是直接对一个血猎对应的所有querys直接进行计算,将所有querys拼成一个大的Q矩阵,对应的keys和values也拼接成K和V矩阵,则Scaled Dot-Product Attention对应的计算公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V
Attention(Q,K,V)=softmax(dk
QKT)V
需要注意的是:
d
k
d_{k}
dk较大的时候,向量之间的点积结果可能就会非常大,这会造成softmax函数陷入到梯度很小的区域,不利于反向传播的进行,。为了适应这种情况,适应了缩放因子
d
k
\sqrt{d_{k}}
dk
,对点积结果进行尺度化,将点积结果尽量缩小到梯度敏感的区域内。
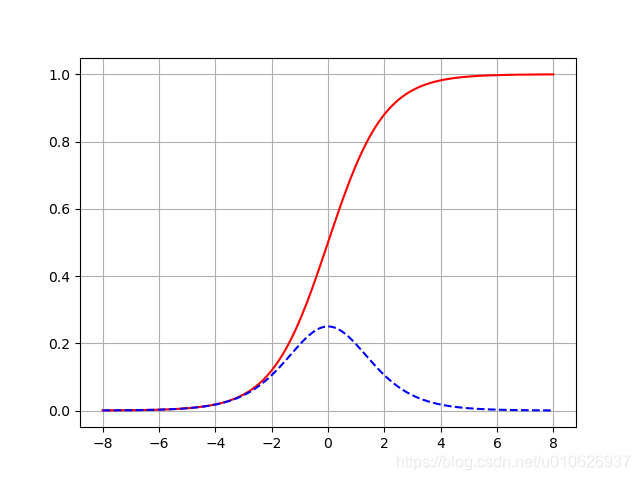
回顾一下sigmod函数的图像,当值大于4的时候,第一就开始变得比较小了。(softmax可以看作是sigmod多分类的一个扩展)
softmax函数的解释如下:
其他关于softmax的知识,可以参考这里或者这里或者直接百度一下。
为什么当
d
k
\sqrt{d_{k}}
dk
比较大的时候,会导致点积的结果比较大,原论文中是这样解释的:

之前的方法都是对 d m o d e l d_{model} dmodel维度的query,keys和value直接只用一个Attention函数。在Multi-Head Attention方法中,进行如此操作:
Transformer中三种multi-head Attention
至此,Attention部分已经完全讲完了,下面给出一个直观的解释,帮助理解。
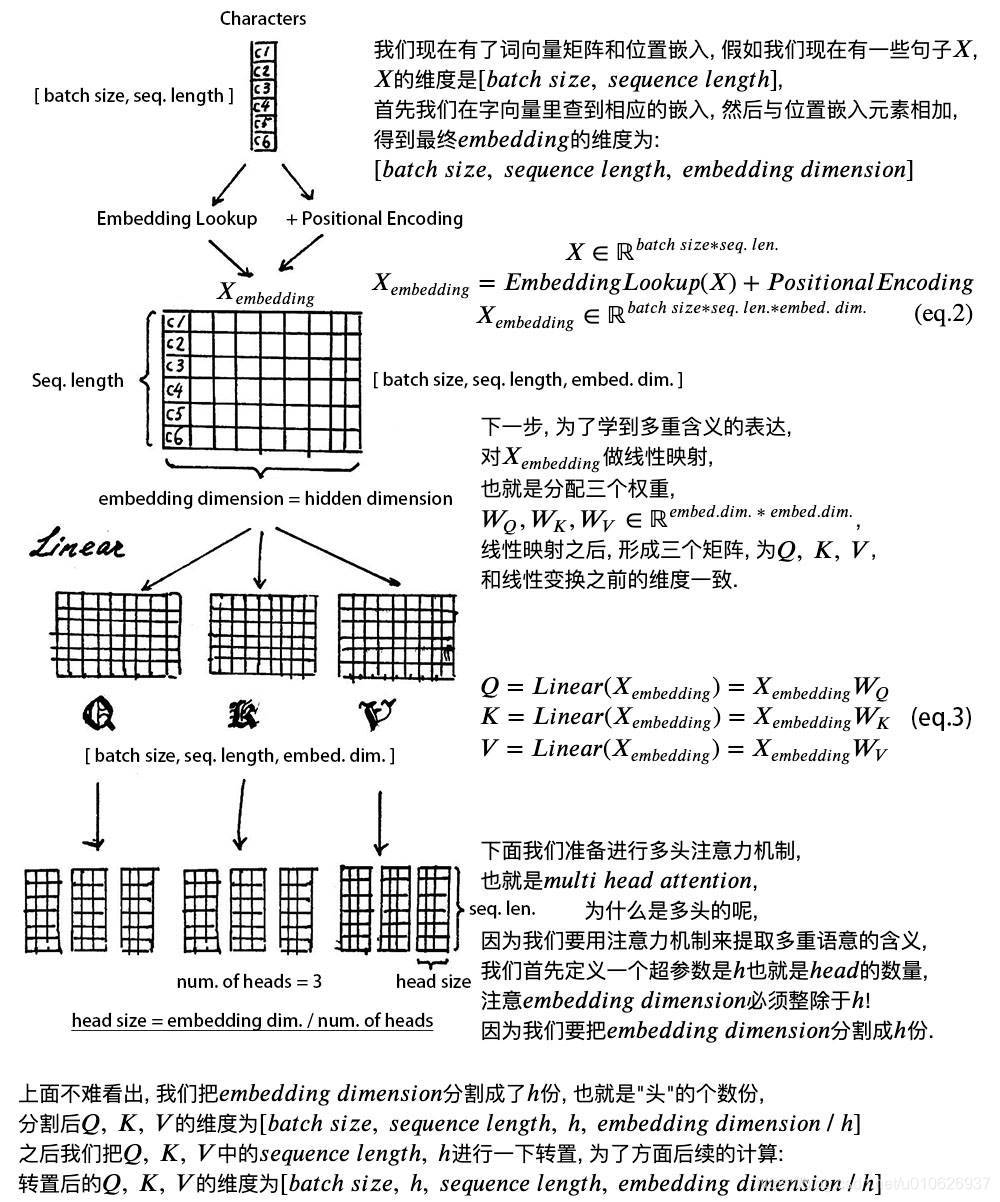
至此, 我们已经基本了解到
t
r
a
n
s
f
o
r
m
e
r
transformer
transformer编码器的主要构成部分, 我们下面用公式把一个
t
r
a
n
s
f
o
r
m
e
r
b
l
o
c
k
transformer\ \ block
transformer block的计算过程整理一下:
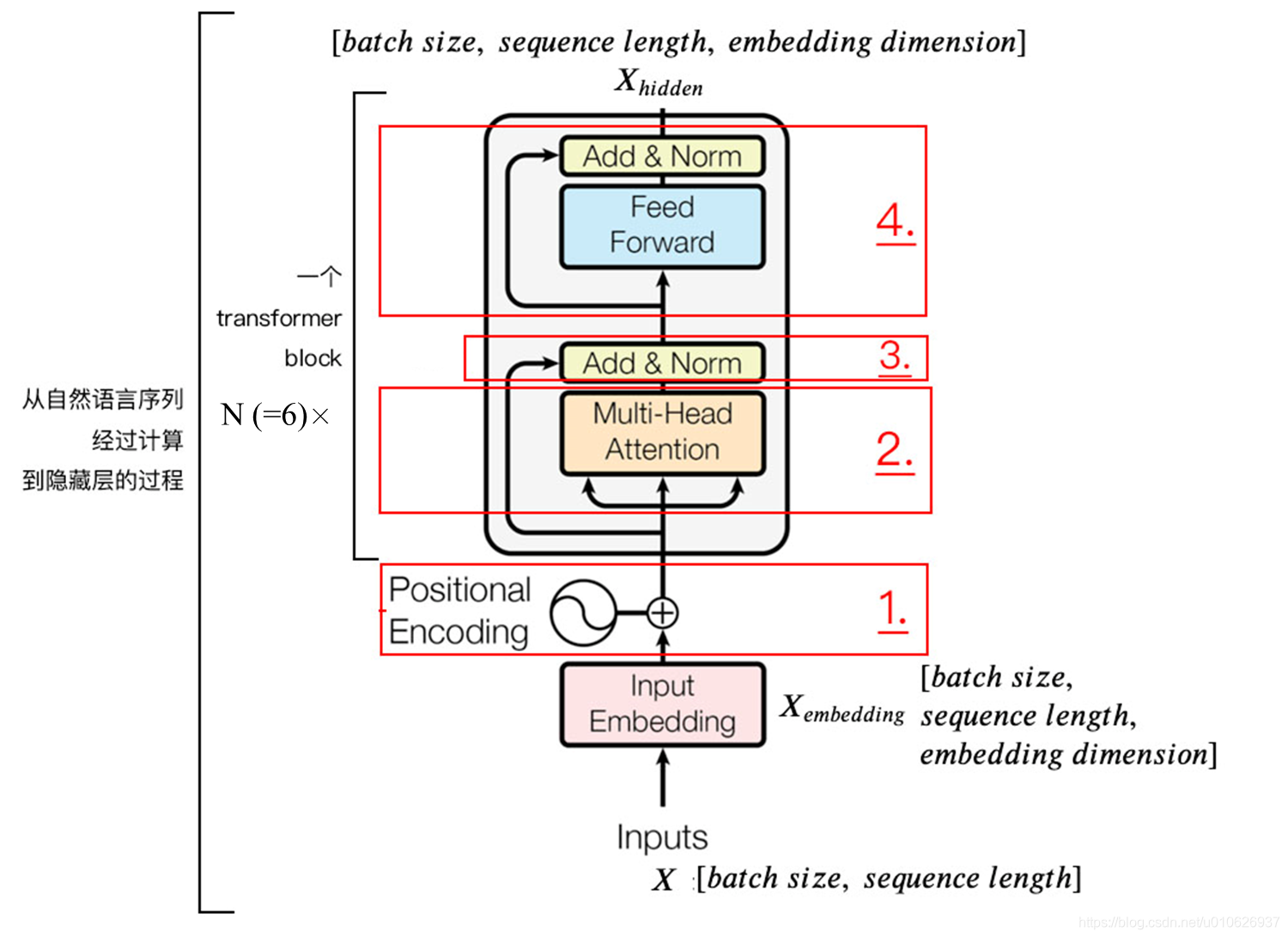
1). 字向量与位置编码:
X
=
E
m
b
e
d
d
i
n
g
L
o
o
k
u
p
(
X
)
+
P
o
s
i
t
i
o
n
a
l
E
n
c
o
d
i
n
g
X
i
n
R
b
a
t
c
h
s
i
z
e
∗
s
e
q
l
e
n
∗
e
m
b
e
d
d
i
m
.
X = EmbeddingLookup(X) + Positional\ Encoding\\ X\ in\ \mathbb{R}^{ batch\ size* seq\ len* embed\ dim.}
X=EmbeddingLookup(X)+Positional EncodingX in Rbatch size∗seq len∗embed dim.
2). 自注意力机制:
其实在Encoder中,
Q
=
K
=
V
=
X
Q=K=V=X
Q=K=V=X那么对
Q
,
K
,
V
Q,K,V
Q,K,V进行线性映射后的
Q
,
K
,
V
Q,K,V
Q,K,V可以写成如下:
Q
=
L
i
n
e
a
r
(
X
)
=
X
W
Q
K
=
L
i
n
e
a
r
(
X
)
=
X
W
K
V
=
L
i
n
e
a
r
(
X
)
=
X
W
V
Q = Linear(X) = XW^{Q}\\ K = Linear(X) = XW^{K}\\ V = Linear(X) = XW^{V}
Q=Linear(X)=XWQK=Linear(X)=XWKV=Linear(X)=XWV
然后对线性映射后的
Q
,
K
,
V
Q,K,V
Q,K,V进行Attention:
X
a
t
t
e
n
t
i
o
n
=
M
u
l
t
i
.
H
e
a
d
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
X_{attention} = Multi.Head\ Attention(Q, K, V)
Xattention=Multi.Head Attention(Q,K,V)
3). 残差连接与
L
a
y
e
r
N
o
r
m
a
l
i
z
a
t
i
o
n
Layer\ Normalization
Layer Normalization
X
a
t
t
e
n
t
i
o
n
=
X
+
X
a
t
t
e
n
t
i
o
n
X
a
t
t
e
n
t
i
o
n
=
L
a
y
e
r
N
o
r
m
(
X
a
t
t
e
n
t
i
o
n
)
X_{attention} = X + X_{attention}\\ X_{attention} = LayerNorm(X_{attention})
Xattention=X+XattentionXattention=LayerNorm(Xattention)
4). 下面进行
F
e
e
d
F
o
r
w
a
r
d
Feed\ Forward
Feed Forward, 其实就是两层线性映射并用激活函数激活, 比如说
R
e
L
U
ReLU
ReLU:
X
h
i
d
d
e
n
=
A
c
t
i
v
a
t
e
(
L
i
n
e
a
r
(
L
i
n
e
a
r
(
X
a
t
t
e
n
t
i
o
n
)
)
)
即
:
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
X_{hidden} = Activate(Linear(Linear(X_{attention}))) \\ 即:FFN(x)=max(0,xW_{1}+b_{1})W_{2}+b_{2}
Xhidden=Activate(Linear(Linear(Xattention)))即:FFN(x)=max(0,xW1+b1)W2+b2
5). 重复 3)残差连接与
L
a
y
e
r
N
o
r
m
a
l
i
z
a
t
i
o
n
Layer Normalization
LayerNormalization:
令:
X
h
i
d
d
e
n
=
X
a
t
t
e
n
t
i
o
n
+
X
h
i
d
d
e
n
X
h
i
d
d
e
n
=
L
a
y
e
r
N
o
r
m
(
X
h
i
d
d
e
n
)
X
h
i
d
d
e
n
i
n
R
b
a
t
c
h
.
s
i
z
e
∗
s
e
q
.
l
e
n
∗
.
e
m
b
e
d
.
d
i
m
.
X_{hidden} = X_{attention} + X_{hidden}\\ X_{hidden} = LayerNorm(X_{hidden})\\ X_{hidden}\ \ in\ \mathbb{R} ^ { batch.size* seq. len*. embed. dim.}
Xhidden=Xattention+XhiddenXhidden=LayerNorm(Xhidden)Xhidden in Rbatch.size∗seq.len∗.embed.dim.
在完整的Encoder中,上述步骤的2)~5)要堆叠式的重复6次。
Encoder 和Decoder都包含了一个fully connected feed-forward network,特殊的是,这个网络分别对每个位置的attention层的输出向量单独地进行作用,整个过程包括了两次线性变换以及一次ReLU激活。
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0,xW_{1}+b_{1})W_{2}+b_{2}
FFN(x)=max(0,xW1+b1)W2+b2
对于不同位置的线性变换是完全一样的,即使使用相同的参数。这一层的输入输出都是
d
m
o
d
e
l
=
512
d_{model}=512
dmodel=512,中间隐层的维度为
d
f
f
=
2048
d_{ff}=2048
dff=2048。
用了两层Dense层,第二层的activation用的是Relu。可以看成是两层的1*1的1d-convolution。hidden_size变化为:
512
−
>
2048
−
>
512
512->2048->512
512−>2048−>512。
Position-wise feed forward network,其实就是一个MLP 网络,子层的输出中每个
d
m
o
d
e
l
d_{model}
dmodel 维向量 x 在此先由
x
W
1
+
b
1
xW_1+b_1
xW1+b1 变为
d
f
f
d_{ff}
dff维的
x
′
x'
x′,再经过
m
a
x
(
0
,
x
′
)
W
2
+
b
2
max(0,x')W_2+b_2
max(0,x′)W2+b2 回归
d
m
o
d
e
l
d_{model}
dmodel 维。之后再是一个residual connection。输出 size 仍是
[
s
e
q
u
e
n
c
e
l
e
n
g
t
h
,
d
m
o
d
e
l
]
[sequence\ length, d_{model}]
[sequence length,dmodel]
使用已经训练好的embeddings将input token和output token转换成
d
m
o
d
e
l
d_{model}
dmodel维度的向量。在最后Decoder的输出时,将Decoder的输出通过一个线性变换层和一个softmax层,转换成预测下一个token的概率向量,这两个层中参数也是提前训练好的。
在transformer模型中,两个embedding layers以及最后的softmax之前的线性变换,这三者共享使用相同的矩阵权值。对于embedding层,里面的权值需要乘以
d
m
o
d
e
l
\sqrt{d_{model}}
dmodel
之后再使用。
因为模型完全没有使用RNN和CNN,而又想使用序列中的顺序信息,就必须加入一些关于token的相对位置和绝对位置的信息。因此我们加入了Positional Encoding,作为Encoder和Decoder的输入。需要注意的是Positional Encoding产生的每个向量维度为 d m o d e l d_{model} dmodel,与原本的embedding向量维度相同,从而两者可以被相加使用。
实际上,Position Encoding的大小为 [ m a x s e q u e n c e l e n g t h , e m b e d d i n g d i m e n s i o n ] [max\ sequence\ length, embedding\ dimension] [max sequence length,embedding dimension],嵌入的维度同词向量的维度,即等于 d m o d e l = 512 d_{model}=512 dmodel=512, m a x s e q u e n c e l e n g t h max\ sequence\ length max sequence length属于超参数,指的是限定的最大单个句长。
对位置进行embedding的方法有很多,有训练方法和指定方法。在本文中,采用频率不同的sin函数和cos函数。
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
d
m
o
d
e
l
)
PE_{(pos,2i)}=sin(pos/10000^{\frac{2i}{d_{model}}})\\ PE_{(pos,2i+1)}=cos(pos/10000^{\frac{2i}{d_{model}}})
PE(pos,2i)=sin(pos/10000dmodel2i)PE(pos,2i+1)=cos(pos/10000dmodel2i)
上述表达式中,pos指的是句中字(或词)的位置,取值范围是
[
0
,
m
a
x
s
e
q
u
e
n
c
e
l
e
n
g
t
h
)
[0, max\ sequence\ length)
[0,max sequence length)(注意左闭右开),i指的是维度向量的第i维,取值范围是
[
0
,
e
m
b
e
d
d
i
n
g
d
i
m
e
n
s
t
i
o
n
)
[0, embedding\ dimenstion)
[0,embedding dimenstion),上面有
s
i
n
sin
sin和
c
o
s
cos
cos一组公式,对应着embedding dimension上的一组奇数和偶数的序号的维度。例如,当i=0的时候
2
i
=
0
,
2
i
+
1
=
1
2i=0,2i+1=1
2i=0,2i+1=1,那么久对应着
(
0
,
1
)
(0,1)
(0,1)这组维度,对于偶数维用
s
i
n
sin
sin函数,奇数维用
c
o
s
cos
cos函数,也就是说,第0维用
s
i
n
sin
sin函数,第1维用
c
o
s
cos
cos函数,从而产生不同的周期性变化。那么可知
i
<
=
d
m
o
d
e
l
/
2
i<=d_{model}/2
i<=dmodel/2。如下图所示:
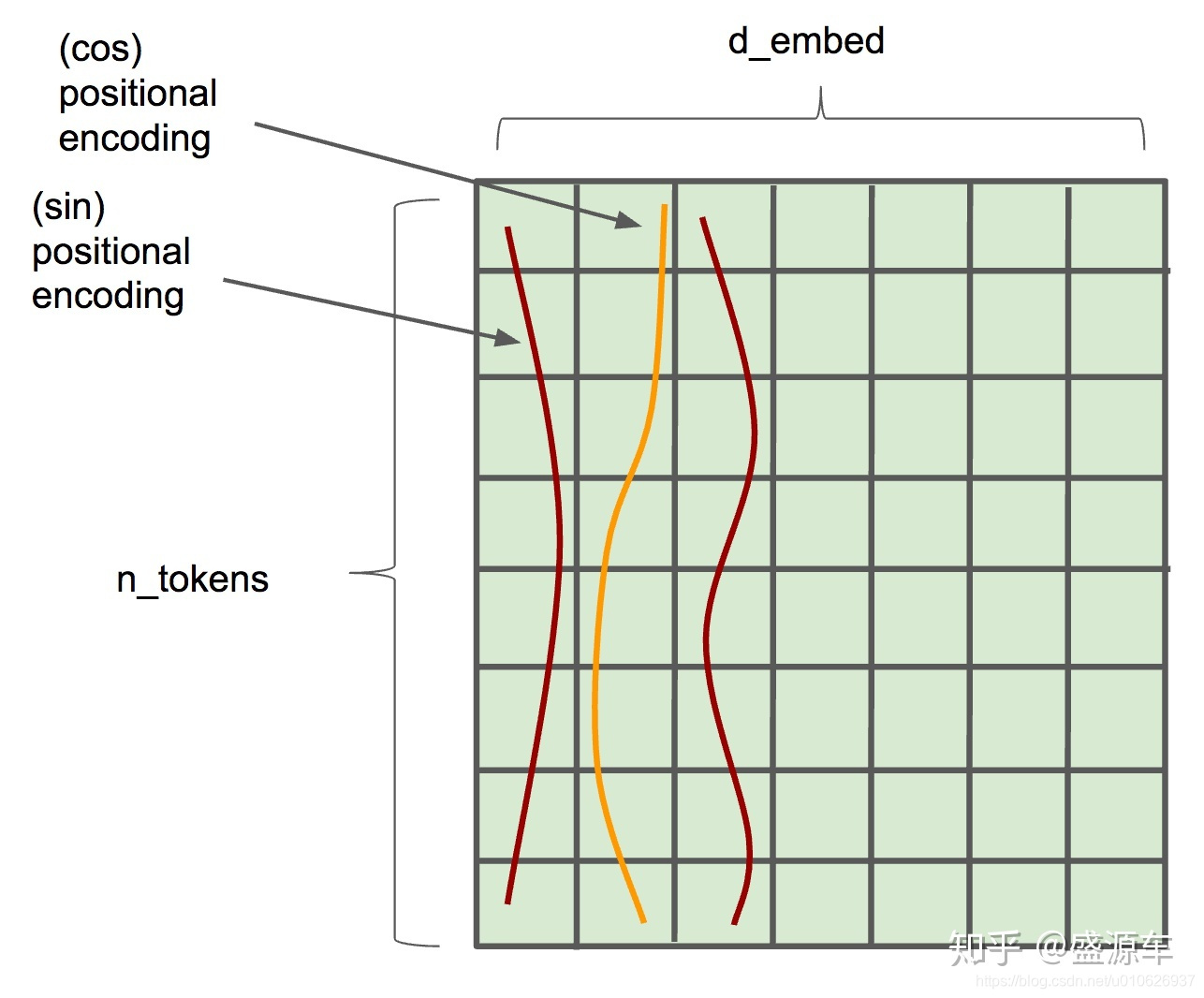
位置嵌入在 embedding dimension维度上随着维度序号的增大,周期会越来越大(从
2
π
2 \pi
2π到
2
π
∗
10000
2\pi*10000
2π∗10000),从而产生一种包含位置信息的纹理。而每一个位置在embedding dimension维度上都会得到不同周期的
s
i
n
sin
sin和
c
o
s
cos
cos函数的取值组合,从而产生独一的纹理位置信息,模型从而学到位置之间的依赖关系(函数图像是连续的)和自然语言的时序特性(周期内不同时刻对应于函数图像上不同的位置)。
Position Embedding本身是一个绝对位置信息,由于sin函数和cos函数的特性:
S
i
n
(
α
+
β
)
=
s
i
n
α
c
o
s
β
+
c
o
s
α
s
i
n
β
C
o
s
(
α
+
β
)
=
c
o
s
α
c
o
s
β
−
s
i
n
α
s
i
n
β
Sin(\alpha+\beta)=sin\alpha cos\beta +cos\alpha sin\beta\\ Cos(\alpha+\beta)=cos\alpha cos\beta -sin\alpha sin\beta
Sin(α+β)=sinαcosβ+cosαsinβCos(α+β)=cosαcosβ−sinαsinβ
这表明
P
E
p
o
s
+
k
PE_{pos+k}
PEpos+k可以表示为
P
E
p
o
s
PE_{pos}
PEpos的线性函数。
自注意力机制在论文「A structured Self-Attentive Sentence Embedding」中被首次提出。之所以使用Self-Attention而没有使用循环或者卷积的结构,主要出于以下三点的考虑:


以上是关于Transformer整个框架的分析,为了后续代码的理解,我们再解释一下,训练模型的时候所采用的Optimizer和Regularization。
Transformer使用Adam optimizer with
β
1
=
0.9
,
β
2
=
0.98
,
ϵ
=
1
0
−
9
\beta_{1}=0.9,\ \beta_{2}=0.98,\ \epsilon=10^{-9}
β1=0.9, β2=0.98, ϵ=10−9,学习率根据下面的计算公式进行变动,现有一个预热,学习率会呈线性增长,然后呈幂函数递减,类似于下图所示。。
l
r
a
t
e
=
d
m
o
d
e
l
−
0.5
∗
m
i
n
(
s
t
e
p
_
n
u
m
−
0.5
,
s
t
e
p
_
n
u
m
∗
w
a
r
m
u
p
s
t
e
p
s
−
1.5
)
lrate=d_{model}^{-0.5}*min(step\_num^{-0.5},step\_num\ *warmup_steps^{-1.5})
lrate=dmodel−0.5∗min(step_num−0.5,step_num ∗warmupsteps−1.5)

论文中设置warmup_steps=4000,也就是说训练的前4000步线性增长,4000步后面成幂函数递减。这么做可以加速模型训练收敛,先以上升的较大的学习率让模型快速落入一个局部收敛较优的状态,然后以较小的学习率微调参数慢慢逼近更优的状态以避免震荡。
论文中主要使用了两种正则化手段来避免过拟合并加速训练过程。
在每一residual Multi-Head Attention之后, Add & Norm之前进行dropout,以及add(token embedding, positional encoding)之后进行dropout,FFN中没有dropout,base model的dropout rate统一设置为0.1,big model在wmt14 en-fr数据集上设置为0.1, 在en-de数据集上设置为0.3.
Label Smothing Regularization(LSR)是2015年发表在CoRR的paper:Rethinking the inception architecture for computer vision中的一个idea,这个idea简单又实用。假设数据样本x的针对label条件概率的真实分布为:
q
(
k
∣
x
)
=
δ
k
,
y
=
{
1
,
k
=
y
0
,
k
≠
y
q(k|x)=\delta_{k,y}=\left\{ \begin{aligned} 1, k = y\\ 0, k \neq y \end{aligned} \right.
q(k∣x)=δk,y={1,k=y0,k=y
这使得模型对自己给出的预测太过自信,容易导致过拟合并且自适应能力差(easy cause overfit and hard to adapt)。解决方案是:给label分布加入平滑分布
u
(
k
)
u(k)
u(k),一般取平均分布
u
(
k
)
=
1
k
u(k)=\frac{1}{k}
u(k)=k1就可以,于是得到:
q
′
(
k
∣
x
)
=
(
1
−
ϵ
)
δ
k
,
y
+
ϵ
u
(
k
)
q'(k|x)=(1-\epsilon)\delta_{k,y}+\epsilon u(k)
q′(k∣x)=(1−ϵ)δk,y+ϵu(k)
映射到损失函数 cross entropy有:
H
(
q
′
,
p
)
=
−
∑
k
=
1
K
log
p
(
k
)
q
′
(
k
)
=
(
1
−
ϵ
)
H
(
q
,
p
)
+
ϵ
H
(
u
,
p
)
\begin{aligned} H(q',p)&=-\sum_{k=1}^{K}\log^{p(k)}q'(k)\\ &=(1-\epsilon)H(q,p)+\epsilon H(u,p) \end{aligned}
H(q′,p)=−k=1∑Klogp(k)q′(k)=(1−ϵ)H(q,p)+ϵH(u,p)
由上式可以知道,LSR使得不仅要最小化原来的交叉熵
H
(
q
,
p
)
H(q,p)
H(q,p),还要考虑预测分布p与
u
(
k
)
u(k)
u(k)之间差异最小化,使得模型预测泛化能力更好。transformer的论文指定
ϵ
l
s
=
0.1
\epsilon_{ls}=0.1
ϵls=0.1。
下表是使用LSR和未使用LSR在tensorflow datasets的ted_hrlr_translate/pt_to_en dataset上bleu score对比
| bleu on validation dataset | bleu on test dataset | |
|---|---|---|
| beam_search | 41.5 | 42.0 |
| beam_search + label_smooth_regualrization | 47.3 | 46.8 |
可以看到使用了LSR在验证集和测试集上都取得了比更好的bleu score.但是LSR对perplexity不利,因为模型的学习目标变得更不确切了。
[阅读笔记]《Attention is All You Need》
本文相当一部分的内容来自于词。
-《Attention is All You Need》论文翻译
本文算是对原论文的一个翻译,帮助阅读论文。
-深度学习中的“注意力机制”
本文也算是对原论文一个翻译,用来辅助读原论文。
-Transformer 详解
本文有一部内容也参考此处。