SpringBoot复习
基础部分
1)SpringBoot中配置文件使用
- 配置文件间的加载优先级 properties(最高)> yml > yaml(最低)
2)yaml数据读取
对于yaml文件中的数据,其实你就可以想象成这就是一个小型的数据库,里面保存有若干数据,每个数据都有一个独立的名字,如果你想读取里面的数据,肯定是支持的,下面就介绍3种读取数据的方式
读取全部数据
读取单一数据可以解决读取数据的问题,但是如果定义的数据量过大,这么一个一个书写肯定会累死人的,SpringBoot提供了一个对象,能够把所有的数据都封装到这一个对象中,这个对象叫做Environment,使用自动装配注解可以将所有的yaml数据封装到这个对象中

数据封装到了Environment对象中,获取属性时,通过Environment的接口操作进行,具体方法时getProperties(String),参数填写属性名即可
总结
- 使用Environment对象封装全部配置信息
- 使用@Autowired自动装配数据到Environment对象中
读取对象数据
单一数据读取书写比较繁琐,全数据封装又封装的太厉害了,每次拿数据还要一个一个的getProperties(),总之用起来都不是很舒服。由于Java是一个面向对象的语言,很多情况下,我们会将一组数据封装成一个对象。SpringBoot也提供了可以将一组yaml对象数据封装一个Java对象的操作
首先定义一个对象,并将该对象纳入Spring管控的范围,也就是定义成一个bean,然后使用注解@ConfigurationProperties指定该对象加载哪一组yaml中配置的信息。

这个**@ConfigurationProperties必须告诉他加载的数据前缀是什么**,这样当前前缀下的所有属性就封装到这个对象中。记得数据属性名要与对象的变量名一一对应啊,不然没法封装。其实以后如果你要定义一组数据自己使用,就可以先写一个对象,然后定义好属性,下面到配置中根据这个格式书写即可。

温馨提示
细心的小伙伴会发现一个问题,自定义的这种数据在yaml文件中书写时没有弹出提示,是这样的,咱们到原理篇再揭秘如何弹出提示。
总结
- 使用**@ConfigurationProperties**注解绑定配置信息到封装类中
- 封装类需要定义为Spring管理的bean,否则无法进行属性注入
yaml文件中的数据引用
如果你在书写yaml数据时,经常出现如下现象,比如很多个文件都具有相同的目录前缀
center:
dataDir: /usr/local/fire/data
tmpDir: /usr/local/fire/tmp
logDir: /usr/local/fire/log
msgDir: /usr/local/fire/msgDir
或者
center:
dataDir: D:/usr/local/fire/data
tmpDir: D:/usr/local/fire/tmp
logDir: D:/usr/local/fire/log
msgDir: D:/usr/local/fire/msgDir
这个时候你可以使用引用格式来定义数据,其实就是搞了个变量名,然后引用变量了,格式如下:
baseDir: /usr/local/fire
center:
dataDir: ${baseDir}/data
tmpDir: ${baseDir}/tmp
logDir: ${baseDir}/log
msgDir: ${baseDir}/msgDir
还有一个注意事项,在书写字符串时,如果需要使用转义字符,需要将数据字符串使用双引号包裹起来
lesson: "Spring\tboot\nlesson"
总结
- 在配置文件中可以使用${属性名}方式引用属性值
- 如果属性中出现特殊字符,可以使用双引号包裹起来作为字符解析
3)整合JUnitd的小问题
当我们的测试类不在引导类(启动类)下面时,就会出现错误,导致错误的原因就是找不到@SpringConfiguration即Spring的配置类。解决方法有三种:
- 将你的测试类路径放在引导类包路径下方(首推)
- 加上@SpringBootTest注解中的classes属性,属性值对应引导类的Class对象
- 测试类加注解@ContextConfiguration注解,classes属性值仍然是对应的引导类Class对象
SpringBoot找相应配置类时也是根据包路径进行依次查找。
方式一:

方式二:
@SpringBootTest(classes = Springboot04JunitApplication.class)
class Springboot04JunitApplicationTests {
//注入你要测试的对象
@Autowired
private BookDao bookDao;
@Test
void contextLoads() {
//执行要测试的对象对应的方法
bookDao.save();
System.out.println("two...");
}
}
方式三:
@SpringBootTest
@ContextConfiguration(classes = Springboot04JunitApplication.class)
class Springboot04JunitApplicationTests {
//注入你要测试的对象
@Autowired
private BookDao bookDao;
@Test
void contextLoads() {
//执行要测试的对象对应的方法
bookDao.save();
System.out.println("two...");
}
}
总结
- 导入测试对应的starter
- 测试类使用@SpringBootTest修饰
- 使用自动装配的形式添加要测试的对象
- 测试类如果存在于引导类所在包或子包中无需指定引导类
- 测试类如果不存在于引导类所在的包或子包中需要通过classes属性指定引导类
4)整合Druid
此时虽然没有指定数据源,但是根据SpringBoot的德行,肯定帮我们选了一个它认为最好的数据源对象,这就是HiKari。通过启动日志可以查看到对应的身影。
2021-11-29 09:39:15.202 INFO 12260 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
2021-11-29 09:39:15.208 WARN 12260 --- [ main] com.zaxxer.hikari.util.DriverDataSource : Registered driver with driverClassName=com.mysql.jdbc.Driver was not found, trying direct instantiation.
2021-11-29 09:39:15.551 INFO 12260 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
上述信息中每一行都有HiKari的身影,如果需要更换数据源,其实只需要两步即可。
- 导入对应的技术坐标
- 配置使用指定的数据源类型
下面就切换一下数据源对象
步骤①:导入对应的坐标(注意,是坐标,此处不是starter)
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
</dependencies>
步骤②:修改配置,在数据源配置中有一个type属性,专用于指定数据源类型
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
这里其实要提出一个问题的,目前的数据源配置格式是一个通用格式,不管你换什么数据源都可以用这种形式进行配置。但是新的问题又来了,如果对数据源进行个性化的配置,例如配置数据源对应的连接数量,这个时候就有新的问题了。每个数据源技术对应的配置名称都一样吗?肯定不是啊,各个厂商不可能提前商量好都写一样的名字啊,怎么办?就要使用专用的配置格式了。这个时候上面这种通用格式就不能使用了,怎么办?还能怎么办?按照SpringBoot整合其他技术的通用规则来套啊,导入对应的starter,进行相应的配置即可。
步骤①:导入对应的starter
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.11</version>
</dependency>
步骤②:修改配置
spring:
# datasource配置
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/spring?serverTimezone=UTC
username: root
password: 806823
注意观察,配置项中,在datasource下面并不是直接配置url这些属性的,而是先配置了一个druid节点,然后再配置的url这些东西。言外之意,url这个属性时druid下面的属性,那你能想到吗?除了这4个常规配置外,还有druid专用的其他配置。通过提示功能可以打开druid相关的配置查阅

与druid相关的配置超过200条以上,这就告诉你,如果想做druid相关的配置,使用这种格式就可以了,这里就不展开描述了,太多了。
这是我们做的第4个技术的整合方案,还是那两句话:导入对应starter,使用对应配置。没了,SpringBoot整合其他技术就这么简单粗暴。
总结
- 整合Druid需要导入Druid对应的starter
- 根据Druid提供的配置方式进行配置
- 整合第三方技术通用方式
- 导入对应的starter
- 根据提供的配置格式,配置非默认值对应的配置项
5)分页删除功能小BUG
由于使用了分页功能,当最后一页只有一条数据时,删除操作就会出现BUG,最后一页无数据但是独立展示,对分页查询功能进行后台功能维护,如果当前页码值大于最大页码值,重新执行查询。其实这个问题解决方案很多,这里给出比较简单的一种处理方案
@GetMapping("{currentPage}/{pageSize}")
public R getPage(@PathVariable int currentPage,@PathVariable int pageSize){
IPage<Book> page = bookService.getPage(currentPage, pageSize);
//如果当前页码值大于了总页码值,那么重新执行查询操作,使用最大页码值作为当前页码值
if( currentPage > page.getPages()){
page = bookService.getPage((int)page.getPages(), pageSize);
}
return new R(true, page);
}
运维部分
1)打包运行配置
java –jar springboot.jar –-属性名=值
属性优先级
现在我们的程序配置受两个地方控制了,第一配置文件,第二临时属性。并且我们发现临时属性的加载优先级要高于配置文件的。那是否还有其他的配置方式呢?其实是有的,而且还不少,打开官方文档中对应的内容,就可以查看配置读取的优先顺序。地址奉上:[https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config]

我们可以看到,居然有14种配置的位置,而我们现在使用的是这里面的2个。第3条Config data说的就是使用配置文件,第11条Command line arguments说的就是使用命令行临时参数。而这14种配置的顺序就是SpringBoot加载配置的顺序,言外之意,命令行临时属性比配置文件的加载优先级高,所以这个列表上面的优先级低,下面的优先级高。其实这个东西不用背的,你就记得一点,你最终要什么效果,你自己是知道的,不管这个顺序是怎么个高低排序,开发时一定要配置成你要的顺序为准。这个顺序只是在你想不明白问题的时候帮助你分析罢了。
比如你现在加载了一个user.name属性。结果你发现出来的结果和你想的不一样,那肯定是别的优先级比你高的属性覆盖你的配置属性了,那你就可以看着这个顺序挨个排查。哪个位置有可能覆盖了你的属性。
我在课程评论区看到小伙伴学习基础篇的时候问这个问题了,就是这个原因造成的。在yaml中配置了user.name属性值,然后读取出来的时候居然不是自己的配置值,因为在系统属性中有一个属性叫做user.name,两个相互冲突了。而系统属性的加载优先顺序在上面这个列表中是5号,高于3号,所以SpringBoot最终会加载系统配置属性user.name。
2)配置文件分类
SpringBoot提供了配置文件和临时属性的方式来对程序进行配置。前面一直说的是临时属性,这一节要说说配置文件了。其实这个配置文件我们一直在使用,只不过我们用的是SpringBoot提供的4级配置文件中的其中一个级别。4个级别分别是:
- 类路径下配置文件(一直使用的是这个,也就是resources目录中的application.yml文件)
- 类路径下config目录下配置文件
- 程序包所在目录中配置文件
- 程序包所在目录中config目录下配置文件
好复杂,一个一个说。其实上述4种文件是提供给你了4种配置文件书写的位置,功能都是一样的,都是做配置的。那大家关心的就是差别了,没错,就是因为位置不同,产生了差异。总体上来说,4种配置文件如果都存在的话,有一个优先级的问题,说白了就是加入4个文件我都有,里面都有一样的配置,谁生效的问题。上面4个文件的加载优先顺序为
- file :config/application.yml 【最高】
- file :application.yml
- classpath:config/application.yml
- classpath:application.yml 【最低】
那为什么设计这种多种呢?说一个最典型的应用吧。
- 场景A:你作为一个开发者,你做程序的时候为了方便自己写代码,配置的数据库肯定是连接你自己本机的,咱们使用4这个级别,也就是之前一直用的application.yml。
- 场景B:现在项目开发到了一个阶段,要联调测试了,连接的数据库是测试服务器的数据库,肯定要换一组配置吧。你可以选择把你之前的文件中的内容都改了,目前还不麻烦。
- 场景C:测试完了,一切OK。你继续写你的代码,你发现你原来写的配置文件被改成测试服务器的内容了,你要再改回来。现在明白了不?场景B中把你的内容都改掉了,你现在要重新改回来,以后呢?改来改去吗?
解决方案很简单,用上面的3这个级别的配置文件就可以快速解决这个问题,再写一个配置就行了。两个配置文件共存,因为config目录中的配置加载优先级比你的高,所以配置项如果和级别4里面的内容相同就覆盖了,这样是不是很简单?
级别1和2什么时候使用呢?程序打包以后就要用这个级别了,管你程序里面配置写的是什么?我的级别高,可以轻松覆盖你,就不用考虑这些配置冲突的问题了。
总结
-
配置文件分为4种
- 项目类路径配置文件:服务于开发人员本机开发与测试
- 项目类路径config目录中配置文件:服务于项目经理整体调控
- 工程路径配置文件:服务于运维人员配置涉密线上环境
- 工程路径config目录中配置文件:服务于运维经理整体调控
-
多层级配置文件间的属性采用叠加并覆盖的形式作用于程序
3)多环境分组管理
作为程序员在搞配置的时候往往处于一种分久必合合久必分的局面。开始先写一起,后来为了方便维护就拆分。对于多环境开发也是如此,下面给大家说一下如何基于多环境开发做配置独立管理,务必掌握。
准备工作
将所有的配置根据功能对配置文件中的信息进行拆分,并制作成独立的配置文件,命名规则如下
- application-devDB.yml
- application-devRedis.yml
- application-devMVC.yml
使用
使用include属性在激活指定环境的情况下,同时对多个环境进行加载使其生效,多个环境间使用逗号分隔
spring:
profiles:
active: dev
include: devDB,devRedis,devMVC
比较一下,现在相当于加载dev配置时,再加载对应的3组配置,从结构上就很清晰,用了什么,对应的名称是什么
注意
当主环境dev与其他环境有相同属性时,主环境属性生效;其他环境中有相同属性时,最后加载的环境属性生效
在上面例子中就是dev生效,dev没有的话,devMVC生效,其次devRedis,最后devDB
改良
但是上面的设置也有一个问题,比如我要切换dev环境为pro时,include也要修改。因为include属性只能使用一次,这就比较麻烦了。SpringBoot从2.4版开始使用group属性替代include属性,降低了配置书写量。简单说就是我先写好,你爱用哪个用哪个。
spring:
profiles:
active: dev
group:
"dev": devDB,devRedis,devMVC
"pro": proDB,proRedis,proMVC
"test": testDB,testRedis,testMVC
现在再来看,如果切换dev到pro,只需要改一下是不是就结束了?完美!
总结
- 多环境开发使用group属性设置配置文件分组,便于线上维护管理
4)多环境开发控制
多环境开发到这里基本上说完了,最后说一个冲突问题。就是maven和SpringBoot同时设置多环境的话怎么搞。
要想处理这个冲突问题,你要先理清一个关系,究竟谁在多环境开发中其主导地位。也就是说如果现在都设置了多环境,谁的应该是保留下来的,另一个应该遵从相同的设置。
maven是做什么的?项目构建管理的,最终生成代码包的,SpringBoot是干什么的?简化开发的。简化,又不是其主导作用。最终还是要靠maven来管理整个工程,所以SpringBoot应该听maven的。整个确认后下面就好做了。大体思想如下:
- 先在maven环境中设置用什么具体的环境
- 在SpringBoot中读取maven设置的环境即可
maven中设置多环境(使用属性方式区分环境)
<profiles>
<profile>
<id>env_dev</id>
<properties>
<profile.active>dev</profile.active>
</properties>
<activation>
<activeByDefault>true</activeByDefault> <!--默认启动环境-->
</activation>
</profile>
<profile>
<id>env_pro</id>
<properties>
<profile.active>pro</profile.active>
</properties>
</profile>
</profiles>
SpringBoot中读取maven设置值
spring:
profiles:
active: @profile.active@
上面的@属性名@就是读取maven中配置的属性值的语法格式。
总结
- 当Maven与SpringBoot同时对多环境进行控制时,以Mavn为主,SpringBoot使用@…@占位符读取Maven对应的配置属性值
- 基于SpringBoot读取Maven配置属性的前提下,如果在Idea下测试工程时pom.xml每次更新需要手动compile方可生效
5)日志部分
日志的输出级别
- TRACE:运行堆栈信息,使用率低
- DEBUG:程序员调试代码使用
- INFO:记录运维过程数据
- WARN:记录运维过程报警数据
- ERROR:记录错误堆栈信息
- FATAL:灾难信息,合并计入ERROR
一般情况下,开发时候使用DEBUG,上线后使用INFO,运维信息记录使用WARN即可。下面就设置一下日志级别:
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true
这么设置太简单粗暴了,日志系统通常都提供了细粒度的控制
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true
# 设置日志级别,root表示根节点,即整体应用日志级别
logging:
level:
root: debug
还可以再设置更细粒度的控制
设置日志组,控制指定包对应的日志输出级别,也可以直接控制指定包对应的日志输出级别
logging:
# 设置日志组
group:
# 自定义组名,设置当前组中所包含的包
ebank: com.itheima.controller
level:
root: warn
# 为对应组设置日志级别
ebank: debug
# 为对包设置日志级别
com.itheima.controller: debug
日志输出格式控制
日志已经能够记录了,但是目前记录的格式是SpringBoot给我们提供的,如果想自定义控制就需要自己设置了。先分析一下当前日志的记录格式。

对于单条日志信息来说,日期,触发位置,记录信息是最核心的信息。级别用于做筛选过滤,PID与线程名用于做精准分析。了解这些信息后就可以DIY日志格式了。本课程不做详细的研究,有兴趣的小伙伴可以学习相关的知识。下面给出课程中模拟的官方日志模板的书写格式,便于大家学习。
logging:
pattern:
console: "%d %clr(%p) --- [%16t] %clr(%-40.40c){cyan} : %m %n"
日志文件
日志信息显示,记录已经控制住了,下面就要说一下日志的转存了。日志不能仅显示在控制台上,要把日志记录到文件中,方便后期维护查阅。
对于日志文件的使用存在各种各样的策略,例如每日记录,分类记录,报警后记录等。这里主要研究日志文件如何记录。
记录日志到文件中格式非常简单,设置日志文件名即可。
logging:
file:
name: server.log
虽然使用上述格式可以将日志记录下来了,但是面对线上的复杂情况,一个文件记录肯定是不能够满足运维要求的,通常会每天记录日志文件,同时为了便于维护,还要限制每个日志文件的大小。下面给出日志文件的常用配置方式:
logging:
logback:
rollingpolicy:
max-file-size: 3KB
file-name-pattern: server.%d{yyyy-MM-dd}.%i.log
以上格式是基于logback日志技术设置每日日志文件的设置格式,要求容量到达3KB以后就转存信息到第二个文件中。文件命名规则中的%d标识日期,%i是一个递增变量,用于区分日志文件。
6)热部署
参与热部署监控的文件范围配置
通过修改项目中的文件,你可以发现其实并不是所有的文件修改都会激活热部署的,原因在于在开发者工具中有一组配置,当满足了配置中的条件后,才会启动热部署,配置中默认不参与热部署的目录信息如下
- /META-INF/maven
- /META-INF/resources
- /resources
- /static
- /public
- /templates
以上目录中的文件如果发生变化,是不参与热部署的。如果想修改配置,可以通过application.yml文件进行设定哪些文件不参与热部署操作
spring:
devtools:
restart:
# 设置不参与热部署的文件或文件夹
exclude: static/**,public/**,config/application.yml
关闭热部署
spring:
devtools:
restart:
enabled: false
高级实用部分
1)配置高级
1)@ConfigurationProperties
使用该注解不仅可以自定义为bean绑定属性,还可以为第三方bean绑定属性。
@Bean
@ConfigurationProperties(prefix = "datasource")
public DruidDataSource dataSource() {
return new DruidDataSource();
}
datasource:
driverClassName: com.mysql.cj.jdbc.Driver
操作方式完全一样,只不过@ConfigurationProperties注解不仅能添加到类上,还可以添加到方法上,添加到类上是为spring容器管理的当前类的对象绑定属性,添加到方法上是为spring容器管理的当前方法的返回值对象绑定属性,其实本质上都一样。
做到这其实就出现了一个新的问题,目前我们定义bean不是通过类注解定义就是通过@Bean定义,使用@ConfigurationProperties注解可以为bean进行属性绑定,那在一个业务系统中,哪些bean通过注解@ConfigurationProperties去绑定属性了呢?因为这个注解不仅可以写在类上,还可以写在方法上,所以找起来就比较麻烦了。为了解决这个问题,spring给我们提供了一个全新的注解,专门标注使用@ConfigurationProperties注解绑定属性的bean是哪些。这个注解叫做@EnableConfigurationProperties。具体如何使用呢?
步骤①:在配置类上开启@EnableConfigurationProperties注解,并标注要使用@ConfigurationProperties注解绑定属性的类
@SpringBootApplication
@EnableConfigurationProperties(ServerConfig.class)
public class Springboot13ConfigurationApplication {
}
步骤②:在对应的类上直接使用@ConfigurationProperties进行属性绑定
@Data
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
private String ipAddress;
private int port;
private long timeout;
}
有人感觉这没区别啊?注意观察,现在绑定属性的ServerConfig类并没有声明@Component注解。当使用@EnableConfigurationProperties注解时,spring会默认将其标注的类定义为bean,因此无需再次声明@Component注解了。
总结
- 使用@ConfigurationProperties可以为使用@Bean声明的第三方bean绑定属性
- 当使用@EnableConfigurationProperties声明进行属性绑定的bean后,无需使用@Component注解再次进行bean声明
2)宽松绑定
在ServerConfig中的ipAddress属性名
@Component
@Data
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
private String ipAddress;
}
可以与下面的配置属性名规则全兼容
servers:
ipAddress: 192.168.0.2 # 驼峰模式
ip_address: 192.168.0.2 # 下划线模式
ip-address: 192.168.0.2 # 烤肉串模式
IP_ADDRESS: 192.168.0.2 # 常量模式
总结
- @ConfigurationProperties绑定属性时支持属性名宽松绑定,这个宽松体现在属性名的命名规则上
- @Value注解不支持松散绑定规则
- 绑定前缀名推荐采用烤肉串命名规则,即使用中划线做分隔符
3)常用计量单位绑定
@Data
@Component
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
private String ipAddress;
private Integer port;
private Long timeout;
// @DurationUnit(ChronoUnit.HOURS)
private Duration serverTimeOut;
// @DataSizeUnit(DataUnit.MEGABYTES)
private DataSize dataSize;
}
Duration:表示时间间隔,可以通过@DurationUnit注解描述时间单位,例如上例中描述的单位为小时(ChronoUnit.HOURS)
DataSize:表示存储空间,可以通过@DataSizeUnit注解描述存储空间单位,例如上例中描述的单位为MB(DataUnit.MEGABYTES)
servers:
ip-address: 192.168.80.128
port: 8080
timeout: -1
server-time-out: 3H
data-size: 10MB
也可以不用注解绑定,直接在yml配置文件中写明计量单位
4)数据类型转换BUG
有关spring属性注入的问题到这里基本上就讲完了,但是最近一名开发者向我咨询了一个问题,我觉得需要给各位学习者分享一下。在学习阶段其实我们遇到的问题往往复杂度比较低,单一性比较强,但是到了线上开发时,都是综合性的问题,而这个开发者遇到的问题就是由于bean的属性注入引发的灾难。
先把问题描述一下,这位开发者连接数据库正常操作,但是运行程序后显示的信息是密码错误。
java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
其实看到这个报错,几乎所有的学习者都能分辨出来,这是用户名和密码不匹配,就就是密码输入错了,但是问题就在于密码并没有输入错误,这就比较讨厌了。给的报错信息无法帮助你有效的分析问题,甚至会给你带到沟里。如果是初学者,估计这会心态就崩了,我密码没错啊,你怎么能说我有错误呢?来看看用户名密码的配置是如何写的:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
username: root
password: 0127
这名开发者的生日是1月27日,所以密码就使用了0127,其实问题就出在这里了。
之前在基础篇讲属性注入时,提到过类型相关的知识,在整数相关知识中有这么一句话,支持二进制,八进制,十六进制

这个问题就处在这里了,因为0127在开发者眼中是一个字符串“0127”,但是在springboot看来,这就是一个数字,而且是一个八进制的数字。当后台使用String类型接收数据时,如果配置文件中配置了一个整数值,他是先安装整数进行处理,读取后再转换成字符串。巧了,0127撞上了八进制的格式,所以最终以十进制数字87的结果存在了。
这里提两个注意点,第一,字符串标准书写加上引号包裹,养成习惯,第二,遇到0开头的数据多注意吧。
总结
- yaml文件中对于数字的定义支持进制书写格式,如需使用字符串请使用引号明确标注
2)测试
1)加载测试专用属性
// properties属性可以为当前测试用例添加临时属性
//@SpringBootTest(properties = {"test.prop=testValue1"})
// args属性可以为当前的测试用例添加临时的命令行参数
//@SpringBootTest(args = {"--test.prop=testValue2"})
// properties属性覆盖args
@SpringBootTest(properties = {"test.prop=testValue1"}, args = {"--test.prop=testValue2"})
public class PropertiesAndArgsTest {
@Value("${test.prop}")
private String msg;
@Test
void propertiesTest() {
System.out.println(msg);
}
}
test:
prop: testValue
优势:比多环境开发中的测试环境影响范围更小,仅对当前测试类有效
2)Web环境模拟测试
在测试中对表现层功能进行测试需要一个基础和一个功能。所谓的一个基础是运行测试程序时,必须启动web环境,不然没法测试web功能。一个功能是必须在测试程序中具备发送web请求的能力,不然无法实现web功能的测试。所以在测试用例中测试表现层接口这项工作就转换成了两件事,一,如何在测试类中启动web测试,二,如何在测试类中发送web请求。下面一件事一件事进行,先说第一个
测试类中启动web环境
每一个springboot的测试类上方都会标准@SpringBootTest注解,而注解带有一个属性,叫做webEnvironment。通过该属性就可以设置在测试用例中启动web环境,具体如下:
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class WebTest {
}
测试类中启动web环境时,可以指定启动的Web环境对应的端口,springboot提供了4种设置值,分别如下:
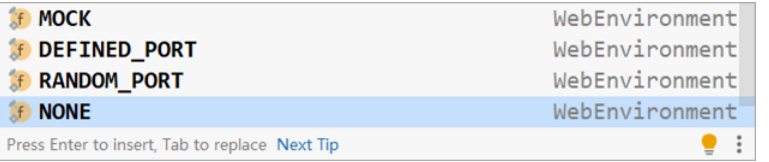
- MOCK:根据当前设置确认是否启动web环境,例如使用了Servlet的API就启动web环境,属于适配性的配置
- DEFINED_PORT:使用自定义的端口作为web服务器端口
- RANDOM_PORT:使用随机端口作为web服务器端口
- NONE:不启动web环境
通过上述配置,现在启动测试程序时就可以正常启用web环境了,建议大家测试时使用RANDOM_PORT,避免代码中因为写死设定引发线上功能打包测试时由于端口冲突导致意外现象的出现。就是说你程序中写了用8080端口,结果线上环境8080端口被占用了,结果你代码中所有写的东西都要改,这就是写死代码的代价。现在你用随机端口就可以测试出来你有没有这种问题的隐患了。
测试环境中的web环境已经搭建好了,下面就可以来解决第二个问题了,如何在程序代码中发送web请求。
测试类中发送请求
对于测试类中发送请求,其实java的API就提供对应的功能,只不过平时各位小伙伴接触的比较少,所以较为陌生。springboot为了便于开发者进行对应的功能开发,对其又进行了包装,简化了开发步骤,具体操作如下:
步骤①:在测试类中开启web虚拟调用功能,通过注解@AutoConfigureMockMvc实现此功能的开启
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
}
步骤②:定义发起虚拟调用的对象MockMVC,通过自动装配的形式初始化对象
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
@Test
void testWeb(@Autowired MockMvc mvc) {
}
}
步骤③:创建一个虚拟请求对象,封装请求的路径,并使用MockMVC对象发送对应请求
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
@Test
void testWeb(@Autowired MockMvc mvc) throws Exception {
//http://localhost:8080/books
//创建虚拟请求,当前访问/books
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
//执行对应的请求
mvc.perform(builder);
}
}
执行测试程序,现在就可以正常的发送/books对应的请求了,注意访问路径不要写http://localhost:8080/books,因为前面的服务器IP地址和端口使用的是当前虚拟的web环境,无需指定,仅指定请求的具体路径即可。
总结
- 在测试类中测试web层接口要保障测试类启动时启动web容器,使用@SpringBootTest注解的webEnvironment属性可以虚拟web环境用于测试
- 为测试方法注入MockMvc对象,通过MockMvc对象可以发送虚拟请求,模拟web请求调用过程
web环境请求结果比对
@Test
void testStatus() throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mockMvc.perform(builder);
// 设置预期值 与真实值比较 成功,测试通过 失败,测试失败
// 定义本次调用的预期值
StatusResultMatchers status = MockMvcResultMatchers.status();
// 预期本次成功
ResultMatcher ok = status.isOk();
// 进行结果匹配
action.andExpect(ok);
}
@Test
void testBody() throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mockMvc.perform(builder);
// 设置预期值 与真实值比较 成功,测试通过 失败,测试失败
// 定义本次调用的预期值
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.string("springboot2");
// 进行结果匹配
action.andExpect(result);
}
- 响应体匹配(json数据格式,开发中的主流使用方式)
@Test
void testJson() throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/get");
ResultActions action = mockMvc.perform(builder);
// 设置预期值 与真实值比较 成功,测试通过 失败,测试失败
// 定义本次调用的预期值
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.json("{\"id\":1,\"name\":\"springboot2\",\"type\":\"springboot\"}");
// 进行结果匹配
action.andExpect(result);
}
@Test
void testContentType() throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mockMvc.perform(builder);
// 设定预期值 与真实值进行比较,成功测试通过,失败测试失败
// 定义本次调用的预期值
HeaderResultMatchers header = MockMvcResultMatchers.header();
ResultMatcher contentType = header.string("Content-Type", "application/json");
// 添加预计值到本次调用过程中进行匹配
action.andExpect(contentType);
}
@Test
void testGetById() throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books/get");
ResultActions action = mockMvc.perform(builder);
StatusResultMatchers status = MockMvcResultMatchers.status();
ResultMatcher ok = status.isOk();
action.andExpect(ok);
HeaderResultMatchers header = MockMvcResultMatchers.header();
ResultMatcher contentType = header.string("Content-Type", "application/json");
action.andExpect(contentType);
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.json("{\"id\":1,\"name\":\"springboot\",\"type\":\"springboot\"}");
action.andExpect(result);
}
4)数据层测试回滚
当前我们的测试程序可以完美的进行表现层、业务层、数据层接口对应的功能测试了,但是测试用例开发完成后,在打包的阶段由于test生命周期属于必须被运行的生命周期,如果跳过会给系统带来极高的安全隐患,所以测试用例必须执行。但是新的问题就呈现了,测试用例如果测试时产生了事务提交就会在测试过程中对数据库数据产生影响,进而产生垃圾数据。这个过程不是我们希望发生的,作为开发者测试用例该运行运行,但是过程中产生的数据不要在我的系统中留痕,这样该如何处理呢?
springboot早就为开发者想到了这个问题,并且针对此问题给出了最简解决方案,在原始测试用例中添加注解@Transactional即可实现当前测试用例的事务不提交。当程序运行后,只要注解@Transactional出现的位置存在注解@SpringBootTest,springboot就会认为这是一个测试程序,无需提交事务,所以也就可以避免事务的提交。
@SpringBootTest
@Transactional
@Rollback(true)
public class DaoTest {
@Autowired
private BookService bookService;
@Test
void testSave(){
Book book = new Book();
book.setName("springboot3");
book.setType("springboot3");
book.setDescription("springboot3");
bookService.save(book);
}
}
如果开发者想提交事务,也可以,再添加一个@RollBack的注解,设置回滚状态为false即可正常提交事务,是不是很方便?springboot在辅助开发者日常工作这一块展现出了惊人的能力,实在太贴心了。
总结
- 在springboot的测试类中通过添加注解@Transactional来阻止测试用例提交事务
- 通过注解@Rollback控制springboot测试类执行结果是否提交事务,需要配合注解@Transactional使用
思考
当前测试程序已经近乎完美了,但是由于测试用例中书写的测试数据属于固定数据,往往失去了测试的意义,开发者可以针对测试用例进行针对性开发,这样就有可能出现测试用例不能完美呈现业务逻辑代码是否真实有效的达成业务目标的现象,解决方案其实很容易想,测试用例的数据只要随机产生就可以了,能实现吗?咱们下一节再讲。
5)测试用例数据设定
对于测试用例的数据固定书写肯定是不合理的,springboot提供了在配置中使用随机值的机制,确保每次运行程序加载的数据都是随机的。具体如下:
testcase:
book:
id: ${random.int}
id2: ${random.int(10)}
type: ${random.int!5,10!}
name: ${random.value}
uuid: ${random.uuid}
publishTime: ${random.long}
当前配置就可以在每次运行程序时创建一组随机数据,避免每次运行时数据都是固定值的尴尬现象发生,有助于测试功能的进行。数据的加载按照之前加载数据的形式,使用@ConfigurationProperties注解即可
@Component
@Data
@ConfigurationProperties(prefix = "testcase.book")
public class BookCase {
private int id;
private int id2;
private int type;
private String name;
private String uuid;
private long publishTime;
}
对于随机值的产生,还有一些小的限定规则,比如产生的数值性数据可以设置范围等,具体如下:

- ${random.int}表示随机整数
- ${random.int(10)}表示10以内的随机数
- ${random.int(10,20)}表示10到20的随机数
- 其中()可以是任意字符,例如[],!!均可
总结
- 使用随机数据可以替换测试用例中书写的固定数据,提高测试用例中的测试数据有效性
3)数据层
1)SQL
- 数据源技术:Druid、Hikari、tomcat DataSource、DBCP
- 持久化技术:MyBatisPlus、MyBatis、JdbcTemplate
- 数据库技术:MySQL、H2、HSQL、Derby
2)NoSQL
SpringBoot中redis客户端选择
springboot整合redis技术提供了多种客户端兼容模式,默认提供的是lettucs客户端技术,也可以根据需要切换成指定客户端技术,例如jedis客户端技术,切换成jedis客户端技术操作步骤如下:
步骤①:导入jedis坐标
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
jedis坐标受springboot管理,无需提供版本号
步骤②:配置客户端技术类型,设置为jedis
spring:
redis:
host: localhost
port: 6379
client-type: jedis
步骤③:根据需要设置对应的配置
spring:
redis:
host: localhost
port: 6379
client-type: jedis
lettuce:
pool:
max-active: 16
jedis:
pool:
max-active: 16
lettcus与jedis区别
- jedis连接Redis服务器是直连模式,当多线程模式下使用jedis会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就大受影响
- lettcus基于Netty框架进行与Redis服务器连接,底层设计中采用StatefulRedisConnection。 StatefulRedisConnection自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然lettcus也支持多连接实例一起工作
ES中整合
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
@SpringBootTest
public class ESTest {
@Resource
private BookMapper bookMapper;
private RestHighLevelClient client;
@BeforeEach
void setUp() {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
}
@AfterEach
void tearDown() throws IOException {
client.close();
}
/**
* 创建索引
*/
@Test
void test() throws IOException {
// 客户端操作
CreateIndexRequest request = new CreateIndexRequest("books");
// 获取操作索引的客户端对象,调用创建索引操作
client.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 创建索引(ik分词器)
*/
@Test
void testCreateIndexByIK() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
String json = """
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"type": {
"type": "keyword"
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
""";
// 设置请求中的参数
request.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 添加文档
*/
@Test
void testCreateDoc() throws IOException {
Book book = bookMapper.selectById(1);
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
/**
* 批量添加文档
*/
@Test
void testCreateDocAll() throws IOException {
List<Book> bookList = bookMapper.selectList(null);
BulkRequest bulkRequest = new BulkRequest();
for (Book book : bookList) {
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String source = JSON.toJSONString(book);
request.source(source, XContentType.JSON);
bulkRequest.add(request);
}
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}
/**
* 按id查询
*/
@Test
void testGet() throws IOException {
GetRequest getRequest = new GetRequest("books", "1");
GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
String source = response.getSourceAsString();
System.out.println(source);
}
/**
* 按条件查询
*/
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("books");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryBuilder query = QueryBuilders.termQuery("all", "spring");
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsString();
System.out.println(source);
Book book = JSON.parseObject(source, Book.class);
System.out.println(book);
}
}
}
4)缓存
Ehcache缓存
步骤①:导入Ehcache的坐标
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
</dependency>
此处为什么不是导入Ehcache的starter,而是导入技术坐标呢?其实springboot整合缓存技术做的是通用格式,不管你整合哪种缓存技术,只是实现变化了,操作方式一样。这也体现出springboot技术的优点,统一同类技术的整合方式。
步骤②:配置缓存技术实现使用Ehcache
spring:
cache:
type: ehcache
ehcache:
config: ehcache.xml
配置缓存的类型type为ehcache,此处需要说明一下,当前springboot可以整合的缓存技术中包含有ehcach,所以可以这样书写。其实这个type不可以随便写的,不是随便写一个名称就可以整合的。
由于ehcache的配置有独立的配置文件格式,因此还需要指定ehcache的配置文件,以便于读取相应配置
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="D:\ehcache" />
<!--默认缓存策略 -->
<!-- external:是否永久存在,设置为true则不会被清除,此时与timeout冲突,通常设置为false-->
<!-- diskPersistent:是否启用磁盘持久化-->
<!-- maxElementsInMemory:最大缓存数量-->
<!-- overflowToDisk:超过最大缓存数量是否持久化到磁盘-->
<!-- timeToIdleSeconds:最大不活动间隔,设置过长缓存容易溢出,设置过短无效果,可用于记录时效性数据,例如验证码-->
<!-- timeToLiveSeconds:最大存活时间-->
<!-- memoryStoreEvictionPolicy:缓存清除策略-->
<defaultCache
eternal="false"
diskPersistent="false"
maxElementsInMemory="1000"
overflowToDisk="false"
timeToIdleSeconds="60"
timeToLiveSeconds="60"
memoryStoreEvictionPolicy="LRU" />
<cache
name="smsCode"
eternal="false"
diskPersistent="false"
maxElementsInMemory="1000"
overflowToDisk="false"
timeToIdleSeconds="10"
timeToLiveSeconds="10"
memoryStoreEvictionPolicy="LRU" />
</ehcache>
注意前面的案例中,设置了数据保存的位置是smsCode
@CachePut(value = "smsCode", key = "#tele")
public String sendCodeToSMS(String tele) {
String code = codeUtils.generator(tele);
return code;
}
这个设定需要保障ehcache中有一个缓存空间名称叫做smsCode的配置,前后要统一。在企业开发过程中,通过设置不同名称的cache来设定不同的缓存策略,应用于不同的缓存数据。
到这里springboot整合Ehcache就做完了,可以发现一点,原始代码没有任何修改,仅仅是加了一组配置就可以变更缓存供应商了,这也是springboot提供了统一的缓存操作接口的优势,变更实现并不影响原始代码的书写。
总结
- springboot使用Ehcache作为缓存实现需要导入Ehcache的坐标
- 修改设置,配置缓存供应商为ehcache,并提供对应的缓存配置文件
5)定时任务与邮件
定时任务
步骤①:开启定时任务功能,在引导类上开启定时任务功能的开关,使用注解@EnableScheduling
@SpringBootApplication
//开启定时任务功能
@EnableScheduling
public class Springboot22TaskApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot22TaskApplication.class, args);
}
}
步骤②:定义Bean,在对应要定时执行的操作上方,使用注解@Scheduled定义执行的时间,执行时间的描述方式还是cron表达式
@Component
public class MyBean {
@Scheduled(cron = "0/1 * * * * ?")
public void print(){
System.out.println(Thread.currentThread().getName()+" :spring task run...");
}
}
完事,这就完成了定时任务的配置。总体感觉其实什么东西都没少,只不过没有将所有的信息都抽取成bean,而是直接使用注解绑定定时执行任务的事情而已。
如何想对定时任务进行相关配置,可以通过配置文件进行
spring:
task:
scheduling:
pool:
size: 1 # 任务调度线程池大小 默认 1
thread-name-prefix: ssm_ # 调度线程名称前缀 默认 scheduling-
shutdown:
await-termination: false # 线程池关闭时等待所有任务完成
await-termination-period: 10s # 调度线程关闭前最大等待时间,确保最后一定关闭
总结
-
spring task需要使用注解@EnableScheduling开启定时任务功能
-
为定时执行的的任务设置执行周期,描述方式cron表达式
邮件
步骤①:导入springboot整合javamail的starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>
步骤②:配置邮箱的登录信息
spring:
# 邮件相关配置
mail:
host: smtp.126.com
username: test@126.com
password: test
# qq邮箱
mail:
host: smtp.qq.com
username: 2300858713@qq.com
password:
java程序仅用于发送邮件,邮件的功能还是邮件供应商提供的,所以这里是用别人的邮件服务,要配置对应信息。
host配置的是提供邮件服务的主机协议,当前程序仅用于发送邮件,因此配置的是smtp的协议。
password并不是邮箱账号的登录密码,是邮件供应商提供的一个加密后的密码,也是为了保障系统安全性。不然外部人员通过地址访问下载了配置文件,直接获取到了邮件密码就会有极大的安全隐患。有关该密码的获取每个邮件供应商提供的方式都不一样,此处略过。可以到邮件供应商的设置页面找POP3或IMAP这些关键词找到对应的获取位置。下例仅供参考:
步骤③:使用JavaMailSender接口发送邮件
@SpringBootTest
public class SendMailTest {
@Autowired
private JavaMailSender javaMailSender;
//发送人
private String from = "test@qq.com";
//接收人
private String to = "test@126.com";
//标题
private String subject = "测试邮件";
/**
* 发送简单邮件
*/
@Test
void sendSimpleMail() {
// 正文
String context = "测试邮件正文内容";
SimpleMailMessage simpleMessage = new SimpleMailMessage();
simpleMessage.setFrom(from);
simpleMessage.setTo(to);
simpleMessage.setSubject(subject);
simpleMessage.setText(context);
javaMailSender.send(simpleMessage);
}
/**
* 发送复杂邮件---网页正文邮件
*/
@Test
void sendComplexMail1() {
//正文
String context = "<img src='ABC.JPG'/><a href='https://www.itcast.cn'>点开有惊喜</a>";
try {
MimeMessage mimeMessage = javaMailSender.createMimeMessage();
MimeMessageHelper mimeMessageHelper = new MimeMessageHelper(mimeMessage);
mimeMessageHelper.setFrom(from);
mimeMessageHelper.setTo(to);
mimeMessageHelper.setSubject(subject);
mimeMessageHelper.setText(context, true); // 此处设置正文支持html解析
javaMailSender.send(mimeMessage);
} catch (MessagingException e) {
throw new RuntimeException(e);
}
}
/**
* 发送复杂邮件---带有附件
*/
@Test
void sendComplexMail2() {
//正文
String context = "测试邮件正文";
try {
MimeMessage mimeMessage = javaMailSender.createMimeMessage();
MimeMessageHelper mimeMessageHelper = new MimeMessageHelper(mimeMessage, true); // 此处设置支持附件
mimeMessageHelper.setFrom(from);
mimeMessageHelper.setTo(to);
mimeMessageHelper.setSubject(subject);
mimeMessageHelper.setText(context);
File file1 = new File("springboot_23_mail-0.0.1-SNAPSHOT.jar");
File file2 = new File("resources\\logo.png");
mimeMessageHelper.addAttachment(file1.getName(), file1);
mimeMessageHelper.addAttachment("teng.png", file2);
javaMailSender.send(mimeMessage);
} catch (MessagingException e) {
throw new RuntimeException(e);
}
}
}
6)消息
1)RabbitMQ
使用docker安装rabbitmq
整合direct模型
RabbitMQ满足AMQP协议,因此不同的消息模型对应的制作不同,先使用最简单的direct模型开发。
步骤①:导入springboot整合amqp的starter,amqp协议默认实现为rabbitmq方案
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
步骤②:配置RabbitMQ的服务器地址
spring:
rabbitmq:
host: localhost
port: 5672
步骤③:初始化直连模式系统设置
由于RabbitMQ不同模型要使用不同的交换机,因此需要先初始化RabbitMQ相关的对象,例如队列,交换机等
@Configuration
public class RabbitConfigDirect {
@Bean
public Queue directQueue(){
return new Queue("direct_queue");
}
@Bean
public Queue directQueue2(){
return new Queue("direct_queue2");
}
@Bean
public DirectExchange directExchange(){
return new DirectExchange("directExchange");
}
@Bean
public Binding bindingDirect(){
return BindingBuilder.bind(directQueue()).to(directExchange()).with("direct");
}
@Bean
public Binding bindingDirect2(){
return BindingBuilder.bind(directQueue2()).to(directExchange()).with("direct2");
}
}
队列Queue与直连交换机DirectExchange创建后,还需要绑定他们之间的关系Binding,这样就可以通过交换机操作对应队列。
步骤④:使用AmqpTemplate操作RabbitMQ
@Service
public class MessageServiceRabbitmqDirectImpl implements MessageService {
@Autowired
private AmqpTemplate amqpTemplate;
@Override
public void sendMessage(String id) {
System.out.println("待发送短信的订单已纳入处理队列(rabbitmq direct),id:"+id);
amqpTemplate.convertAndSend("directExchange","direct",id);
}
}
amqp协议中的操作API接口名称看上去和jms规范的操作API接口很相似,但是传递参数差异很大。
步骤⑤:使用消息监听器在服务器启动后,监听指定位置,当消息出现后,立即消费消息
@Component
public class MessageListener {
@RabbitListener(queues = "direct_queue")
public void receive(String id){
System.out.println("已完成短信发送业务(rabbitmq direct),id:"+id);
}
}
使用注解@RabbitListener定义当前方法监听RabbitMQ中指定名称的消息队列。
整合(topic模型)
步骤①:同上
步骤②:同上
步骤③:初始化主题模式系统设置
@Configuration
public class RabbitConfigTopic {
@Bean
public Queue topicQueue(){
return new Queue("topic_queue");
}
@Bean
public Queue topicQueue2(){
return new Queue("topic_queue2");
}
@Bean
public TopicExchange topicExchange(){
return new TopicExchange("topicExchange");
}
@Bean
public Binding bindingTopic(){
return BindingBuilder.bind(topicQueue()).to(topicExchange()).with("topic.*.id");
}
@Bean
public Binding bindingTopic2(){
return BindingBuilder.bind(topicQueue2()).to(topicExchange()).with("topic.orders.*");
}
}
主题模式支持routingKey匹配模式,*表示匹配一个单词,#表示匹配任意内容,这样就可以通过主题交换机将消息分发到不同的队列中,详细内容请参看RabbitMQ系列课程。
| 匹配键 |
topic.*.* |
topic.# |
| topic.order.id |
true |
true |
| order.topic.id |
false |
false |
| topic.sm.order.id |
false |
true |
| topic.sm.id |
false |
true |
| topic.id.order |
true |
true |
| topic.id |
false |
true |
| topic.order |
false |
true |
步骤④:使用AmqpTemplate操作RabbitMQ
@Service
public class MessageServiceRabbitmqTopicImpl implements MessageService {
@Autowired
private AmqpTemplate amqpTemplate;
@Override
public void sendMessage(String id) {
System.out.println("待发送短信的订单已纳入处理队列(rabbitmq topic),id:"+id);
amqpTemplate.convertAndSend("topicExchange","topic.orders.id",id);
}
}
发送消息后,根据当前提供的routingKey与绑定交换机时设定的routingKey进行匹配,规则匹配成功消息才会进入到对应的队列中。
步骤⑤:使用消息监听器在服务器启动后,监听指定队列
@Component
public class MessageListener {
@RabbitListener(queues = "topic_queue")
public void receive(String id){
System.out.println("已完成短信发送业务(rabbitmq topic 1),id:"+id);
}
@RabbitListener(queues = "topic_queue2")
public void receive2(String id){
System.out.println("已完成短信发送业务(rabbitmq topic 22222222),id:"+id);
}
}
使用注解@RabbitListener定义当前方法监听RabbitMQ中指定名称的消息队列。
总结
- springboot整合RabbitMQ提供了AmqpTemplate对象作为客户端操作消息队列
- 操作RabbitMQ需要配置RabbitMQ服务器地址,默认端口5672
- 企业开发时通常使用监听器来处理消息队列中的消息,设置监听器使用注解@RabbitListener
- RabbitMQ有5种消息模型,使用的队列相同,但是交换机不同。交换机不同,对应的消息进入的策略也不同
2)RocketMQ
略
7)监控
springboot抽取了大部分监控系统的常用指标,提出了监控的总思想。然后就有好心的同志根据监控的总思想,制作了一个通用性很强的监控系统,因为是基于springboot监控的核心思想制作的,所以这个程序被命名为Spring Boot Admin。
Spring Boot Admin,这是一个开源社区项目,用于管理和监控SpringBoot应用程序。这个项目中包含有客户端和服务端两部分,而监控平台指的就是服务端。我们做的程序如果需要被监控,将我们做的程序制作成客户端,然后配置服务端地址后,服务端就可以通过HTTP请求的方式从客户端获取对应的信息,并通过UI界面展示对应信息。
下面就来开发这套监控程序,先制作服务端,其实服务端可以理解为是一个web程序,收到一些信息后展示这些信息。
服务端开发
步骤①:导入springboot admin对应的starter,版本与当前使用的springboot版本保持一致,并将其配置成web工程
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
上述过程可以通过创建项目时使用勾选的形式完成。
步骤②:在引导类上添加注解@EnableAdminServer,声明当前应用启动后作为SpringBootAdmin的服务器使用
@SpringBootApplication
@EnableAdminServer
public class Springboot25AdminServerApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot25AdminServerApplication.class, args);
}
}
做到这里,这个服务器就开发好了,启动后就可以访问当前程序了,界面如下。
于目前没有启动任何被监控的程序,所以里面什么信息都没有。下面制作一个被监控的客户端程序。
客户端开发
客户端程序开发其实和服务端开发思路基本相似,多了一些配置而已。
步骤①:导入springboot admin对应的starter,版本与当前使用的springboot版本保持一致,并将其配置成web工程
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
上述过程也可以通过创建项目时使用勾选的形式完成,不过一定要小心,端口配置成不一样的,否则会冲突。
步骤②:设置当前客户端将信息上传到哪个服务器上,通过yml文件配置
spring:
boot:
admin:
client:
url: http://localhost:8080
做到这里,这个客户端就可以启动了。启动后再次访问服务端程序,界面如下。
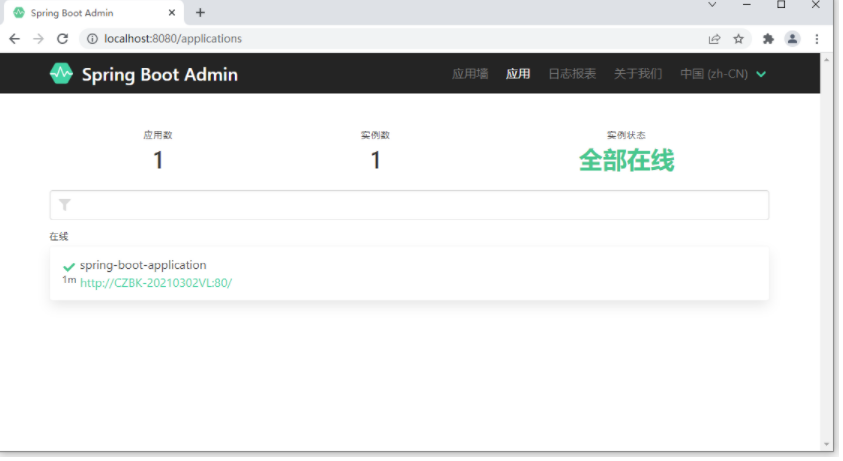
可以看到,当前监控了1个程序,点击进去查看详细信息。
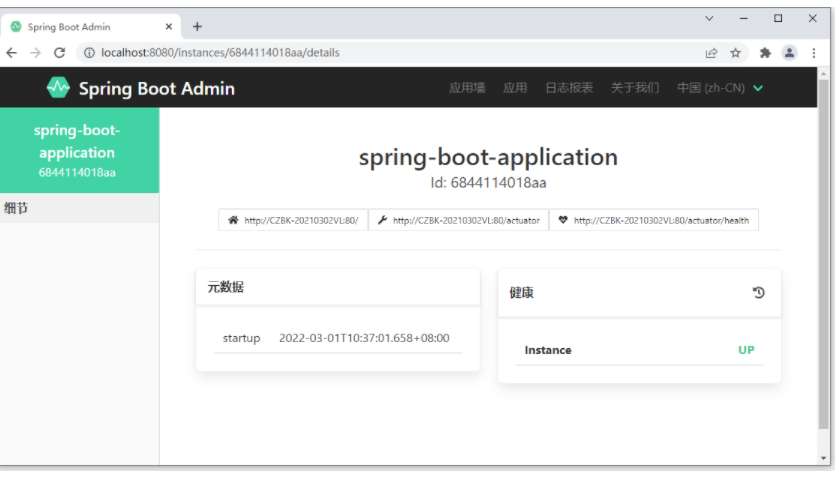
由于当前没有设置开放哪些信息给监控服务器,所以目前看不到什么有效的信息。下面需要做两组配置就可以看到信息了。
-
开放指定信息给服务器看
-
允许服务器以HTTP请求的方式获取对应的信息
配置如下:
server:
port: 80
spring:
boot:
admin:
client:
url: http://localhost:8080
management:
endpoint:
health:
show-details: always
endpoints:
web:
exposure:
include: "*"
springbootadmin的客户端默认开放了13组信息给服务器,但是这些信息除了一个之外,其他的信息都不让通过HTTP请求查看。所以你看到的信息基本上就没什么内容了,只能看到一个内容,就是下面的健康信息。
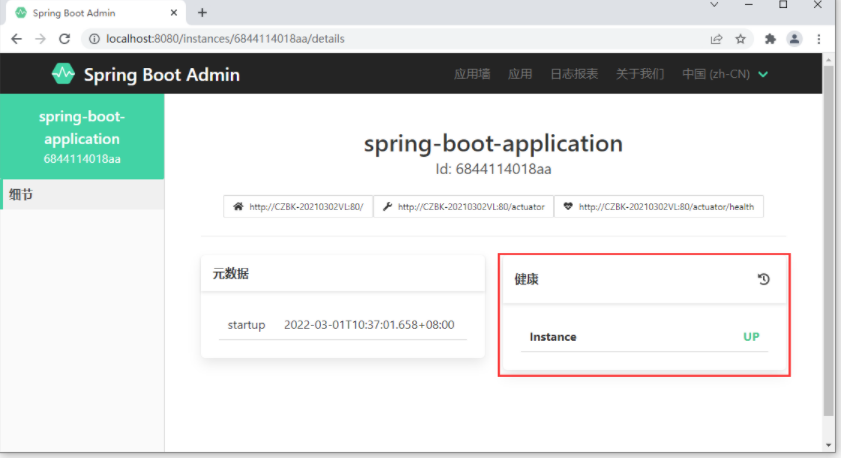
但是即便如此我们看到健康信息中也没什么内容,原因在于健康信息中有一些信息描述了你当前应用使用了什么技术等信息,如果无脑的对外暴露功能会有安全隐患。通过配置就可以开放所有的健康信息明细查看了。
management:
endpoint:
health:
show-details: always
健康明细信息如下:
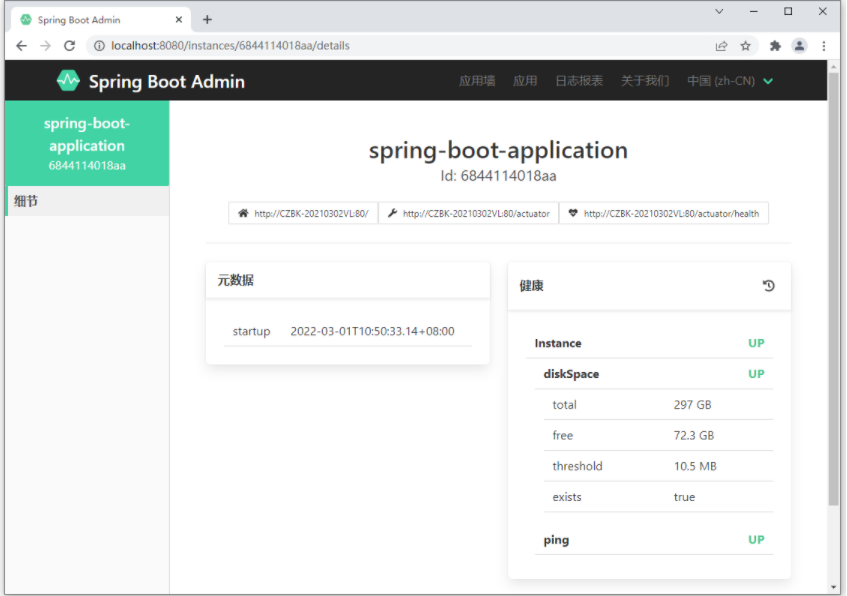
目前除了健康信息,其他信息都查阅不了。原因在于其他12种信息是默认不提供给服务器通过HTTP请求查阅的,所以需要开启查阅的内容项,使用*表示查阅全部。记得带引号
endpoints:
web:
exposure:
include: "*"
配置后再刷新服务器页面,就可以看到所有的信息了。
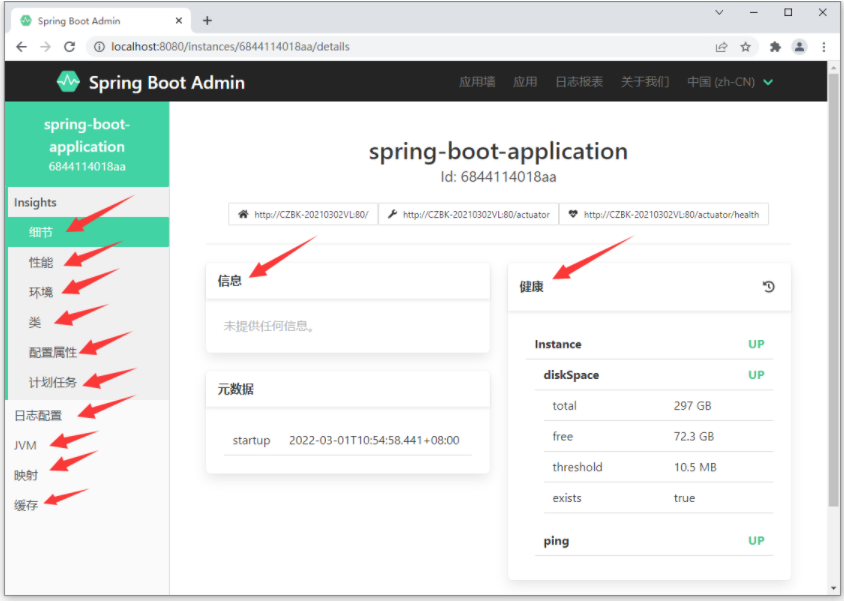
以上界面中展示的信息量就非常大了,包含了13组信息,有性能指标监控,加载的bean列表,加载的系统属性,日志的显示控制等等。
总结
- 开发监控服务端需要导入坐标,然后在引导类上添加注解@EnableAdminServer,并将其配置成web程序即可
- 开发被监控的客户端需要导入坐标,然后配置服务端服务器地址,并做开放指标的设定即可
- 在监控平台中可以查阅到各种各样被监控的指标,前提是客户端开放了被监控的指标
监控原理
Actuator,可以称为端点,描述了一组监控信息,SpringBootAdmin提供了多个内置端点,通过访问端点就可以获取对应的监控信息,也可以根据需要自定义端点信息。通过发送请求路劲**/actuator可以访问应用所有端点信息,如果端点中还有明细信息可以发送请求/actuator/端点名称**来获取详细信息。以下列出了所有端点信息说明:
| ID |
描述 |
默认启用 |
| auditevents |
暴露当前应用程序的审计事件信息。 |
是 |
| beans |
显示应用程序中所有 Spring bean 的完整列表。 |
是 |
| caches |
暴露可用的缓存。 |
是 |
| conditions |
显示在配置和自动配置类上评估的条件以及它们匹配或不匹配的原因。 |
是 |
| configprops |
显示所有 @ConfigurationProperties 的校对清单。 |
是 |
| env |
暴露 Spring ConfigurableEnvironment 中的属性。 |
是 |
| flyway |
显示已应用的 Flyway 数据库迁移。 |
是 |
| health |
显示应用程序健康信息 |
是 |
| httptrace |
显示 HTTP 追踪信息(默认情况下,最后 100 个 HTTP 请求/响应交换)。 |
是 |
| info |
显示应用程序信息。 |
是 |
| integrationgraph |
显示 Spring Integration 图。 |
是 |
| loggers |
显示和修改应用程序中日志记录器的配置。 |
是 |
| liquibase |
显示已应用的 Liquibase 数据库迁移。 |
是 |
| metrics |
显示当前应用程序的指标度量信息。 |
是 |
| mappings |
显示所有 @RequestMapping 路径的整理清单。 |
是 |
| scheduledtasks |
显示应用程序中的调度任务。 |
是 |
| sessions |
允许从 Spring Session 支持的会话存储中检索和删除用户会话。当使用 Spring Session 的响应式 Web 应用程序支持时不可用。 |
是 |
| shutdown |
正常关闭应用程序。 |
否 |
| threaddump |
执行线程 dump。 |
是 |
| heapdump |
返回一个 hprof 堆 dump 文件。 |
是 |
| jolokia |
通过 HTTP 暴露 JMX bean(当 Jolokia 在 classpath 上时,不适用于 WebFlux)。 |
是 |
| logfile |
返回日志文件的内容(如果已设置 logging.file 或 logging.path 属性)。支持使用 HTTP Range 头来检索部分日志文件的内容。 |
是 |
| prometheus |
以可以由 Prometheus 服务器抓取的格式暴露指标。 |
是 |
上述端点每一项代表被监控的指标,如果对外开放则监控平台可以查询到对应的端点信息,如果未开放则无法查询对应的端点信息。通过配置可以设置端点是否对外开放功能。使用enable属性控制端点是否对外开放。其中health端点为默认端点,不能关闭。
management:
endpoint:
health: # 端点名称
show-details: always
info: # 端点名称
enabled: true # 是否开放
为了方便开发者快速配置端点,springboot admin设置了13个较为常用的端点作为默认开放的端点,如果需要控制默认开放的端点的开放状态,可以通过配置设置,如下:
management:
endpoints:
enabled-by-default: true # 是否开启默认端点,默认值true
上述端点开启后,就可以通过端点对应的路径查看对应的信息了。但是此时还不能通过HTTP请求查询此信息,还需要开启通过HTTP请求查询的端点名称,使用“*”可以简化配置成开放所有端点的WEB端HTTP请求权限。
management:
endpoints:
web:
exposure:
include: "*"
整体上来说,对于端点的配置有两组信息,一组是endpoints开头的,对所有端点进行配置,一组是endpoint开头的,对具体端点进行配置。
management:
endpoint: # 具体端点的配置
health:
show-details: always
info:
enabled: true
endpoints: # 全部端点的配置
web:
exposure:
include: "*"
enabled-by-default: true
总结
-
被监控客户端通过添加actuator的坐标可以对外提供被访问的端点功能
-
端点功能的开放与关闭可以通过配置进行控制
-
web端默认无法获取所有端点信息,通过配置开放端点功能