前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
- 小项目小需求驱动
- 总结各种方式
- 页面源代码返回数据(Xpath、Bs4、PyQuery、正则)
- 接口返回数据
一、需求
- 获取一品威客任务数据
- 获取码市需求任务
- 获取软件项目交易网需求任务
- 获取YesPMP平台需求任务
二、分析
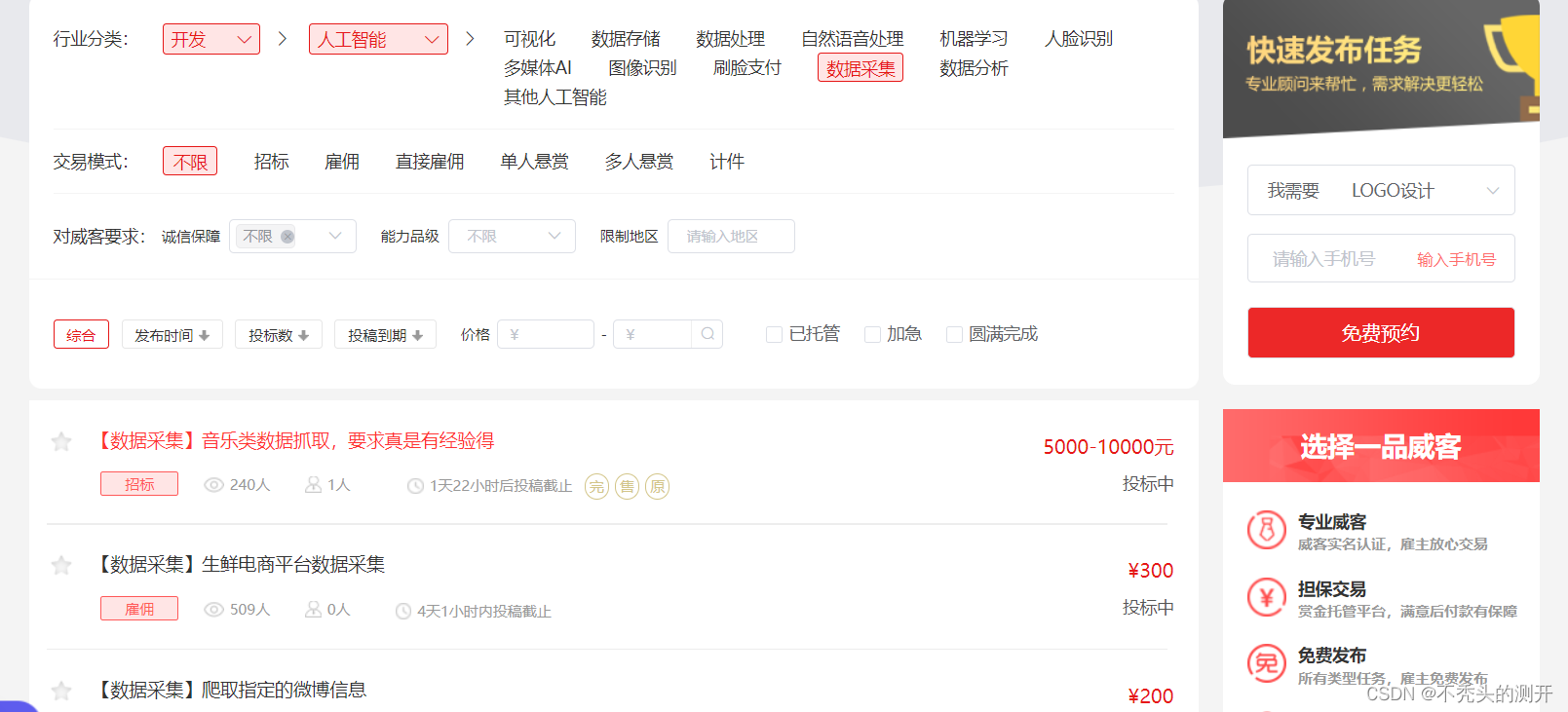
一品威客
1、查看网页源代码
2、查找数据
3、获取详情页(赏金、任务要求、需求、状态)
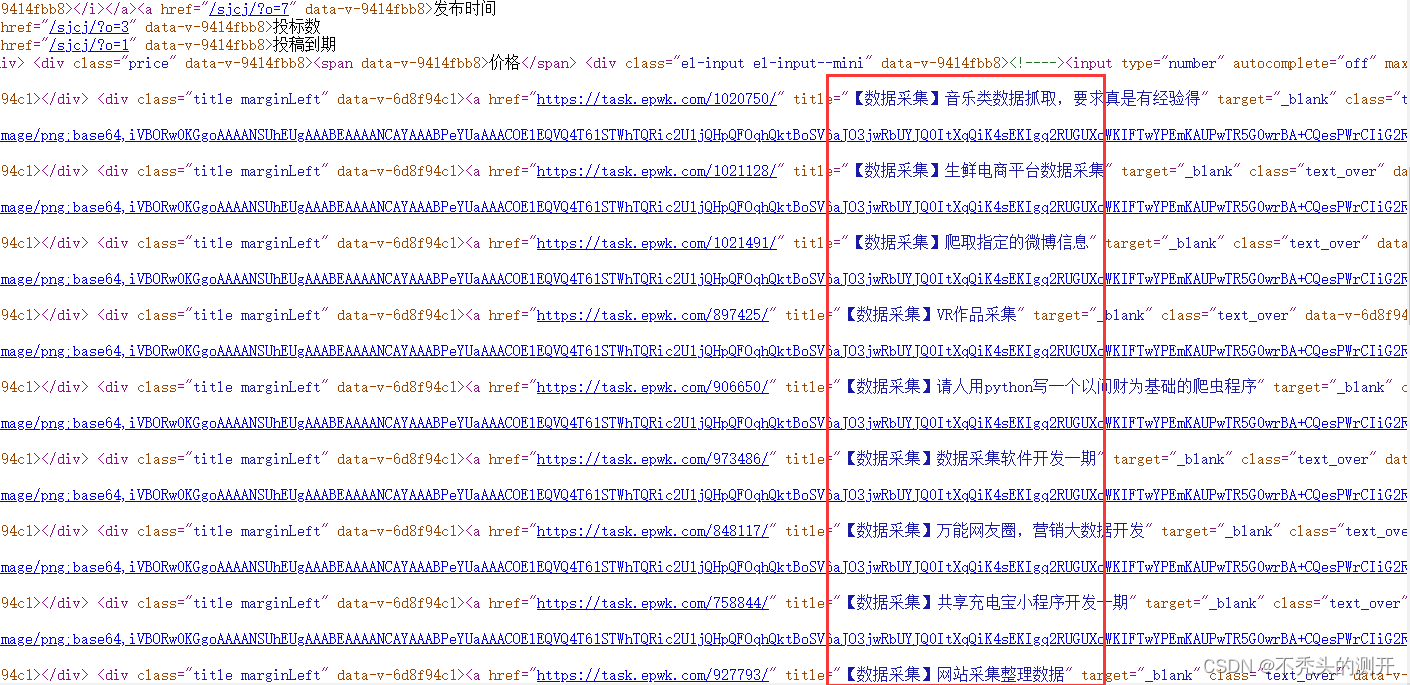
软件项目交易网
1、查看网页源码
2、全局搜索数据


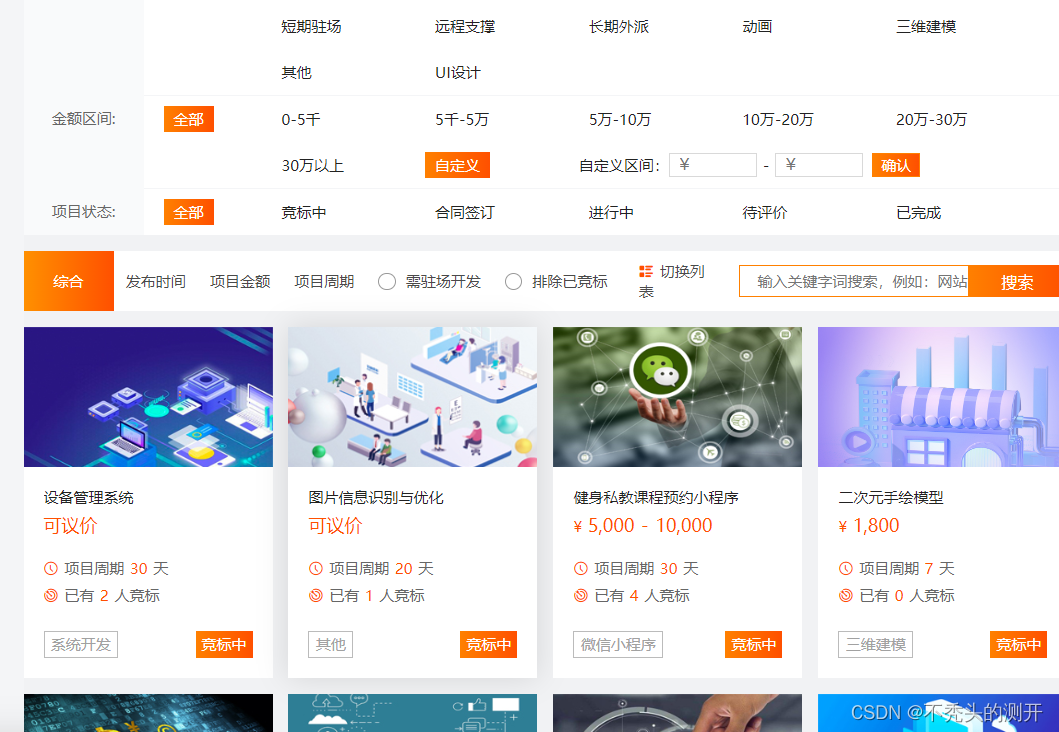
获取YesPMP平台需求任务
1、查看网页源代码
2、全局搜索数据

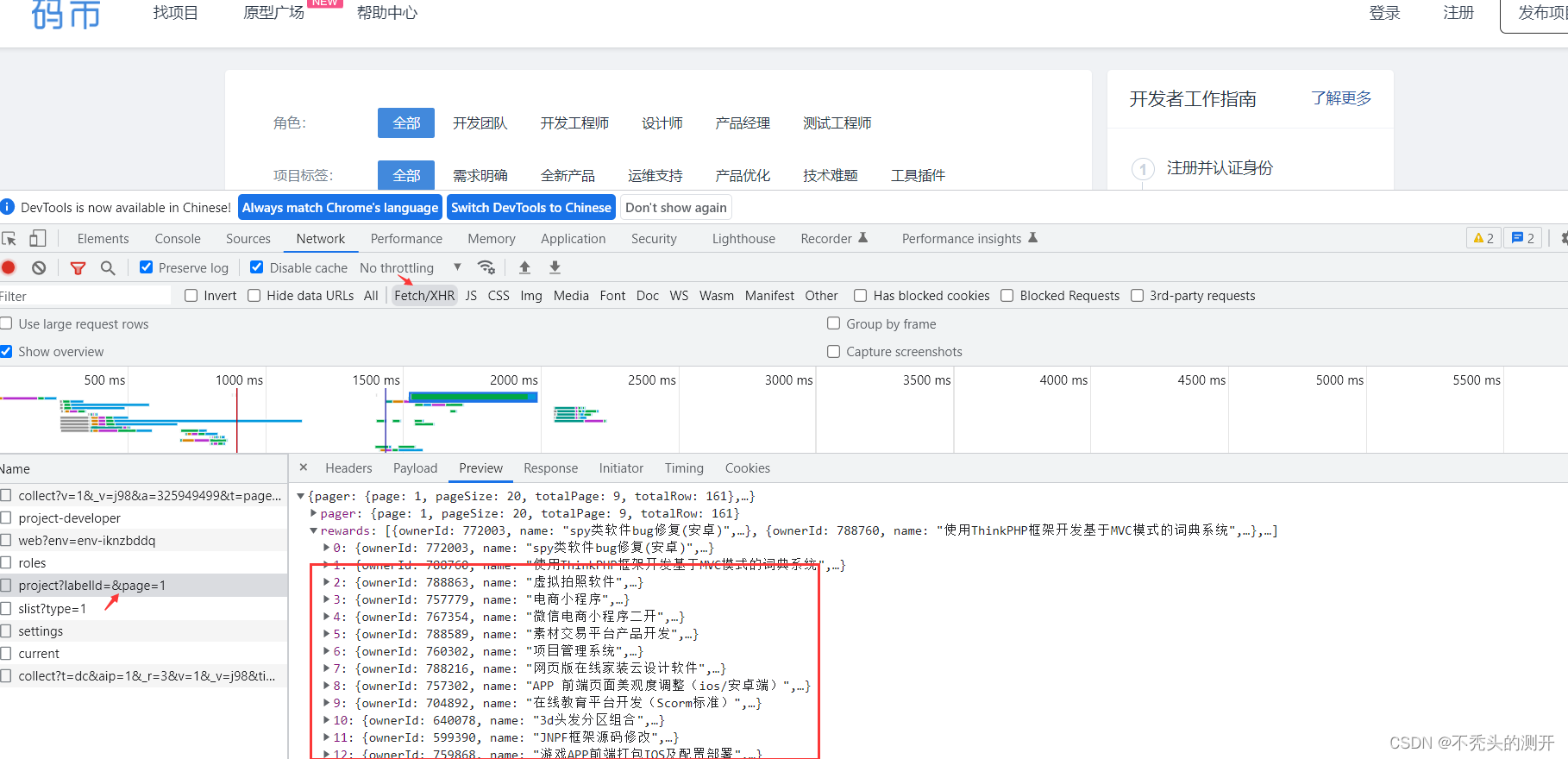
码市
1、F12抓包即可获取数据
2、构造请求即可获取数据
三、处理
一品威客
1、任务页任务
2、详情页(处理直接雇佣)
3、获取赏金、任务要求、时间
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from bs4 import BeautifulSoup
import re
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"}
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
def method_bs4(html):
page = BeautifulSoup(html, "html.parser")
return page
def method_zz(code):
deal = re.compile(r'<meta name="description" content="(?P<is_direct>.*?)" />',re.S)
result = deal.finditer(code)
for i in result:
check = i.group("is_direct")
if "直接雇佣任务" in check:
return True
def get_task_url(html):
page = method_bs4(html)
div = page.select(".title.marginLeft")
url_list = {}
for _div in div:
content_url = _div.find("a")["href"]
content = _div.text
task = content.split("【数据采集】")[1]
url_list[task] = content_url
return url_list
def get_task_content(url_dict):
with open("一品威客任务.txt",mode="a+", encoding="utf-8") as f:
for name, url in url_dict.items():
code_source = get_index_source(url)
page = method_bs4(code_source)
money = page.select(".nummoney.f_l span")
for _money in money:
task_money = _money.text.strip("\n").strip(" ")
print(task_money)
result = method_zz(code_source)
if result:
f.write(f"直接雇佣-{name}{task_money}\n")
time = page.select("#TimeCountdown")
for _time in time:
start_time = _time["starttime"]
end_time = _time["endtime"]
print(start_time,end_time)
content = page.select(".task-info-content p")
for _content in content:
content_data = _content.text
print(content_data)
f.write(f"{name}---{content_data},{task_money},{start_time},{end_time}\n")
if __name__ == '__main__':
url = "https://task.epwk.com/sjcj/"
html = get_index_source(url)
url_dict = get_task_url(html)
get_task_content(url_dict)
软件项目交易网
通过Xpath即可获取对应数据
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from lxml import etree
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"}
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
def method_xpath(html):
parse = etree.HTML(html)
return parse
def get_task_info(html):
with open("软件交易网站需求.txt",mode="w",encoding="utf-8") as f:
parse = method_xpath(html)
result = parse.xpath('//*[@id="projectLists"]/div/ul/li')
for li in result:
status = li.xpath('./div[@class="left_2"]/span/text()')[1]
status = status.strip()
task = li.xpath('./div[@class="left_8"]/h4/a/text()')
task_content = task[-1].strip()
bond = li.xpath('./div[@class="left_8"]/span[1]/em/text()')[0]
hot = li.xpath('./div[@class="left_8"]/span[2]/em/text()')[0]
start_time = li.xpath('./div[@class="left_8"]/span[3]/em/text()')[0]
end_time = li.xpath('./div[@class="left_8"]/span[4]/em/text()')[0]
f.write(f"{status},{task_content},{bond},{hot},{start_time},{end_time}\n")
if __name__ == '__main__':
url = "https://www.sxsoft.com/page/project"
html = get_index_source(url)
get_task_info(html)
获取YesPMP平台需求任务
通过PQuery即可获取数据
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from pyquery import PyQuery as pq
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"}
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
def method_pq(html):
parse = pq(html)
return parse
def get_task_info(html):
with open("yespmp网站需求.txt",mode="a",encoding="utf-8") as f:
parse = method_pq(html)
result =parse.find(".promain")
for _ in result.items():
task_name = _.find(".name").text()
price = _.find(".price").text()
date = _.find(".date").text()
bid_num = _.find(".num").text()
f.write(f"{task_name},{price},{date},{bid_num}\n")
if __name__ == '__main__':
for i in range(2,10):
url = f"https://www.yespmp.com/project/index_i{i}.html"
html = get_index_source(url)
get_task_info(html)
码市
基本request请求操作(请求头、参数)
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
import json
headers = {
'cookie': 'mid=6c15e915-d258-41fc-93d9-939a767006da; JSESSIONID=1hfpjvpxsef73sbjoak5g5ehi; _gid=GA1.2.846977299.1668222244; _hjSessionUser_2257705=eyJpZCI6ImI3YzVkMTc5LWM3ZDktNTVmNS04NGZkLTY0YzUxNGY3Mzk5YyIsImNyZWF0ZWQiOjE2NjgyMjIyNDM0NzgsImV4aXN0aW5nIjp0cnVlfQ==; _ga_991F75Z0FG=GS1.1.1668245580.3.1.1668245580.0.0.0; _ga=GA1.2.157466615.1668222243; _gat=1',
'referer': 'https://codemart.com/projects?labelId=&page=1',
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
def get_data():
url = "https://codemart.com/api/project?labelId=&page=1"
payload = {}
response = requests.request("GET", url, headers=headers, data=payload)
print(json.loads(response.text))
if __name__ == '__main__':
get_data()
四、总结
- Xpath
- 适用于要获取的信息在某个标签下,且各标签层次明显,通过路径找到位置,for循环遍历即可
- Bs4
- 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
- PyQuery
- 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
- 正则
- 通过(.*?)就可以处理元素失效或者定位少量信息
- 不适用网页代码有很多其它符号,定位失效
- 接口返回数据
- 对于接口没有进行加密,通过requests构造请求即可获取数据
- 关注点在请求头中的参数
欢迎加入免费的知识星球内!
我正在「Print(“Hello Python”)」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/076uG3kOn
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)