▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
摘要:本文作者刘杰,介绍了顺丰科技数仓的架构,趟过的一些问题、使用 Hudi 来优化整个 job 状态的实践细节,以及未来的一些规划。主要内容为:
数仓架构
Hudi 代码躺过的坑
状态优化
未来规划
Tips:点击「阅读原文」即可查看更多技术文章
 GitHub 地址
GitHub 地址 
欢迎大家给 Flink 点赞送 star~

顺丰科技早在 2019 年引入 Hudi ,当时是基于 Spark 批处理,2020 年对数据的实时性要求更高公司对架构进行了升级,在社区 Hudi on Flink 的半成品上持续优化实现 Binlog 数据 CDC 入湖。在 Hudi 社区飞速发展的同时公司今年对数仓也提出了新的要求,最终采用 Flink + Hudi 的方式来宽表的实时化。过程中遇到了很多问题主要有两点:
Hudi Master 代码当时存在一些漏洞;
宽表涉及到多个 Join,Top One 等操作使得状态很大。
庆幸的是社区的修复速度很给力加上 Hudi 强大 upsert 能力使这两个问题得到以有效的解决。
一、数仓架构
感兴趣的同学可以参考之前顺丰分享的《Hudi on Flink 在顺丰的实践应用》
▼ 文章点击 ▼
Hudi on Flink 在顺丰的实践应用
二、Hudi 代码趟过的坑
在去年我们是基于 Hudi 0.6 左右进行的 Hudi on Flink 的实践,代码较老。为了拥抱社区我们使用最新 master 代码进行实践,在大数据量写入场景中,发现了一个比较隐秘的丢数问题,这个问题花了将近两周的时间才定位到。
1. Hudi StreamWriteFunction 算子核心流程梳理
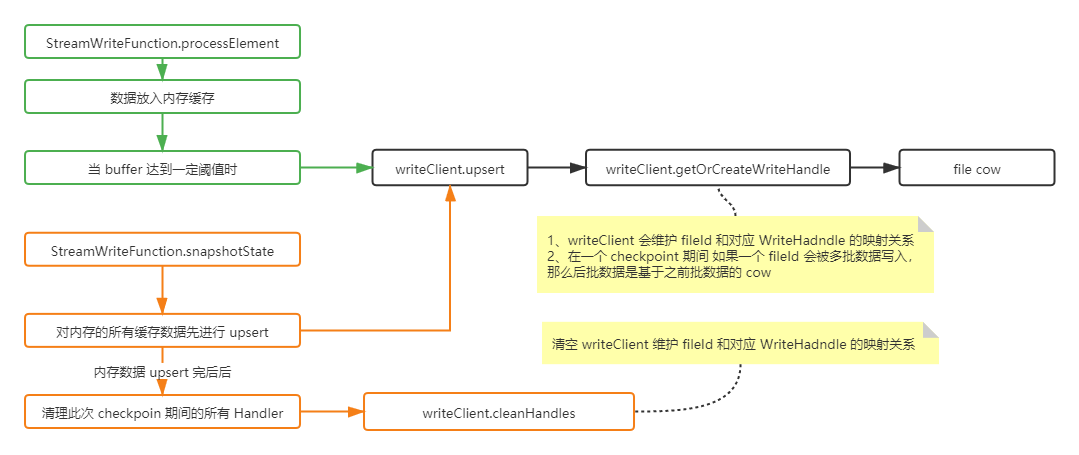
StreamWriteFunction算子收数据的时候会先把数据按照 fileld 分组缓存好,数据的持续流会使得缓存数据越来越大,当达到一定阈值时便会执行 flush。阈值由 2 个核心参数控制:write.batch.size 默认 64M ,write.task.max.size 默认 1G 。当单个分组数据达到 64M 或者总缓存数据达到 800M ~ 1G 就会触发 flush 。
flush 会调用 client 的 api 去创建一个 WriteHandle,然后把 WriteHandle 放入 Map 进行缓存,一个 handle 可以理解为对应一个文件的 cow。
如果一个 fileld 在同一 checkpoint 期间被多次写入,则后一次是基于前一次的 cow, 它的 handle 是一个FlinkMergeAndReplaceHandle,判断一个 fileld 是否之前被写入过就是根据上面 Map 缓存得来的。
StreamWriteFunction执行 snapshotState 时会把内存的所有分组数据一次进行 flush, 之后对 client 的 handle 进行清空。
2. 场景还原
Hudi 本身是具备 upsert 能力的,所以我们开始认为 Hudi Sink 在 At Least Once 模式下是没问题的,并且 At Least Once 模式下 Flink 算子不需要等待 Barrier 对齐,能够处理先到的数据使得处理速度更快,于是我们在 Copy On Write 场景中对 Flink CheckpointingMode 设置了 AT_LEAST_ONCE。
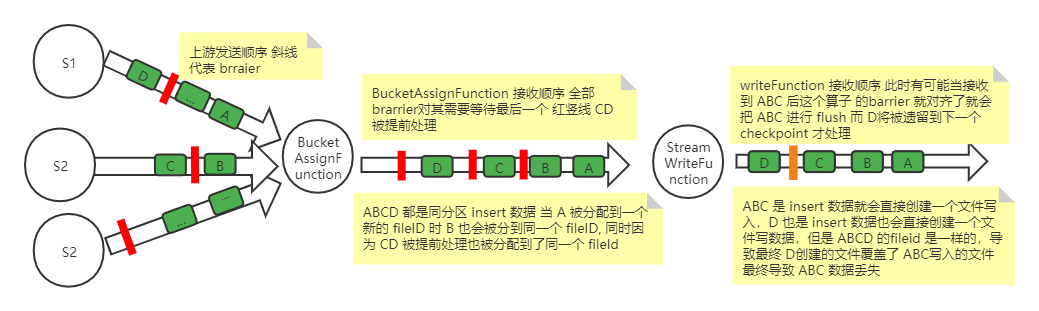
writeFunction 的上游是文件 BucketAssignFunction fileld 分配算子,假如有一批 insert 数据 A、B、C、D 属于同一个分区并且分配到同一个BucketAssignFunction 的 subtask ,但是 A、B 和 C、D 是相邻两个不同的 checkpoint。
当 A 进入BucketAssignFunction 时如果发现没有新的小文件可以使用,就会创建一个新的 fileld f0,当 B 流入时也会给他分配到 f0 上。同时因为是 AT_LEAST_ONCE 模式,C、D 数据都有可能被处理到也被分配到了 f0 上。也就是说 在 AT_LEAST_ONCE 模式下由于 C、D 数据被提前处理,导致 A、B、C、D 4 条属于两个 checkpoint 的 insert 数据被分配到了同一个 fileld。
writeFunction 有可能当接收到 A、B、C 后这个算子的 barrier 就对齐了,会把 A、B、C 进行 flush,而 D 将被遗留到下一个 checkpoint 才处理。A、B、C 是 insert 数据所以就会直接创建一个文件写入,D 属于下一个 checkpoint ,A、B、C 写入时创建的 handle 已被清理了,等到下一个 checkpoint 执行 flush。因为 D 也是 insert 数据所以也会直接创建一个文件写数据,但是 A、B、C、D 的 fileld 是一样的,导致最终 D 创建的文件覆盖了 A、B、C 写入的文件最终导致 A、B、C 数据丢失。
3. 问题定位
这个问题之所以难定位是因为具有一定随机性,每次丢失的数据都不太一样,而且小数据量不易出现。最终通过开启 Flink 的 Queryable State 进行查询, 查找丢失数据的定位到 fileld, 发现 ABCD state 的 instant 都是 I,然后解析对应 fileld 的所有版本进行跟踪还原。
三、状态优化
我们对线上最大的离线宽边进行了实时化的,宽表字段较多,涉及到多个表对主表的 left join 还包括一些 Top One 的计算,这些算子都会占用 state. 而我们的数据周期较长需要保存 180 天数据。估算下来状态大小将会达到上百 T,这无疑会对状态的持久化带来很大的压力。但是这些操作放入 Hudi 来做就显得轻而易举。
1. Top One 下沉 Hudi
在 Hudi 中有一个write.precombine.field 配置项用来指定使用某个字段对 flush 的数据去重,当出现多条数据需要去重时就会按照整个字段进行比较,保留最大的那条记录,这其实和 Top One 很像。
我们在 SQL 上将 Top One 的排序逻辑组合成了一个字段设置为 Hudi 的 write.precombine.field,同时把这个字段写入 state,同一 key 的数据多次进来时都会和 state 的 write.precombine.field 进行比较更新。
Flink Top One 的 state 默认是保存整记录的所有字段,但是我们只保存了一个字段,大大节省了 state 的大小。
2. 多表 Left Join 下沉 Hudi
■ 2.1 Flink SQL join
我们把这个场景简化成如下一个案例,假如有宽表 t_p 由三张表组成
insert into t_p
select
t0.id,t0.name,
t1.age,
t2.sex
from t0
left join t1 on t0.id = t1.id
left join t2 on t0.id = t2.id
在 Flink SQL join 算子内部会维护一个左表和右表的 state,这都是每个 table 的全字段,且多一次 join 就会多出一个 state. 最终导致 state 大小膨胀,如果 join 算子上游是一个 append 流,state 大小膨胀的效果更明显。
■ 2.2 把 Join 改写成 Union All
对于上面案例每次 left join 只是补充了几个字段,我们想到用 union all 的方式进行 SQL 改写,union all 需要补齐所有字段,缺的字段用 null 补。我们认为 null 补充的字段不是有效字段。改成从 union all 之后要求 Hudi 具备局部更新的能力才能达到 join 的效果。
不幸的是 Hudi 的默认实现是全字段覆盖,也就是说当收到 t0 的数据时会把 age sex 覆盖成 null, 收到 t1 数据时会把 name sex 覆盖成 null。这显然是不可接受的。这就要求我们对 Hudi sink 进行改造。
■ 2.3 Hudi Union All 实现
Hudi 在 cow 模式每条记录的更新写入都是对旧数据进行 copy 覆盖写入,似乎只要知道这条记录来自哪个表,哪几个字段是有效的字段就选择性的对 copy 出来的字段进行覆盖即可。但是在分区变更的场景中就不是那么好使了。在分区变更的场景中,数据从一个分区变到另一个分区的逻辑是把旧分区数据删掉,往新分区新增数据。这可能会把一些之前局部更新的字段信息丢失掉。细聊下来 Hudi on Flink 涉及到由几个核心算子组成 pipeline。

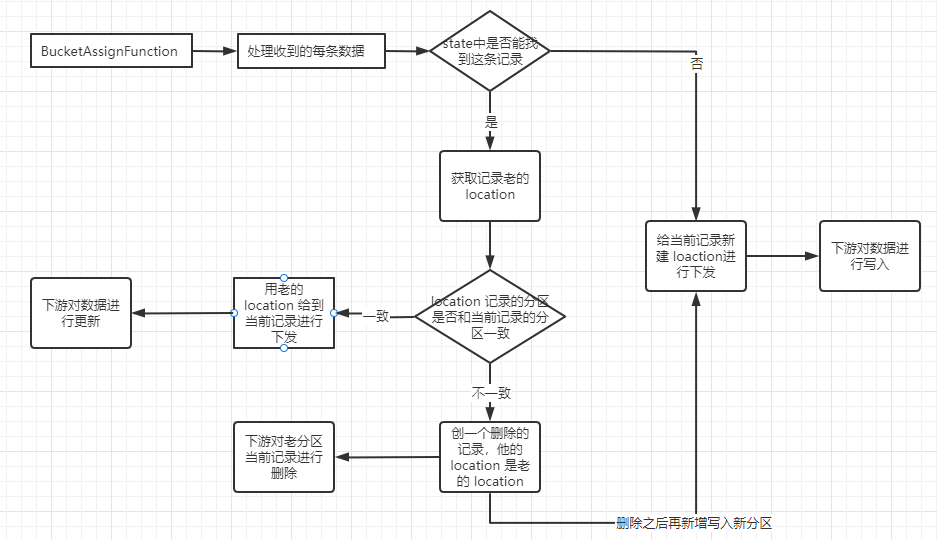
原生的 BucketAssignFunction 的算子逻辑如下图,当收到一条记录时会先从 state 里面进行查找是否之前有写过这条记录,如果有就会找对应的 location。如果分区没有发生变更,就把当前这条记录也分配给这个location,如果在 state 中没有找到 location 就会新创建一个 location,把这个新的location 分配给当前记录,并更新到 state。
总之这个 state 存储的 location 就是告诉当前记录应该从哪个文件进行更新或者写入。遇到分区变更的场景会复杂一点。假如一条记录从 2020 分区变更成了 2021,就会创建一条删除的记录,它的 loaction 是 state 中的 location。这条记录让下游进行实际的删除操作,然后再创建一个新的 location (分区是 2021) 发送到下游进行 insert。
为了在 Hudi 中实现 top one,我们对 state 信息进行了扩展,用来做 Top One 时间字段。
对于 StreamWriteFunction 在 Insert 场景中,假如收到了如下 3 条数据 {id:1,name:zs},{id:1,age:20},{id:1,sex:man},在执行 flush 时会创建一个全字段的空记录 {id:null,name:null,age:null,sex:null},然后依次和 3 条记录进行合并。注意,这个合并过程只会选择有效字段的合并。如下图:

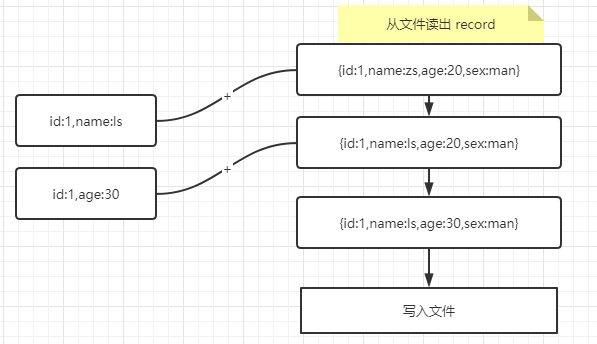
在 Update 场景中的更新逻辑类似 insert 场景,假如老数据是 {id:1,name:zs,age:20,sex:man} ,新收到了{id:1,name:ls},{id:1,age:30} 这 2 条数据,就会先从文件中把老的数据读出来,然后依次和新收到的数据进行合并,合并步骤同 insert。如下图:
这样通过 union all 的方式达到了 left join 的效果,大大节省了 state 的大小。
四、未来规划
parquet 元数据信息收集,parquet 文件可以从 footer 里面得到每个行列的最大最小等信息,我们计划在写入文件的后把这些信息收集起来,并且基于上一次的 commit 的元数据信息进行合并,生成一个包含所有文件的元数据文件,这样可以在读取数据时进行谓词下推进行文件的过滤。
公司致力于打造基于 Hudi 作为底层存储,Flink 作为流批一体化的 SQL 计算引擎,Flink 的批处理 Hudi 这块还涉足不深,未来可能会计划用 Flink 对 Hudi 实现 clustering 等功能,在 Flink 引擎上完善 Hudi 的批处理功能。
热点推荐
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,查看更多技术文章!
戳我,查看更多技术文章!