记录学习过程,如有新的发现,随时补充,如有错误或补充,请各位大佬指正。
一、前言
多线程有多种方式。std::Thread、boost::Thread、pthread、Windows库等。本文只关注std::Thread,可以跨平台运行。
二、std::Thread
thread对象构造
//头文件
#include <thread>
//函数指针,void thread_fun()
std::thread t1 ( thread_fun);
//函数对象 void thread_fun(int x)
std::thread t2 ( thread_fun(100));
//lamda表达式
std::thread th3_lamda([](int x) {
for (int i=0; i < x; ++i) {
std::cout << std::this_thread::get_id() << "," << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1 ));
}
}, 5);
//直接创建线程,没有名字void thread_fun(int x)
std::thread (thread_fun,1).join();
//类成员函数
std::thread myThread(&MyClass::threadFunction, &obj);
//obj为对应具体的对象。void MyClass::threadFunction();
thread常见成员函数
| 函数 |
作用 |
| join() |
等待线程结束并清理资源(人话:等他结束了再执行主线程) |
| joinable() |
返回线程是否可以执行join |
| detach() |
不影响主线程运行,必须线程创建时立即调用,函数不能join |
| get.id() |
获取线程ID |
| operator= |
移动构造函数 |
thread传递参数
//传递值
int a = 10;
std::thread(thread_fun , a);
//函数void thread_fun (int a);
//传递引用
int a = 10;
std::thread(thread_fun , std::ref(a));
//函数void thread_fun (int &a);
//常量引用
std::thread(thread_fun , std::cref(a));
三、mutex互斥锁
如果多个线程有共同需要使用的资源,避免冲突,要加上锁,一次只有一个线程能够使用这个资源。
头文件#include <mutex>
1、mutex基本锁
| lock() |
将mutex上锁,如果已经被其他线程上锁,就会阻塞直到解锁 |
| unlock() |
解锁mutex,如果没有获得锁的所有权就调用解锁,会发生不可知异常 |
| bool try_lock() |
尝试上锁。返回bool。lock不成功也会继续往下进行。 |
lock_guard和unique_lock的使用和区别
可以使用RAII(通过类的构造析构)来实现更好的编码方式。 RAII:也称为“资源获取就是初始化”,是c++等编程语言常用的管理资源、避免内存泄露的方法。它保证在任何情况下,使用对象时先构造对象,最后析构对象。一般锁尽量用lock_guard。
两者区别:
1、unique_lock与lock_guard都能实现自动加锁和解锁,但是前者更加灵活,能实现更多的功能。lock_guard速度和效率高一点。
2、unique_lock可以进行临时解锁和再上锁,如在构造对象之后使用lck.unlock()就可以进行解锁, lck.lock()进行上锁,而不必等到析构时自动解锁。lock_guard是不支持手动释放的。
3、condition_variable必须与uniqu_lock搭配使用。
std::unique_lock<std::mutex> lck(mtx);
std::lock_guard<std::mutex> lck(mtx);
//这种构造方式下没有区别
unique_lock的三种参数
a、只创建不锁,创建之前得没有锁住mtx
//如果线程没有锁住mutex,则可以先创建不锁。
std::unique_lock<std::mutex> lock(mtx , std::defer_lock);
lock.lock();
lock.unlock();
lock.owns_lock();//返回是否持有当前mtx的所有权
lock.try_lock_for()//锁一段时间
lock.try_lock_until();//锁到什么时间点。
b、只创建不锁,创建之前得要锁住mtx(感觉用处不多,主要用于传递锁吧)
//`std::unique_lock` 的构造函数中的 `adopt_lock` 参数用于指示该 `unique_lock` 对象在构造时,
//应该假设它已经获得了互斥锁的所有权。换句话说,`adopt_lock` 参数允许你在构造 `unique_lock`
//对象时,将一个已经获得的互斥锁传递给它,而不是在构造时尝试获得互斥锁。
//常见的情况下,使用 `adopt_lock` 参数的情况包括:
//1. 从一个函数或代码块传递已经获得的互斥锁:
//假设在某个函数中已经获得了一个互斥锁,并且你想在函数的返回值中返回一个 `unique_lock` 对象
//同时保持互斥锁的所有权,那么你可以使用 `adopt_lock` 来传递这个已经获得的互斥锁。
std::unique_lock<std::mutex> functionWithLock()
{
std::mutex mtx;
mtx.lock();
return std::unique_lock<std::mutex>(mtx, std::adopt_lock);
}
//2. 用于条件变量中的等待操作:
//当使用 `std::condition_variable` 的 `wait` 函数时,需要传入一个已经获得的互斥锁,
//用于在等待时自动释放互斥锁。这时可以使用 `adopt_lock` 参数来传递已经获得的互斥锁。
std::condition_variable cv;
std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx, std::defer_lock);
// ... 其他代码 ...
// 等待条件变量,并在等待时自动释放互斥锁
cv.wait(lock);
//需要注意的是,在使用 `adopt_lock` 参数时,你必须确保在传递互斥锁给 `unique_lock` 对象时,
//该互斥锁的所有权确实在你手中,否则会导致未定义的行为。
c、创建时尝试锁,但是锁不成功也继续执行
std::unique_lock<std::mutex>(mtx, std::try_to_lock);
传递unique_lock锁所有权
std::move(...) 或者 return unique_lock对象
2、 std::time_mutex定时锁
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until()。
try_lock_for 函数接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时,则返回 false。
try_lock_until 函数则接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时,则返回 false。
3、recursive_mutex递归锁
递归锁允许同一个线程多次获取该互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题。最后解锁的次数和上锁的次数要相等。递归互斥锁主要用于可能被连续多次上锁(期间未解锁)的情形,例如函数A、B都有加锁逻辑;而在特殊条件下,函数A调用了函数B,则需要用递归锁。最大上锁次数未知,一旦超过最大上锁次数会发生错误。
递归互斥锁的优点是可以避免死锁,缺点是容易出现死循环。
借用一个博客例子:(1条消息) C++ 各种Mutex详解_c++ mutex_游戏开发龙之介的博客-CSDN博客
#include<iostream>
#include <mutex>
#include <thread>
#include<vector>
using namespace std;
recursive_mutex mtx;
vector<char> vec;
static void push_back_c_n_cnt(int n, char c)
{
mtx.lock();
if (n == 0)
{
mtx.unlock();
return;
}
cout << n <<","<< c << endl;
vec.push_back(c);
push_back_c_n_cnt(n-1,c);
mtx.unlock();
}
int main()
{
//开启两个线程分别把*和$推进vec
thread th1(push_back_c_n_cnt, 10, '*');
thread th2(push_back_c_n_cnt, 10, '$');
th1.join();
th2.join();
cout << " print vec :" << endl;
//打印vec
for (int i = 0; i < vec.size(); i++)
{
cout << vec[i] << " ";
}
puts("");
cout << "end" << endl;;
return 0;
}
个人理解:尽量不要使用递归锁,一是效率问题,二是安全问题,会让整个代码更加复杂。上面的代码递归使用push_back,目的是实现push_back字符,那么其实使用一个普通锁,然后for循环push_back进去,再解锁即可。
4、recursive_timed_mutex定时递归锁(略)
5、C++17 shared_lock和shared_mutex共享锁
读锁不独占,可以有几个线程一起读共享变量;写锁独占,有线程写锁时,无论读写都被阻塞。 std::shared_mutex - cppreference.com https://zh.cppreference.com/w/cpp/thread/shared_mutex
https://zh.cppreference.com/w/cpp/thread/shared_mutex
std::shared_mutex mtx;
//共享锁
std::shared_lock<std::shared_mutex> read_lock(mtx);
//独占锁
std::lock_guard<std::shared_mutex> write_lock(mtx);
//或者用unique_lock
这里参考博客的示例,但是我觉得他的示例中用了普通锁,将所有线程都锁住了,一次只有一个线程进行,不能反映出共享锁和独占锁的特点,所以自己修改了一下。每隔1秒写入value,每隔0.5s读取value
(4条消息) C++多线程——读写锁shared_lock/shared_mutex_c++ 读写锁_princeteng的博客-CSDN博客
#include <iostream>
#include <mutex> //unique_lock
#include <shared_mutex> //shared_mutex shared_lock
#include <thread>
std::mutex mtx;
class ThreadSaferCounter
{
private:
mutable std::shared_mutex mutex_;
int value_ = 0;
public:
ThreadSaferCounter(/* args */) {};
~ThreadSaferCounter() {};
int get() const {
//读者, 获取共享锁, 使用shared_lock
std::shared_lock<std::shared_mutex> lck(mutex_);//执行mutex_.lock_shared();
//std::cout << "reader #" << std::this_thread::get_id();
auto now = std::chrono::system_clock::now();
auto timestamp = std::chrono::duration_cast<std::chrono::microseconds>(now.time_since_epoch()).count();
//std::cout << timestamp << " get " << value_ << std::endl;
std::printf("time %ld get %d \n",timestamp,value_);
return value_; //lck 析构, 执行mutex_.unlock_shared();
}
int increment() {
//写者, 获取独占锁, 使用unique_lock
std::lock_guard<std::shared_mutex> lck(mutex_);//执行mutex_.lock();
value_++; //lck 析构, 执行mutex_.unlock();
//std::cout << "writer #" << std::this_thread::get_id() ;
auto now = std::chrono::system_clock::now();
auto timestamp = std::chrono::duration_cast<std::chrono::microseconds>(now.time_since_epoch()).count();
//std::cout << timestamp << " set " << value_ << std::endl;
std::printf("time %ld set %d \n",timestamp,value_);
return value_;
}
void reset() {
//写者, 获取独占锁, 使用unique_lock
std::lock_guard<std::shared_mutex> lck(mutex_);//执行mutex_.lock();
value_ = 0; //lck 析构, 执行mutex_.unlock();
}
};
ThreadSaferCounter counter;
//每隔1s获取一次
void reader(int id){
while (true)
{
//std::this_thread::sleep_for(std::chrono::seconds(1));
//std::unique_lock<std::mutex> ulck(mtx);
//std::cout << "reader #" << id << " get value " << counter.get() << "\n";
std::this_thread::sleep_for(std::chrono::seconds(1));
counter.get();
}
}
//每隔一秒写入一次
void writer(int id){
while (true)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
//std::unique_lock<std::mutex> ulck(mtx);
//std::cout << "writer #" << id << " write value " << counter.increment() << "\n";
counter.increment();
}
}
int main()
{
std::thread rth[5];
std::thread wth[2];
for(int i=0; i<5; i++) {
rth[i] = std::thread(reader, i+1);
}
for(int i=0; i<2; i++) {
wth[i] = std::thread(writer, i+1);
}
for(int i=0; i<5; i++) {
rth[i].join();
}
for(int i=0; i<2; i++) {
wth[i].join();
}
return 0;
}
在终端中运行,你就会发现神奇的事情:
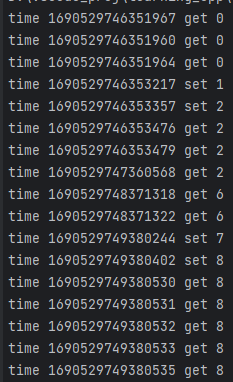
然后根据时间戳,你可以看到5个线程的get几乎是同时进行的,相差了大概不到10微秒,而get和set差了100到200多微秒,set之间也是独占的,所以也相差了100多微秒。这个例子很清晰的表示了共享和独占的特点。(为什么不用std::cout流输出呢,因为我发现流输出不是严格按照输出执行完才继续执行后面的代码,会导致多线程cout的时候,一行有多个输出结果。可能这也是为什么google风格的c++建议用printf,具体原因请大佬告知,后面去详细学习一下流输出的原理。)
四、std::condition_variable条件变量
用于满足条件后唤醒线程。比如,线程1执行某任务,线程2阻塞等待通知,不会占用cpu资源,满足一定条件线程1发送通知,线程2接收后继续执行代码,并执行锁。
condition_variable头文件有两个variable类,一个是condition_variable,另一个是condition_variable_any。condition_variable必须结合unique_lock使用。condition_variable_any可以使用任何的锁。
condition_variable条件变量可以阻塞(wait、wait_for、wait_until)调用的线程直到使用(notify_one或notify_all)通知恢复为止。condition_variable是一个类,这个类既有构造函数也有析构函数,使用时需要构造对应的condition_variable对象,调用对象相应的函数来实现上面的功能。
包含以下成员:
//等待
cv.wait(unique_lock);
cv.wait(unique_lock , [&a]{return a.s =="AAA";});//这里是还需要加个判断。如果为真,则启动。
// wait_for Wait for timeout or until notified
// wait_until Wait until notified or time point
//以上两个略了,就是等待一段时间和等待到一个时间点
cv.notify_one();
//解锁一个线程,如果有多个,则未知哪个线程执行
cv.notify_all();
//解锁所有线程
// cv_status 这是一个类,表示variable 的状态,如下所示
enum class cv_status { no_timeout, timeout };
示例和对比:(CPU intel i5-13400)
线程一不断向string中增加字母A,线程2检测到string为9900个的A之后重置string为B。
用condition_variable情况
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex
#include <condition_variable>
std::condition_variable cv;
class A{
public:
std::string s;
std::mutex mtx1;
};
void print_block1 (int n, char c , A& a) {
for (int i = 0; i < n; ++i) {
{
std::lock_guard<std::mutex> lock1(a.mtx1);
a.s += c;
std::cout << std::this_thread::get_id() << "," << a.s << std::endl;
}
//这样发送会有问题。可以减少到5,试一下,他会在A有6个时才重置为B。
//if(a.s == std::string(19990,'A')) {
cv.notify_one();
// std::this_thread::sleep_for(std::chrono::nanoseconds(1));
//}
}
}
void print_block2 (int n, char c, A& a) {
//while (true) {
std::unique_lock<std::mutex> lock1(a.mtx1);
cv.wait(lock1 , [&a]{return a.s ==std::string(19990,'A');});//用这个
//cv.wait(lock1);这个对应用if判断后notify的方法。
//if (a.s == std::string(19990,'A')) {
a.s = c;
std::cout << std::this_thread::get_id() << "," << a.s << std::endl;
// break;
//}
//}
}
int main ()
{
A a1;
auto t1 = std::chrono::system_clock::now();
std::thread th1 (print_block1,20000, 'A' , std::ref(a1));//线程1:打印*
std::thread th2 (print_block2,5, 'B' , std::ref(a1));//线程2:打印$
if(th1.joinable() && th2.joinable())
{
th1.join();
th2.join();
}
auto t2 = std::chrono::system_clock::now();
auto d = std::chrono::duration_cast<std::chrono::microseconds>(t2-t1);
std::cout << "spend time:" << d.count() << std::endl;
return 0;
}
循环判断的情况:线程2不断重复判断
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex
#include <condition_variable>
std::condition_variable cv;
class A{
public:
std::string s;
std::mutex mtx1;
};
void print_block1 (int n, char c , A& a) {
for (int i = 0; i < n; ++i) {
{
std::lock_guard<std::mutex> lock1(a.mtx1);
a.s += c;
std::cout << std::this_thread::get_id() << "," << a.s << std::endl;
}
}
}
void print_block2 (int n, char c, A& a) {
while (true) {
std::lock_guard<std::mutex> lock1(a.mtx1);
if (a.s == std::string(19990,'A')) {
a.s = c;
std::cout << std::this_thread::get_id() << "," << a.s << std::endl;
break;
}
}
}
int main ()
{
A a1;
auto t1 = std::chrono::system_clock::now();
std::thread th1 (print_block1,20000, 'A' , std::ref(a1));//线程1:打印*
std::thread th2 (print_block2,5, 'B' , std::ref(a1));//线程2:打印$
if(th1.joinable() && th2.joinable())
{
th1.join();
th2.join();
}
auto t2 = std::chrono::system_clock::now();
auto d = std::chrono::duration_cast<std::chrono::microseconds>(t2-t1);
std::cout << "spend time:" << d.count() << std::endl;
return 0;
}
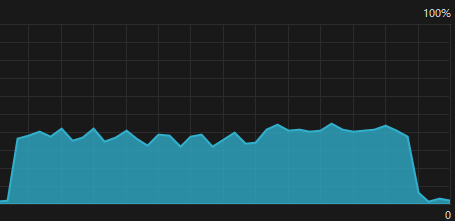
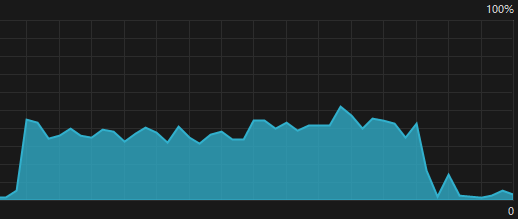


CPU情况,前者使用条件变量,后者使用循环判断。感觉两者在CPU占用上差不多,时间上使用条件变量略快一点点。我以为线程2阻塞等待时会不占用cpu资源,更节省资源才对。
这里面遇到了一个问题:
1、线程1先判断满足条件后notify_one,线程2cv.wait(lck);这种情况下会导致线程2执行时慢一拍,导致输出错误,需要线程1notify_one以后等待1纳秒。但是这样就会导致用条件变量的时间变得波动很大,耗时很长。
2、线程1每次循环都notify_one,线程2去判断cv.wait(lock1 , [&a]{return a.s == std::string(5,'A');}); 这种情况下比较正常和稳定,个人理解更推荐这样使用。
五、原子操作
下次更新