《汇编程序设计与计算机体系结构: 软件工程师教程》这本书是由Brain R.Hall和Kevin J.Slonka著,由爱飞翔译。中文版是2019年出版的。个人感觉这本书真不错,书中介绍了三种汇编器GAS、NASM、MASM异同,全部示例代码都放在了GitHub上,包括x86和x86_64,并且给出了较多的网络参考资料链接。这里只摘记了NASM和MASM,测试代码仅支持Windows和Linux的x86_64。
6. 函数
6.2 栈内存入门:栈内存(stack memory)是为自动变量而设的一块区域(这里的自动变量是指局部变量,或者说非动态的变量)。调用函数的时候,需要用栈来保存函数中的局部变量,而函数结束的时候,则需要弃用这些变量。高级语言的一项特征在于它会自行管理栈内存(这有时也叫做运行时栈或运行期栈),相反,汇编语言不会这样做,而是需要你自己去管理。
与栈内存有关的重要事项:
(1).栈会在调用函数时增长,并在调用结束时收缩。
(2).栈会在创建(或者说推入/压入)局部变量时增长,并在弃用(或者说弹出)局部变量时收缩。
(3).每个进程或线程的栈,其大小受操作系统限制,例如Linux/Mac系统默认是8MB,Windows默认是1MB。
(4).每次调用函数(这也包括调用主函数main(),以及递归地调用自身)都会出现对应的栈帧(stack frame)。它是栈内存中的一块区域,随着函数调用而产生。
(5).栈帧用来保存函数的局部变量。
(6).栈内存是向下增长的,也就是说,推入栈中的新内容会出现在地址值较低的位置中。
(7).32位环境下,栈中的每个元素占据4个字节,64位环境下占据8个字节。
(8).数值默认按照小端序入栈。权重最高的字节保存到地址最高的位置上,权重较低的字节保存到地址最低的位置上。
(9).x86_64的函数都必须按16字节对齐(所有平台都是这样)。
6.3 x86与x86_64的调用约定:
调用约定也叫做调用协议,用来确定函数在底层的实现流程,包括如何传递参数、如何管理栈内存,以及如何返回值。
cdecl(32位):cdecl(C declaration)调用约定是32位平台最常见的一种约定,因为它是基于C语言标准而设立的。一般来说,GCC、Clang与Visual Studio的C编译器默认都会使用cdecl约定。有些开发环境(如Visual Studio)允许开发者在项目属性中调整默认的约定方式。cdecl有4项主要特征:
(1).参数按照相反的顺序(也就是从右到左的顺序)入栈。
(2).eax、ecx与edx需要由调用方(caller, 主调方)保存(叫做易失性的寄存器),而其余的通用寄存器则需要由受调方(callee, 被调用方)来保存(叫做非易失性的寄存器)。因此,如果想令eax、ecx及edx寄存器在调用完函数之后还能保持调用之前的值,那么应该在主调函数中先将其保存起来,因为受调函数在执行过程中有可能会修改它们。
(3).在大多数情况下,返回值放在eax寄存器里,如果要返回的是浮点数,那么应该放在st(0)寄存器里。
(4).栈由调用方负责清理。
C语言支持参数数量可变的函数。由于这种函数的参数列表长度不固定,因此,受调方并不清楚自己到底接收了几个参数。于是,就要求栈必须由主调方来清理,而且每次调用的时候都得清理。C语言里的printf()就属于这样的函数。
在32位环境与64位环境下引用局部变量可以采用不同的办法。32位环境下,一般用ebp作为基准点来访问参数,而64位环境下则不太这样使用。其原因有三:第一,64位环境下通常使用寄存器(而不是栈)来传递参数;第二,64位环境下可以使用RIP相对寻址机制;第三,64位环境下,系统默认在栈内存中划分一块暂存空间,使我们可以直接以rsp寄存器为基准来引用局部变量。
stdcall(32位):被Windows API使用,一般来说,它的规则与cdecl是相同的,只是在一个地方有所区别(第4项):
(1).参数按照相反的顺序(也就是从右到左的顺序)入栈。
(2).eax、ecx与edx应该由调用方保存,而其余的通用寄存器则应该由受调方来保存。
(3).在大多数情况下,返回值放在eax寄存器里,如果要返回的是浮点数,那么应该放在st(0)寄存器里。
(4).栈由受调方负责清理。
stdcall的好处是,受调函数可以在运行RET(返回)指令的时候顺便把栈清理干净,从而使主调函数可以少写一些代码。由于清理栈所用的代码是写在受调函数中的,因此,每次调用这个函数时,这些代码都能得到执行,而不用在主调函数里重复一遍。栈能够由受调方清理,是因为stdcall不允许参数个数可变的函数,因此,受调方可以知道自己接收了几个参数,从而正确地把栈清理干净。stdcall的RET指令与cdecl稍有不同,它必须指出栈中有多少个字节的内容需要移除。
x86_64(64位):约定试图提升函数的执行速度,它允许程序通过寄存器来传递某些参数,而不一定非要通过栈来做(这与32位模式下的fastcall约定是类似的,fastcall也是一种可以通过寄存器来传递数值的约定方式,它运用在32位环境中)。下表指出了两种64位的函数调用约定所具备的特征:在这两种情况下(Microsoft x64, System V AMD64(AMD64)),如果要传递的参数比参数寄存器的数量还多,那么其余的参数依然遵循从右至左的顺序入栈。

64位模式下的函数必须按16字节对齐。x86_64支持流式SIMD扩展(Streaming SIMD Extensions, SSE),这是一套有助于并行处理的指令。SSE的操作一般都是128位的,SSE操作必须按16字节对齐。为了确保使用SSE指令的函数不会出现栈对齐错误,所有的栈帧都应该向16字节处对齐。此外,由于CALL指令默认会把8个字节的地址推入栈中,因此,在很多情况下,我们都需要再向栈中推入8字节,从而实现16字节对齐。
x86_64调用约定还有一个重要特征,就是在栈中预留额外的空间。Microsoft x64约定所预留的空间,叫做shadow space或home space,其长度是32个字节,用来放置参数寄存器中的数值。即便不需要传递任何参数,也依然得预留这么大的空间。如果受调函数经由r8、r9、rcx及rdx寄存器收到的参数还要在该函数调用其它函数的时候用到,那么这些参数的值就可以在shadow space中保存一份,除此之外,这块暂存空间(scratch space)也可以用来做其它的事情。
AMD64调用约定没有32个字节的shadow space这一概念,但它会把存放返回地址所用的位置(rsp就指向此处)下方的128个字节视为red-zone。这是打算留给函数使用的一块临时存储空间,不会被系统侵扰。如果没有PUSH、POP或CALL指令涉及这块区域,那么rsp就不会改变,于是,开发者可以通过rsp来引用局部变量及标识符(例如在实现跳转和循环的时候,就可以这样引用相关的标识符)。预留这块区域是为了令rsp寄存器不会因局部变量而频繁地调整,进而节省时钟周期,以求优化程序的执行效率。此外,它还可以用来实现末端函数(leaf function, 叶函数),也就是那种不会再继续调用其它函数的函数。主调方可以利用red-zone来完成未端函数所要执行的计算,这样就不用再通过CALL指令真的去调用它了,从而可以免去一些开销。与Microsoft x64的shadow space不同,AMD 64的red-zone并不需要由开发者或编译器专门去预留,它仅仅用来表达一项承诺,意思是说:系统信号及中断处理程序是不会触碰rsp下方那128个字节的。但是,如果调用了其它函数,那么主调函数的red-zone就会遭到破坏,因此,这块区域主要还是留给那些不会再调用其它函数的末端函数来用的,那些函数可以把它当做暂存空间。
6.7 重要的寄存器(32位和64位)及命令,如下表所示:

6.9 与平台有关的注意事项:
(1).在Windows系统中编写代码时,应该用PROC与ENDP命令指出例程的起点与终点。
(2).在Windows系统中编写MASM汇编代码时,可以通过.MODEL命令指出整个程序所遵循的调用约定(例如C或STDCALL),也可以在每个函数的PROC右侧专门指出该函数所遵循的调用约定,以便更为精细地控制程序。
(3).在Windows系统中编写MASM汇编代码时,可以通过USES命令指出一些寄存器,使得汇编器为它们生成相应的PUSH或POP指令。这些指令会自动出现在函数的开场与收场部分,从而能够在程序进入及退出该例程时得到执行(这些写法对于32位及64位模式都适用)。
7. 与字符串有关的指令及结构体
7.2 辅助指令:
下表列出了两条方向指令,分别用来给方向标志(direction flag)清零及置位。方向标志决定了内存地址在执行字符串指令的过程中是应该自动递增还是自动递减,这实际上也就决定了字符串的处理顺序是从左至右还是从右至左。CLD与STD指令最适合用在重复操作之前,以便将方向标志调整好。

字符串的重复操作是通过重复指令实现的,下表列出了三种形式的REP(repeat)指令,它们都采用C系列的寄存器做计数器。
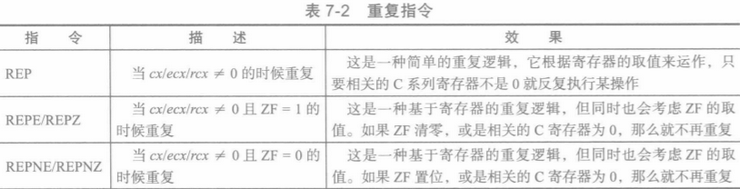
把调整方向标志的指令与重复指令结合起来,就能够自动处理字符串数据而不用手工编写循环。下面是重复指令运作方式的步骤:
(1).重复指令要判断相关的C系列寄存器是否大于0,如果已经等于0就不再重复。若是比0大则继续重复。
(2).执行字符串指令,根据结果设定相关的标志,并根据具体的指令与方向标志来递增或递减si/esi/rsi及di/edi/rdi。
(3).如果这条重复指令是REPE/REPNE或REPZ/REPNZ,就根据ZF标志来判断是否应该继续重复。如果不应该就不再重复。
(4).如果第2步(对于另外两种形式来说是第2与第3步)顺利执行,那就将相关的C系列寄存器减1并回到第1步。
7.3 基本字符串指令:5种处理字符串数据的指令,如下表所示:这些字符串指令都会根据方向标志(也就是DF)的取值,给si/esi/rsi及di/edi/rdi加上或减去一定的字节数,使得程序能够按照开发者预想的方向来处理数组。即便不与REP搭配,这些字符串指令也依然会执行递增或递减运算。

MOVS(move string, 移动字符串):与MOV指令类似,但是有两个区别,第一,它的源操作数与目标操作数不需要写在指令中,而是默认由esi及edi等寄存器来表示。第二,所有的汇编器都要求在该指令后面写上一个与元素大小相对应的后缀字母。si/esi/rsi寄存器指向待复制的数据所在的内存位置,di/edi/rdi寄存器指向目标地址。在与REP相搭配用以连续复制多个字符的过程中,为了使下一次复制操作能够找到正确的字符,开发者必须指出每个字符所占据的字节数,从而令MOVS可以根据DF标志适当地递增或递减相应的寄存器。由于字符串指令每次所操作的数据可能是1、2、4、8或16个字节,则字符串指令所添加的后缀依次为B(byte)、W(word)、D(dword)、Q(qword)、O(octa)。
CMPS(compare string, 比较字符串):指令与CMP指令相似,但是它与MOVS一样也不带操作数,而是默认会通过si/esi/rsi及di/edi/rdi来确定有待比较的数据所在的内存地址,而且它也像MOVS那样最好是能够与重复指令结合起来使用。如果不搭配重复指令,而是单独使用这条指令,那么只能比较一个字符而不是整个字符串。把重复指令与MOVS相搭配,可以按序复制字符,但若与CMPS相搭配则是按序访问字符。为了对比两个字符串,CMPS指令必须从一个字符移动到下一个字符,然而它在移动的同时还需要判断:当前字符与另一个字符串里的对应字符是否相同。与CMPS搭配的重复指令是REPE/REPZ或REPNE/REPNZ。以REPE/REPZ为例,只有当两个字符串的对应字符相等时才会继续比较下一个字符(因为只有在这种情况下CMPS指令才会把ZF标志设置成1,从而使重复指令能够继续执行)。CMPS通过减法比较这两个字符,也就是把由si/esi/rsi所表示的字符从由di/edi/rdi所表示的字符值中减去,并根据结果修改相关的处理器标志,尤其是ZF标志。REPE与PEPZ是同一个意思,因为它们执行相同的判断逻辑。REPNE与REPNZ两者之间也是如此。CMPS指令最基础的用法是单独以CMPS+后缀的格式使用。
SCAS(scan string, 扫描字符串):实际上是在执行内置的顺序搜索算法,该算法在搜寻字符串的过程中查找的是单个字符。SCAS的正常流程是对di/edi/rdi所指的字符串做迭代,以便在其中寻找与al/ax/eax/rax里的目标字符相同的字符,如果能找到就提取退出,与它相搭配的是REPNE或REPNZ指令。与CMPS相搭配时,REPE/REPZ指令不会在CMPS失败的时候递减cx/ecx/rcx寄存器。与SCAS相搭配时,REPNE/REPNZ指令总是会递减cx/ecx/rcx寄存器,而不考虑SCAS指令是成功还是失败。SCAS指令最基础的用法是单独以SCAS+后缀的形式使用。
STOS(store string, 存储字符串):很适合用来初始化数组。它会把累加寄存器里的值复制到由di/edi/rdi寄存器所表示的内存位置上。如果有多个位置(例如整个数组)都需要用这个值来初始化,那么可以将其与REP结合起来使用。STOS无法用不同的值来初始化数组中的不同元素,它只能将同一个值复制到数组中的每一个位置上。STOS指令最基础的用法是单独以STOS+后缀的形式使用。
LODS(load string, 加载字符串):与STOS相反,它不是把值从累加寄存器复制到di/edi/rdi所表示的地址上,而是从si/esi/rsi所指的地址上取值并将其复制到累加寄存器中。与STOS不同,这条指令一般不与重复指令相结合,因此那样做会导致累加寄存器频繁遭到覆写。LODS指令最基础的形式是LODS+后缀。
7.4 结构体:是复合的数据类型,与高级语言类似,汇编语言中的结构体也是由用户所定义的数据类型,能够包含多个字段,这些字段的数据类型可以互不相同。数组中的所有元素都必须一样大,而结构体中的每个元素大小则未必相同。没有能把整个结构体所占据的字节数告诉编译器的命令,因此,它需要知道结构体的起始位置及结束位置。知道了这两个位置,NASM就可以据此推断出结构体的总尺寸,这就好比知道了当前位置计数器与数组的起始位置我们就可以用EQU来确定数组长度。
由于结构体不是内置的数据类型,因此必须先把它定义出来,然后才能声明这种结构体的实例。结构体必须定义在code与data段之外,也就是称为absolute段的地方,或者也可以定义在另一份文件中并通过INCLUDE命令将其包含进来。这两种写法可以确保结构体在实例化之前已经具备适当的定义。结构体定义、声明及使用范例如下表所示:有的时候必须通过.ALIGN、.ALIGNB等对齐命令来确保结构体及其成员能够对齐到适当的内存边界处。

8. 浮点运算
8.2 浮点数的表示方式:计算机中的浮点值(floating-point value)是一种用来近似表示实数的数据形式,这种值的小数点前后通常都有一些数位。浮点数由有效数(significand)、基数与指数三部分组成,其中的有效数部分可以容纳固定个数的有效数位,而基数则用来与指数相配合,以便对有效数放大或缩小。所谓浮点是指有效数部分只中的小数点能够左右移动,只要相应地调整基数的指数,就能保持整个值不变。
IEEE表示法:1985年,电气电子工程师协会发布了IEEE 754技术标准,用以规范浮点数的计算。这份标准在2008年更新为IEEE 754-2008标准。下表列出了几种常见的IEEE浮点数格式,其中最常用的是单精度、双精度与扩展双精度格式。四倍精度虽然也定义在IEEE标准中,但是一般的硬件都不支持。

下表演示了把78.375转换成IEEE 754单精度格式的过程:

特殊值:这些值包括带符号的0、无穷,以及NaN(Not-a-Number, 非数)。下表以十六进制形式列出了这些特殊的值:NaN是一种用来表示未定义值或假想值的数据。

次正规数(subnormal number):也叫做非正规数(denormalized number),它们可以表示正规范围以外的值。
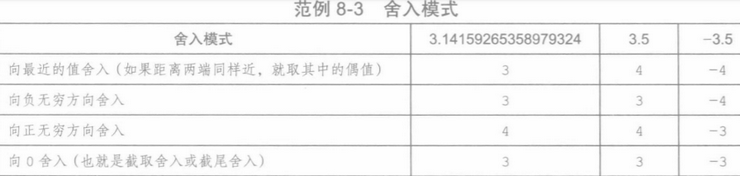
舍入:舍入模式如下表所示:用浮点值做运算或者在不同的浮点格式之间转换时,需要考虑舍入方法。大多数系统的默认舍入方法是向最近的值舍入(round to nearest)。
8.3 浮点数的实现:为了支持浮点数,Intel开发了8087及80386辅助处理器用以充当FPU(floating point unit, 浮点运算单元),从而与CPU协同运作。这些FPU实现了名为x87的指令集架构。从80486/487开始,FPU集成到了CPU中。
x87:定义了自己的一套指令、寄存器及浮点数格式以执行浮点运算。下表列出了x87寄存器:

浮点运算的通用寄存器是R0至R7这八个寄存器。系统每执行完一条FPU指令就会把该指令的内存地址放入Last Instruction Pointer中,如果该指令还带有操作数,那么操作数的内存地址会放在Last Data Pointer中,如下表所示。把刚刚执行过的那条指令及其操作数所处的内存地址记录下来,是为了给异常处理程序提供状态信息。

状态寄存器用来保存FPU的当前状态,如下表所示:其中11至13号这三位合称TOP,用来表示栈顶(top-of-stack)。FPU的8个数据寄存器(R0至R7)形成循环栈,其中任何一个寄存器都有可能充当栈顶。如果向R0推入一个值,那么下一个值就会推入R7中。从栈中删除元素时也会出现这样的循环现象,只不过方向与推入元素时相反。为了利用这种特性,开发者并不直接以R0至R7这样的名称来指代寄存器,而是以ST0至ST7等写法来指代它们,哪个R寄存器充当栈顶就把哪个R寄存器叫做ST0.这个R寄存器在整个R系列中的序号保存在FPU状态寄存器的TOP字段中。

状态寄存器中的各个二进制,其含义如下:
(1).FPU busy(15号位):当FPU正在执行某条指令时,该位会设置成1.
(2).Condition codes(8至10号位,以及14号位):用来表示浮点算术的结果。
(3).TOP(11至13号位):用来表示目前充当栈顶的R寄存器是第几个R寄存器。
(4).Error Status(7号位):如果正在处理FPU异常,那么该位的值是1.
(5).Stack Fault(6号位):如果置位,那么意味着FPU栈发生了上溢或下溢(试图把数据加载到本身已经具备有效数值的寄存器中,或者试图从已经不含有效数值的寄存器里获取数据)。
(6).Exceptions(0至5号位):P位表示precision(精度受损),U位表示underflow(下溢),O位表示overflow(上溢),Z位表示zero divide(除以0),D位表示denormalized operand(非正规的操作数),I位表示invalid operation(无效操作)。其中,P、U、O三种异常,有可能发生在执行完某项操作之后,而Z、D、I这三种异常则有可能发生在即将执行某项操作之前。
下表描述了FPU的控制寄存器(Control Register),其中有一些二进制位用来控制无穷、舍入以及精度等几个方面,还有一些二进制位充当异常掩码。每一个掩码位都对应于状态寄存器中相应异常位。执行完FPU初始化(FPU initialization, FINIT)指令之后,所有的掩码位都会默认设置成1,这意味着所有的浮点异常都交由FPU处理。如果开发者把某个掩码位设置为0,那么发生相应的浮点异常时系统就会产生中断,从而把异常交给程序来处理。6、7、13、14及15号位是保留位,或者说暂时没有用到的二进制位。12号位叫做infinity control位,当今的x87处理器已经不使用这一位了。每一个异常掩码位所控制的异常:PM控制precisioon(精度受损),UM控制underflow(下溢),OM控制overflow(上溢),ZM控制zero divide(除以0),DM控制denormalized operand(非正规的操作数),IM控制invalid operation(无效操作)。

x87 FPU接受7种格式的数字:单精度、双精度、扩展双精度、单字整数、双字整数、四字整数,以及压缩的BCD整数(packed BCD integer, 其中BCD的意思是binary coded decimal,也就是用二进制码来表示的十进制数)。
值加载到FPU的时候默认会转换成扩展双精度格式(该格式所占据的二进制位个数为80),这样可以令精确程度最高。如果要把这样的值存入内存,可以沿用扩展双精度格式,也可以转换为更为短小的格式。控制寄存器里的精度控制(PC)字段能够控制格式。扩展双精度与压缩BCD这两种格式的支持情况在各平台及汇编器之间可能有所不同。
x87 FPU采用后缀表示法(postfix notation)来做计算(这和某些计数器是一样的)。比方说,做加法的时候是先把有待相加的两个操作数推入栈中,然后再处理它们之间的加法。
x87的FPU指令以字母F开头。第二个字母如果是B或I,意味着内存操作数应该解读为压缩的BCD格式或整数格式,若不是这两种字母则应解读为浮点数格式。
MASM要求栈寄存器的序号必须用一对圆括号括起来,而NASM则不要求写出这对括号。
x87 FPU中还有两个寄存器也用来保存与FPU有关的信息。其中一个是Tag Register(标记寄存器),它用来表示FPU数据寄存器(也就是R0至R7这8个寄存器)中存放的是何种内容。有了Tag Register,开发者就可以先判断相关寄存器中的内容是否合适,然后再去执行更为复杂的指令或解码任务。FSTENV/FNSTENV或FSAVE/FNASVE指令可以把FPU的Tag Register存储到内存中。软件不能直接修改该寄存器。与某个R寄存器相对应的tag字段如果是00,那么表示该R寄存器中是个有效的非零值。如果是01则表示其内容是0或与0等价的值。如果是10则表示其内容是NaN、inf(无穷)、-inf(负无穷)或非正规数等特殊值。如果是11则表示该R寄存器是空的。FINIT指令或弹出指令会把Tag Register中相应字段标为empty。
另外一个是Opcode Register(操作码寄存器),它用来存放最近执行的那条非控制指令。
MMX:本身并非用于浮点数计算,而是通过FPU寄存器来操作整数。Intel在1996年发布P55C(80503)处理器时引入了这项技术。MMX处理器配有8个可用于整数运算的64位寄存器以及47条指令。这8个64位寄存器分别用MM0至MM7来表示,它们其实是80位FPU数据寄存器R0至R7中有效数那一部分的别名。
MMX技术有两大特性,一个是压缩的整数型数据(packed integer data),另一个是单指令流多数据流(Single Instruction Multiple Data, SIMD)。64位的MMX寄存器可以存放压缩形式的字节、字及双字。
向MMX寄存器中移入数据或是将MMX寄存器中的数据移出,依然要按照普通的方式来做,或者要以四字(也就是64个二进制位)为单位来做,不过,保存在寄存器中的这些压缩数据,却可以在同一时间分别参与各自的算术运算。像这种通过一条指令并行地操作多个数据点的理念称为SIMD模型。
虽然MMX与FPU指令操作的是同一套寄存器,但这两种指令其实可以用在同一个程序中,只不过这样做会产生一些开销。
SSE(Streaming SIMD Extensions, 流式SIMD扩展):构建在MMX技术之上。MMX所处理的数据需要以压缩的整数形式保存在64位寄存器中,而SSE所处理的浮点数据则既可以用压缩的形式保存又可以直接用标量的形式保存,而且是保存在128位寄存器中的。请注意,凡是提到压缩形式的数据,就意味着这些数据能够在程序运行过程中并行地得到处理。
SSE指令可以分成四大类:用于操作压缩浮点数及标量浮点数的指令;SIMD整数指令;状态管理指令;缓存控制指令、用来对指令的执行顺序/内存的操作顺序做出安排的指令。
可以在32位模式下使用的128位SSE寄存器是xmm0至xmm7 8个XMM寄存器。在64位模式下还可以再使用8个寄存器,也就是xmm8至xmm15。必须注意,在兼容SSE的处理器中,这些寄存器并不是其它寄存器的别名而是单独的寄存器。XMM寄存器只能存放数据不能用来存放地址。
SSE还有一个32位的控制及状态寄存器叫做MXCSR,它与x87的控制寄存器及状态寄存器类似。MXCSR包含一些与浮点异常及舍入控制有关的标志与掩码,还有各种用来控制SIMD操作的标志。
SSE只支持一种数据类型即单精度的浮点数。SSE2支持更多的数据类型,其中包括双精度浮点数、四字整数、双字整数、单字整数(也称为短整数,short)、字节整数。SSE的标量指令仅适用XMM寄存器中最低的双字或四字部分来执行浮点运算。大多数SSE指令都有两种形式,一种针对标量形式的数据,另一种针对压缩形式的数据。目前的大多数C++编译器都采用标量形式的SSE指令计算浮点数,而不会自动采用压缩形式的SSE指令来并行地执行多项计算。Intel的C++编译器是个例外。
对于MMX、SSE及SSE2技术来说,所有的算术与比较运算都可以在寄存器所压缩的各项数据之间并行地执行。SSE3除了能像早前的技术那样同时给某一对寄存器内的多份数据执行计算之外,还能在不同的寄存器上同时执行各自的运算,并把运算结果汇总到目标寄存器的相应部分中。
AVX(Advanced Vector Extensions, 高级向量扩展):能够向后兼容SSE。出现了三套高级扩展指令,它们分别是:AVX指令集、AVX2指令集以及AVX-512指令集。这些扩展指令集较大地提升了寄存器的容量,并使得开发者能够运用更多的指令来编写程序。
Windows下链接汇编代码及C++代码操作步骤(x64):
(1).创建一个Win32控制台应用程序AssemblyLanguage_Test,并将其调整为x64;
(2).添加几个新文件,AssemblyLanguage_Test.cpp里面主要包含main函数;funset.asm里面包含了一些汇编代码;
(3).通过ml64.exe对funset.asm做汇编,产生目标文件funset.obj:
A.在C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\amd64目录下启动cmd.exe;
B.运行vcvars64.bat或者直接将vcvars64.bat直接拖到cmd中;
C.定位到E:\GitCode\CUDA_Test\demo\AssemblyLanguage_Test\masm,执行:$ ml64.exe /c /Cx funset.asm,将会生成funset.obj,执行结果如下图所示:

(4).将funset.obj添加到工程中;
(5).生成并运行程序。
如果修改了funset.asm,那么必须通过ml64.exe重新生成funset.obj。
Ubuntu下链接汇编代码及C++代码操作步骤(x64):
(1).添加几个新文件,AssemblyLanguage_Test.cpp里面主要包含main函数;funset.asm里面包含了一些汇编代码;
(2).build.sh内容如下:
#! /bin/bash
real_path=$(realpath $0)
echo "real_path: ${real_path}"
dir_name=`dirname "${real_path}"`
echo "dir_name: ${dir_name}"
new_dir_name=${dir_name}/build
if [[ -d ${new_dir_name} ]]; then
echo "directory already exists: ${new_dir_name}"
else
echo "directory does not exist: ${new_dir_name}, need to create"
mkdir -p ${new_dir_name}
fi
rc=$?
if [[ ${rc} != 0 ]]; then
echo "########## Error: some of thess commands have errors above, please check"
exit ${rc}
fi
cd ${new_dir_name}
cmake ..
make
cd -
(3).CMakeLists.txt内容如下:
PROJECT(AssemblyLanguage_Test)
CMAKE_MINIMUM_REQUIRED(VERSION 3.0)
# support C++11
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -std=c11")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
# support C++14, when gcc version > 5.1, use -std=c++14 instead of c++1y
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++1y")
IF(NOT CMAKE_BUILD_TYPE)
SET(CMAKE_BUILD_TYPE "Release")
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wall -O2")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -O2")
ELSE()
SET(CMAKE_BUILD_TYPE "Debug")
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -g -Wall -O2")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -Wall -O2")
ENDIF()
MESSAGE(STATUS "cmake build type: ${CMAKE_BUILD_TYPE}")
MESSAGE(STATUS "cmake current source dir: ${CMAKE_CURRENT_SOURCE_DIR}")
SET(PATH_TEST_CPP_FILES ${CMAKE_CURRENT_SOURCE_DIR}/./../../demo/AssemblyLanguage_Test)
SET(PATH_TEST_NASM_FILES ${CMAKE_CURRENT_SOURCE_DIR}/./../../demo/AssemblyLanguage_Test/nasm)
MESSAGE(STATUS "path test files: ${PATH_TEST_CPP_FILES} ${PATH_TEST_NASM_FILES}")
# head file search path
INCLUDE_DIRECTORIES(${PATH_TEST_CPP_FILES})
FILE(GLOB TEST_CPP_LIST ${PATH_TEST_CPP_FILES}/*.cpp)
FILE(GLOB TEST_CPP2_LIST ${PATH_TEST_CPP_FILES}/nasm/*.cpp)
MESSAGE(STATUS "test cpp list: ${TEST_CPP_LIST} ${TEST_CPP2_LIST}")
FILE(GLOB_RECURSE TEST_NASM_LIST ${PATH_TEST_NASM_FILES}/*.asm)
MESSAGE(STATUS "test nasm list: ${TEST_NASM_LIST}")
# build nasm
SET(CMAKE_ASM_NASM_FLAGS_DEBUG_INIT "-g")
SET(CMAKE_ASM_NASM_FLAGS_RELWITHDEBINFO_INIT "-g")
IF(NOT DEFINED CMAKE_ASM_NASM_COMPILER AND DEFINED ENV{ASM_NASM})
SET(CMAKE_ASM_NASM_COMPILER $ENV{ASM_NASM})
ENDIF()
ENABLE_LANGUAGE(ASM_NASM)
MESSAGE(STATUS "CMAKE_ASM_NASM_COMPILER = ${CMAKE_ASM_NASM_COMPILER}")
IF(CMAKE_ASM_NASM_OBJECT_FORMAT MATCHES "elf*")
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -DELF")
SET(CMAKE_ASM_NASM_DEBUG_FORMAT "dwarf2")
ENDIF()
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -D__x86_64__")
MESSAGE(STATUS "CMAKE_ASM_NASM_OBJECT_FORMAT = ${CMAKE_ASM_NASM_OBJECT_FORMAT}")
IF(NOT CMAKE_ASM_NASM_OBJECT_FORMAT)
MESSAGE(FATAL_ERROR "could not determine NASM object format")
return()
ENDIF()
get_filename_component(CMAKE_ASM_NASM_COMPILER_TYPE "${CMAKE_ASM_NASM_COMPILER}" NAME_WE)
MESSAGE(STATUS "CMAKE_ASM_NASM_COMPILER_TYPE = ${CMAKE_ASM_NASM_COMPILER_TYPE}")
IF(NOT WIN32 AND (CMAKE_POSITION_INDEPENDENT_CODE OR ENABLE_SHARED))
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -DPIC")
ENDIF()
ADD_LIBRARY(simd OBJECT ${TEST_NASM_LIST})
IF(NOT WIN32 AND (CMAKE_POSITION_INDEPENDENT_CODE OR ENABLE_SHARED))
set_target_properties(simd PROPERTIES POSITION_INDEPENDENT_CODE 1)
ENDIF()
# build executable program
ADD_EXECUTABLE(AssemblyLanguage_Test ${TEST_CPP_LIST} ${TEST_CPP2_LIST})
TARGET_LINK_LIBRARIES(AssemblyLanguage_Test simd)
(4).执行:$ ./build.sh; ./build/AssemblyLanguage_Test
GitHub:https://github.com/fengbingchun/CUDA_Test