rocketMq介绍和安装
Mq介绍
MQ:MessageQueue,消息队列。 队列,是一种FIFO 先进先出的数据结构。消息由生产者发送到MQ进行排队,然后按原来的顺序交由消息的消费者进行处理。
QQ和微信就是典型的MQ。
MQ的作用
主要有以下三个方面:
异步
例子:快递员发快递,直接到客户家效率会很低。引入菜鸟驿站后,快递员只需
要把快递放到菜鸟驿站,就可以继续发其他快递去了。客户再按自己的时间安排
去菜鸟驿站取快递。
作用:异步能提高系统的响应速度、吞吐量。
解耦
例子:《Thinking in JAVA》很经典,但是都是英文,我们看不懂,所以需要编
辑社,将文章翻译成其他语言,这样就可以完成英语与其他语言的交流。作用:
1、服务之间进行解耦,才可以减少服务之间的影响。提高系统整体的稳定性以
及可扩展性。
2、另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者
多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
削峰
例子:长江每年都会涨水,但是下游出水口的速度是基本稳定的,所以会涨水。
引入三峡大坝后,可以把水储存起来,下游慢慢排水。
作用:以稳定的系统资源应对突发的流量冲击。
MQ的缺点
上面MQ的所用也就是使用MQ的优点。 但是引入MQ也是有他的缺点的:
系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦MQ宕机,对业务会产生影
响。这就需要考虑如何保证MQ的高可用。
系统复杂度提高
引入MQ后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入
MQ后,会变为异步调用,数据的链路就会变得更复杂。并且还会带来其他一些问
题。比如:如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问
题。
消息一致性问题
A系统处理完业务,通过MQ发送消息给B、C系统进行后续的业务处理。如果B系统
处理成功,C系统处理失败怎么办?这就需要考虑如何保证消息数据处理的一致性。
几大MQ产品特点比较
常用的MQ产品包括Kafka、RabbitMQ和RocketMQ。我们对这三个产品做下简单的比较,重点需要理解他们的适用场景。
这里有rocketMq官网的对比链接:https://rocketmq.apache.org/zh/docs/#rocketmq-vs-activemq-vs-kafka
|
优点 |
缺点 |
使用场景 |
| kafka |
kafka吞吐量非常大,性能非常好。集群高可用。 |
会丢数据,功能比较单一。 |
日志分析。 |
| rabbitMq |
大数据采集RabbitMQ消息可靠性高,功能全面。 |
吞吐量比较低,消息积累会影响性能,erlang语言不好定制。 |
小规模场景 |
| rocketMq |
RocketMQ高吞吐,高性能,高可用。功能全面。 |
开源版功能不如云上版,官方文档比较简单 |
几乎全场景 |
rocketMq介绍
官网地址:https://rocketmq.apache.org/zh/
github : https://github.com/apache/rocketmq https://github.com/apache/rocketmq-externals
NameServer:http://www.tianshouzhi.com/api/tutorials/rocketmq/408
RocketMQ是阿里巴巴开源的一个消息中间件,基于java开发,在阿里内部历经了双十一等很多高并发场景的考验,能够处理亿万级别的消息。2016年开源后捐赠给Apache,现在是Apache的一个顶级项目。目前RocketMQ在阿里云上有一个购买即可用的商业版本,商业版本集成了阿里内部一些更深层次的功能及运维定制。我们这里学习的是Apache的开源版本。开源版本相对于阿里云上的商业版本,功能上略有缺失,但是大体上功能是一样的。
1.1、RocketMQ的发展历程
早期阿里使用ActiveMQ,但是,当消息开始逐渐增多后,ActiveMQ的IO性能很快达到了瓶颈。于是,阿里开始关注Kafka。但是Kafka是针对日志收集场景设计的,他的并发性能并不是很理想。尤其当他的Topic过多时,由于Partition文件也会过多,会严重影响IO性能。于是阿里才决定自研中间件,最早叫做MetaQ,后来改名成为RocketMQ。最早他所希望解决的最大问题就是多Topic下的IO性能压力。但是产品在阿里内部的不断改进,RocketMQ开始体现出一些不一样的优势。
1.2、RocketMQ产品特点比较
RocketMQ的消息吞吐量虽然依然不如Kafka,但是却比RabbitMQ高很多。在阿里内部,RocketMQ集群每天处理的请求数超过5万亿次,支持的核心应用超过3000个。RocketMQ天生就为金融互联网而生,因此他的消息可靠性相比Kafka也有了很大的提升,而消息吞吐量相比RabbitMQ也有很大的提升。另外,RocketMQ的高级功能也越来越全面,广播消费、延迟队列、死信队列等等高级功能一应俱全,甚至某些业务功能比如事务消息,已经呈现出领先潮流的趋势。RocketMQ的源码是用Java开发的,这也使得很多互联网公司可以根据自己的业务需求做深度定制。而RocketMQ经过阿里双十一多次考验,源码的稳定性是值得信赖的,这使得功能定制有一个非常高的起点。 传统意义上,RocketMQ有一个比较大的局限,就是他的客户端只支持Java语言。但RocketMQ作为一个开源软件,自身产品不断成熟的同时,周边的技术生态也需要不断演进。RocketMQ成为Apache顶级项目后,又继续通过社区开发出了很多与主流技术生态融合的周边产品。例如在RocketMQ的社区,也正在开发GO,Python,Nodejs等语言的客户端。\
rocketMq重要变化
官方文档:https://rocketmq.apache.org/zh/docs/deploymentOperations/15deploy
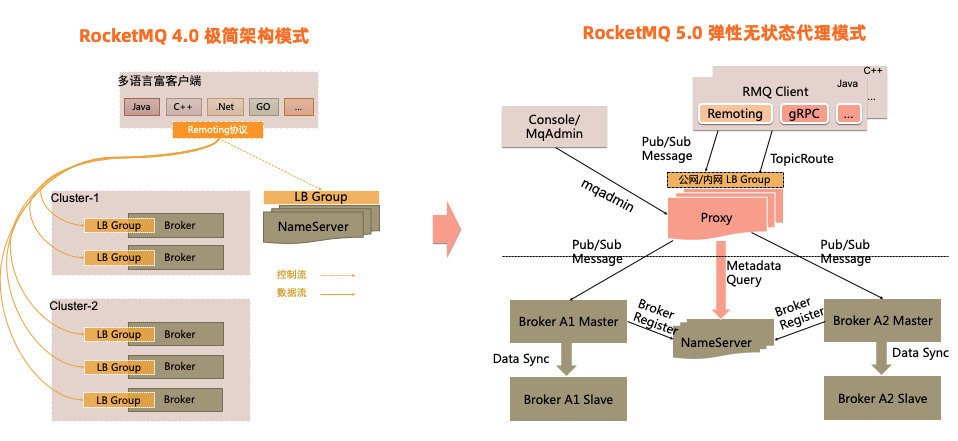
RocketMQ 5.0 引入了全新的弹性无状态代理模式,将当前的Broker职责进行拆分,对于客户端协议适配、权限管理、消费管理等计算逻辑进行抽离,独立无状态的代理角色提供服务,Broker则继续专注于存储能力的持续优化。这套模式可以更好地实现在云环境的资源弹性调度。 值得注意的是RocketMQ 5.0的全新模式是和4.0的极简架构模式相容相通的,5.0的代理架构完全可以以Local模式运行,实现与4.0架构完全一致的效果。开发者可以根据自身的业务场景自由选择架构部署。
部署的架构介绍
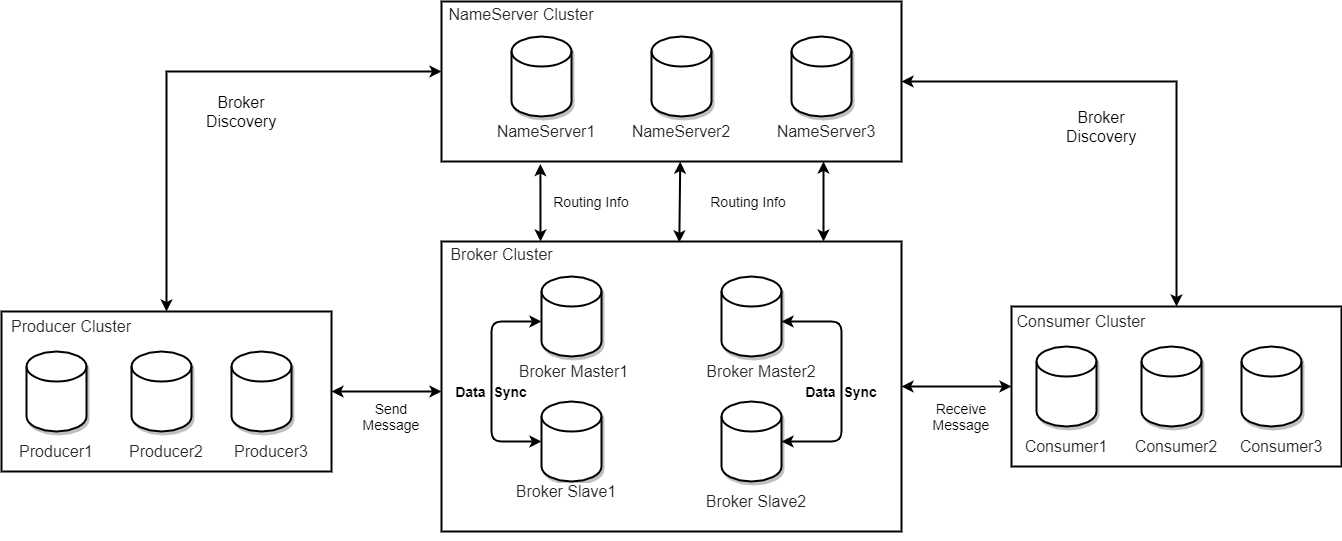
RocketMQ由以下这几个组件组成
- NameServer : 提供轻量级的Broker路由服务,可以理解为为rocketMq单独部署的注册中心,每个NameServer 之间无数据交互,相互独立,都存放有全部的路由信息(broker信息等)。
- Broker:实际处理消息存储、转发等服务的核心组件。
- Producer:消息生产者集群。通常是业务系统中的一个功能模块。
- Consumer:消息消费者集群。通常也是业务系统中的一个功能模块。
所以需要在服务器上部署NameServer 和Broker两个服务
master/slave
同步数据说明 :https://developer.aliyun.com/article/666458
slave->master同步:主要是指slave会定期向master发起同步数据请求,master向slave返回数据。
master->slave同步:在设置为同步双写的时候,master每写入一条消息都会同步到slave当中。
rocketMq安装(单组节点)
单组节点单副本模式:https://rocketmq.apache.org/zh/docs/quickStart/02quickstart/
下载界面地址 :https://rocketmq.apache.org/zh/download#rocketmq
官方介绍:https://rocketmq.apache.org/zh/docs/4.x/introduction/03whatis#%E5%90%8D%E5%AD%97%E6%9C%8D%E5%8A%A1%E5%99%A8-nameserver
环境准备和安装包下载
前置
请安装jdk1.8+版本
1、上传安装包、解压
unzip rocketmq-all-5.0.0-bin-release
mv rocketmq-all-5.0.0-bin-release rocketmq
2、
我们需要创建一个操作用户用来运行自己的程序,与root用户区分开。使用root用户创建一个oper用户,并给他创建一个工作目录。(仅做记录)
[root@worker1 ~]# useradd oper
[root@worker1 ~]# passwd oper
设置用户密码
[root@worker1 ~]# chown oper:oper /usr/local/app
# 切换用户
su oper
3、添加相关环境变量
系统环境变量修改:https://blog.csdn.net/fj_changing/article/details/116407529
jdk和rocketmq的全部环境变量配置,
# 编辑
vim /etc/profile
export JAVA_HOME=/usr/local/app/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export ROCKETMQ_HOME=/usr/local/app/rocketmq
PATH=$ROCKETMQ_HOME/bin:$PATH
export PATH
# 生效配置
source /etc/profile
# 其中多次执行号造成path有重复,可以 echo $PATH ,
export PATH=/usr/local/app/rocketmq/bin:/usr/local/app/java/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
这个ROCKETMQ_HOME的环境变量是必须要单独配置的,如果不配置的话,启动NameSever和Broker都会报错。
这个环境变量的作用是用来加载$ROCKETMQ_HOME/conf下的除broker.conf以外的几个配置文件。所以实际情况中,可以不按这个配置,但是一定要能找到配置文件。
NameServer启动
启动NameServer非常简单, 在$ROCKETMQ_HOME/bin目录下有个mqadminsrv。直接执行这个脚本就可以启动RocketMQ的NameServer服务。
但是要注意,RocketMQ默认预设的JVM内存是4G,这是RocketMQ给我们的最
佳配置。但是通常我们用虚拟机的话都是不够4G内存的,所以需要调整下JVM内存大小。修改的方式是直接修改runserver.sh。 用vi runserver.sh编辑这个脚本,在脚本中找到这一行调整内存大小为512M,当然如果是java8以上版本,修改下图中else部分。
-server -Xms512m -Xmx512m -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m
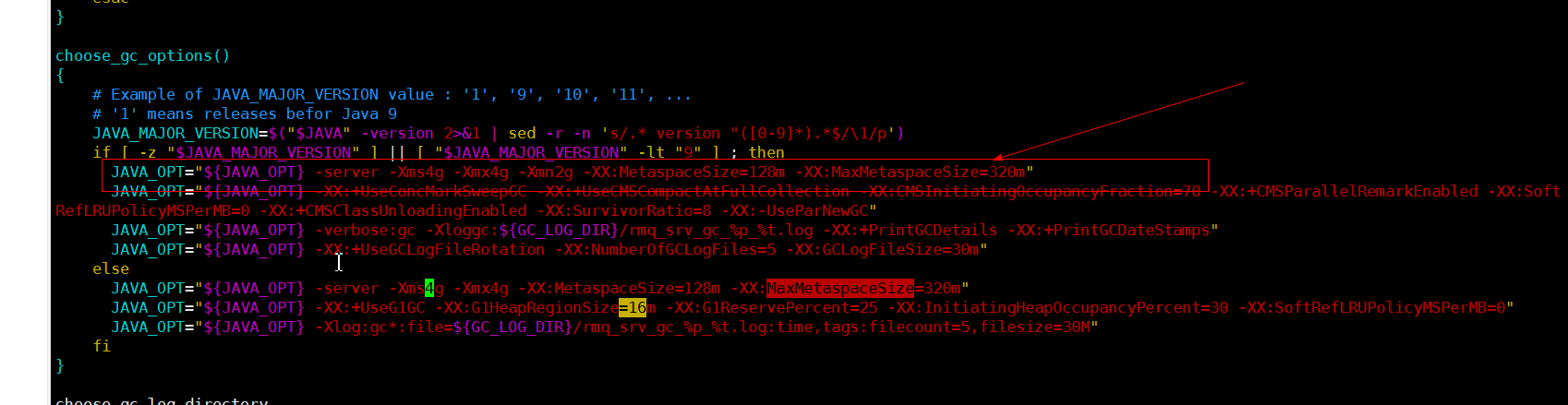
然后我们用静默启动的方式启动NameServer服务:启动完成后,在nohup.out里看到这一条关键日志就是启动成功了。并且使用jps
指令可以看到有一个NamesrvStartup进程。
### 启动namesrv 建议增加>/dev/null 2>&1
$ nohup sh bin/mqnamesrv &
### 验证namesrv是否启动成功
$ tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
关键日志标识启动成功
INFO main - The Name Server boot success. serializeType=JSON
Broker服务搭建
启动Broker的脚本是runbroker.sh。Broker的默认预设内存是8G,启动前,如果内存不够,同样需要调整下JVM内存。vi runbroker.sh,找到这一行,进行内存调整
JAVA_OPT="${JAVA_OPT} -server -Xms8g -Xmx8g"
然后我们需要找到$ROCKETMQ_HOME/conf/broker.conf, vi指令进行编辑,
在最下面加入一个配置:
autoCreateTopicEnable=true
然后也以静默启动的方式启动runbroker.sh
### 先启动broker 建议增加>/dev/null 2>&1
$ nohup sh bin/mqbroker -n localhost:9876 --enable-proxy &
### 验证broker是否启动成功, 比如, broker的ip是192.168.1.2 然后名字是broker-a
$ tail -f ~/logs/rocketmqlogs/broker_default.log
The broker[broker-a,192.169.1.2:10911] boot success...
启动完成后,同样是检查nohup.out日志,有这一条关键日志就标识启动成功了。 并且jps指令可以看到一个BrokerStartup进程。在观察runserver.sh和runbroker.sh时,我们还可以查看到其他的JVM执行参数,这些参数都可以进行定制。例如我们观察到一个比较有意思的地方,nameServer使用的是CMS垃圾回收器,而Broker使用的是G1
垃圾回收器。
测试消息收发
在进行消息收发之前,我们需要告诉客户端NameServer的地址,RocketMQ有多种方式在客户端中设置NameServer地址,这里我们利用环境变量NAMESRV_ADDR
$ export NAMESRV_ADDR=localhost:9876
# 集群需如下设置
export NAMESRV_ADDR='k8s-master:9876;k8s-node1:9876;k8s-node2:9876'
# 启动生产者发送消息,默认发送1000条消息,会打印消息发送日志
$ sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
SendResult [sendStatus=SEND_OK, msgId= ...
# 会打印消息机接收日志,这个Consume指令并不会结束,他会继续挂起,等待消费其他的消息。我们可以
使用CTRL+C停止该进程。
$ sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
ConsumeMessageThread_%d Receive New Messages: [MessageExt...
日志中MessageExt后的整个内容就是一条完整的RocketMQ消息。我们要对这个消息的结构有个大概的了解,后面会对这个消息进行深入的理解。其中比较关键的属性有:brokerName,queueId,msgId,topic,cluster,tags,body,transactionId。先找下这些属性在哪里。
ConsumeMessageThread_please_rename_unique_group_name_4_1 Receive New Messages: [MessageExt [brokerName=k8s-node1, queueId=3, storeSize=241, queueOffset=235, sysFlag=0, bornTimestamp=1666608764903, bornHost=/150.133.36.64:46330, storeTimestamp=1666608764904, storeHost=/150.133.36.64:10911, msgId=9685244000002A9F000000000003756F, commitLogOffset=226671, bodyCRC=494684516, reconsumeTimes=0, preparedTransactionOffset=0, toString()=Message{topic='TopicTest', flag=0, properties={MIN_OFFSET=0, TRACE_ON=true, MAX_OFFSET=250, MSG_REGION=DefaultRegion, CONSUME_START_TIME=1666608785055, UNIQ_KEY=96852440724710F87F487A7F53E703AD, CLUSTER=DefaultCluster, WAIT=true, TAGS=TagA}, body=[72, 101, 108, 108, 111, 32, 82, 111, 99, 107, 101, 116, 77, 81, 32, 57, 52, 49], transactionId='null'}]]
关闭服务
$ sh bin/mqshutdown broker
The mqbroker(36695) is running...
Send shutdown request to mqbroker(36695) OK
$ sh bin/mqshutdown namesrv
The mqnamesrv(36664) is running...
Send shutdown request to mqnamesrv(36664) OK
# 记录一下
$ sh bin/mqshutdown proxy
RocketMq 集群部署
请先查看rocketMq 安装部分,有部分前置安装说明
根据rocketMq的部署图,这里我部署三台NameServer服务,和两主两从的Broker服务,具体如下
|
NameServer部署 |
broker部署 |
| 47.100.56.197 |
NameServer |
|
| 43.143.136.203 |
NameServer |
broker-a,broker-b-s |
| 61.171.5.6 |
NameServer |
broker-b,broker-a-s |
复制安装包到对应的服务器
多种集群模式介绍
官方的多种部署模式:https://rocketmq.apache.org/zh/docs/deploymentOperations/15deploy
1、单组节点单副本模式 :NameServer、Broker、Proxy 等都部署一个节点,部署在同一台机器上
2、多组节点(集群)单副本模式
一个集群内全部部署 Master 角色,不部署Slave 副本,例如2个Master或者3个Master,这种模式的优缺点如下:
3、多节点(集群)多副本模式-异步复制
每个Master配置一个Slave,有多组 Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
4、多节点(集群)多副本模式-同步双写
每个Master配置一个Slave,有多对 Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
部署三台NameServer
如果内存不够,注意修改启动bin/runserver.sh启动参数,注意执行的目录
### 启动namesrv 建议增加>/dev/null 2>&1
$ nohup sh bin/mqnamesrv &
### 验证namesrv是否启动成功
$ tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
Broker 配置
服务端配置:https://rocketmq.apache.org/zh/docs/4.x/parameterConfiguration/24server
安装包提供了多种集群部署的配置文件,对应不同的集群模式,在conf目录下2m-开头的相关文件,配置文件的只对应一个nameServer,我们稍作修改
以下文件部分内容全部注释,没有在官方文档上找到对应配置,使用时注意
broker-a.properties
# 集群名称
brokerClusterName=DefaultCluster
# broker名字,名字一样的节点就是一组主从节点。
brokerName=broker-a
# broker id, 0 表示 master, 其他的正整数表示 slave
brokerId=0
# 当前 broker 监听的 IP,避免选择不正确的网卡
brokerIP1=43.143.136.203
# 在每天的什么时间删除已经超过文件保留时间的 commit log
deleteWhen=04
# 以小时计算的文件保留时间
fileReservedTime=48
# SYNC_MASTER/ASYNC_MASTER/SLAVE 前两个对应两种集群模式,其中SLAVE对应从节点
brokerRole=ASYNC_MASTER
# flushDiskType表示刷盘策略,分为SYNC_FLUSH和ASYNC_FLUSH两种,分别代表同步刷盘和异步刷盘。同步刷盘情况下,消息真正写入磁盘后再返回成功状态;异步刷盘情况下,消息写入page_cache后就返回成功状态。
flushDiskType=ASYNC_FLUSH
# 以下是新增配置
#Broker 对外服务的监听端口(默认10911)
listenPort=10911
# nameServer地址,分号分割,此处需要在三台机器的hosts中配置映射
namesrvAddr=k8s-master:9876;k8s-node1:9876;k8s-node2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#commitlog存储路径
storePathCommitLog=/usr/local/app/rocketmq/store/commitlog/
#consumequeue存储路径
storePathConsumerQueue=/usr/local/app/rocketmq/store/consumequeue/
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
# 以下配置仅做记录
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
#diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/usr/local/app/rocketmq/store/
#消息索引存储路径
storePathIndex=/usr/local/app/rocketmq/store/index/
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/app/rocketmq/store/checkpoint/
# abort 文件存储路径
abortFile=/usr/local/app/rocketmq/store/abort/
#限制的消息大小
maxMessageSize=65536
#一次刷盘至少需要脏页的数量,针对commitlog文件
#flushCommitLogLeastPages=4
# 一次刷盘至少需要脏页的数量,默认2页,针对 Consume文件
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
过期判断
- fileReservedTime
文件删除主要是由这个配置属性,文件保留时间。也就是从最后一次更新时间到现在,如果超过了该时间,则认为是过期文件,可以删除。
- deletePhysicFilesInterval
删除物理文件的时间间隔(默认是 100MS),在一次定时任务触发时,可能会有多个物理文件超过过期时间可被删除, 因此删除一个文件后需要间隔 deletePhysicFilesInterval 这个时间再删除另外一个文件,由于删除文件是一个非常耗费 IO 的操作,会引起消息插入消 费的延迟(相比于正常情况下),所以不建议直接删除所有过期文件。
- destroyMapedFileIntervalForcibly
在删除文件时,如果该文件还被线程引用,此时会阻止此次删除操作,同时将该文件标记不可用并且纪录当前时间戳 destroyMapedFileIntervalForcibly 这个表示文件在第一次删除拒绝后,文件保存的最大时间,在此时间内一直会被拒绝删除,当超过这个时间时,会将引用每次减少 1000,直到引用 小于等于 0 为止,即可删除该文件。
broker-a-s.properties
其他配置和broker-a.properties相同
brokerId=1
brokerRole=SLAVE
#Broker 对外服务的监听端口(默认10911)
listenPort=11011
# 当前 broker 监听的 IP,避免选择不正确的网卡
brokerIP1=61.171.5.6
#commitlog存储路径
storePathCommitLog=/usr/local/app/rocketmq/store_slave/commitlog/
#consumequeue存储路径
storePathConsumerQueue=/usr/local/app/rocketmq/store_slave/consumequeue/
#存储路径
storePathRootDir=/usr/local/app/rocketmq/store_slave/
#消息索引存储路径
storePathIndex=/usr/local/app/rocketmq/store_slave/index/
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/app/rocketmq/store_slave/checkpoint/
# abort 文件存储路径
abortFile=/usr/local/app/rocketmq/store_slave/abort/
broker-b.properties
其他配置和broker-a.properties相同
brokerName=broker-b
# 当前 broker 监听的 IP,避免选择不正确的网卡
brokerIP1=61.171.5.6
broker-b-s.properties
其他配置和broker-a.properties相同
brokerName=broker-b
brokerId=1
brokerRole=SLAVE
# 当前 broker 监听的 IP,避免选择不正确的网卡
brokerIP1=43.143.136.203
#Broker 对外服务的监听端口(默认10911)
listenPort=11011
# 当前 broker 监听的 IP,避免选择不正确的网卡
brokerIP1=43.143.136.203
#commitlog存储路径
storePathCommitLog=/usr/local/app/rocketmq/store_slave/commitlog/
#consumequeue存储路径
storePathConsumerQueue=/usr/local/app/rocketmq/store_slave/consumequeue/
#存储路径
storePathRootDir=/usr/local/app/rocketmq/store_slave/
#消息索引存储路径
storePathIndex=/usr/local/app/rocketmq/store_slave/index/
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/app/rocketmq/store_slave/checkpoint/
# abort 文件存储路径
abortFile=/usr/local/app/rocketmq/store_slave/abort/
放通端口
参考 : https://blog.csdn.net/Taiyii/article/details/125526511
#Broker 对外服务的监听端口(默认10911)
listenPort=10911
nameserver端口 : 9876
其他端口待定
10909 : dashboard日志打印报错的端口
11009
11011 : 我配置文件中从broker的监听端口
启动Broker+Proxy集群
由于我这边没有机器,这里只不同的beoker主从节点交叉部署,具体配置的不同在配置文件中有体现
# 如果配置文件中,没有指定nameserver地址,可以添加 -n k8s-master:9876;k8s-node1:9876;k8s-node2:9876 进行指定,多个地址使用逗号分隔
### 在机器A,启动第一个Master, 43.143.136.203
nohup sh bin/mqbroker -c $ROCKETMQ_HOME/conf/2m-2s-async/broker-a.properties &
### 在机器B,启动第二个Master,61.171.5.6
nohup sh bin/mqbroker -c $ROCKETMQ_HOME/conf/2m-2s-async/broker-b.properties &
### 在机器B,启动第一个Slave,61.171.5.6
nohup sh bin/mqbroker -c $ROCKETMQ_HOME/conf/2m-2s-async/broker-a-s.properties &
### 在机器A,启动第二个Slave,43.143.136.203
nohup sh bin/mqbroker -c $ROCKETMQ_HOME/conf/2m-2s-async/broker-b-s.properties &
# 通过nohup.out查看启动是否成功,jps查看对应的进程是否存在
# 不同机器上执行,对应相应的nameserver 地址, 指定多个地址时报错,这里后续可能有问题,再说
nohup sh bin/mqproxy -n 47.100.56.197:9876 &
nohup sh bin/mqproxy -n 61.171.5.6:9876 &
nohup sh bin/mqproxy -n 43.143.136.203:9876 &
master是负责接收消息的,所以集群中至少有一个master才能写入消息,master挂了之后,对应的slave不会自动切换为master,slave保证了master挂了之后消息还是可以被正常消费
主备自动切换模式部署
Controller 组件
官方:https://rocketmq.apache.org/zh/docs/deploymentOperations/16autoswitchdeploy
该文档主要介绍如何部署支持自动主从切换的 RocketMQ 集群,其架构如上图所示,主要增加支持自动主从切换的 Controller 组件,其可以独立部署也可以内嵌在 NameServer 中。
仅仅做记录
Dledger快速搭建
官方:https://rocketmq.apache.org/zh/docs/bestPractice/16dledger
DLedger是一套基于Raft协议的分布式日志存储组件,部署 RocketMQ 时可以根据需要选择使用DLeger来替换原生的副本存储机制。本文档主要介绍如何快速构建和部署基于 DLedger 的可以自动容灾切换的 RocketMQ 集群。
仅仅做记录
从官方文档上看Controller 对应的主备切换似乎更简单一点,就了解而言DLedger似乎会造成主从节点之间大量通讯,浪费带宽资源,似乎使用不多
RocketMQ Promethus Exporter
官网:https://rocketmq.apache.org/zh/docs/deploymentOperations/18Exporter
Rocketmq-exporter 是用于监控 RocketMQ broker 端和客户端所有相关指标的系统,通过 mqAdmin 从 broker 端获取指标值后封装成 87 个 cache。包含前端展示界面。
仅仅做记录
RocketMQ Dashboard
RocketMQ Dashboard 是 RocketMQ 的管控利器,为用户提供客户端和应用程序的各种事件、性能的统计信息,支持以可视化工具代替 Topic 配置、Broker 管理等命令行操作。
官网地址:https://rocketmq.apache.org/zh/docs/4.x/deployment/17Dashboard
这里采用源码安装的方式
源码地址:apache/rocketmq-dashboard
下载并解压,切换至源码目录 rocketmq-dashboard-master/
① 编译 rocketmq-dashboard
# 执行前安装maven,添加环境变量,注意编译目录不要包含中文
$ mvn clean package -Dmaven.test.skip=true
② 运行 rocketmq-dashboard
有需要的,自行添加jvm参数
$ java -jar rocketmq-dashboard-1.0.1-SNAPSHOT.jar
nohup java -jar rocketmq-dashboard-1.0.1-SNAPSHOT.jar &
编译完成后,获取target下的jar包,就可以直接执行。但是这个时候要注意,在这个项目的application.yml中需要指定nameserver的地址。默认这个属性是指向本地。如果配置为空,会读取环境变量NAMESRV_ADDR。那我们可以在jar包的当前目录下增加一个application.yml文件,覆盖jar包中默认的一个属性,也可以先修改配置文件再打包,或者直接在java -jar 启动参数中给对应属性赋值 ,这里我直接修改后再打包:
rocketmq:
config:
# if this value is empty,use env value rocketmq.config.namesrvAddr NAMESRV_ADDR | now, default localhost:9876
# configure multiple namesrv addresses to manage multiple different clusters
namesrvAddrs:
- k8s-master:9876
- k8s-node1:9876
- k8s-node2:9876
提示:Started App in x.xxx seconds (JVM running for x.xxx) 启动成功
浏览器页面访问:namesrv.addr:18080,这里由于8080端口死活访问不通,修改了启动端口18080
关闭 rocketmq-dashboard : ctrl + c
开启登录模式
mvn打包前修改application.yml 中 rocketmq.config下配置,修改为ture
# must create userInfo file: ${rocketmq.config.dataPath}/users.properties if the login is required
loginRequired: false
修改users.properties
# Format: a user per line, username=password[,N] #N is optional, 0 (Normal User); 1 (Admin)
如注释所描述的一样
每行定义一个用户, username=password[,N] #N是可选项,可以为0 (普通用户); 1 (管理员)
其本身的默认用户,请自行修改
# Define Admin
admin=admin,1
# Define Users
user1=user1
user2=user2
系统参数调优
官方地址;https://rocketmq.apache.org/zh/docs/bestPractice/19JVMOS
到这里,我们的整个RocketMQ的服务就搭建完成了。但是在实际使用时,我们说rocketMQ的吞吐量、性能都很高,那要发挥RocketMQ的高性能,还需要对RocketMQ以及服务器的性能进行定制
1、配置RocketMQ的JVM内存大小:
之前提到过,在runserver.sh中需要定制nameserver的内存大小,在runbroker.sh中需要定制broker的内存大小。这些默认的配置可以认为都是经过检验的最优化配置,但是在实际情况中都还需要根据服务器的实际情况进行调整。这里以
runbroker.sh中对G1GC的配置举例,在runbroker.sh中的关键配置:
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:G1HeapRegionSize=16m -
XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -
XX:SoftRefLRUPolicyMSPerMB=0"
JAVA_OPT="${JAVA_OPT} -verbose:gc -
Xloggc:${GC_LOG_DIR}/rmq_broker_gc_%p_%t.log -XX:+PrintGCDetails -
XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -
XX:+PrintAdaptiveSizePolicy"
JAVA_OPT="${JAVA_OPT} -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -
XX:GCLogFileSize=30m"
-XX:+UseG1GC: 使用G1垃圾回收器, -XX:G1HeapRegionSize=16m 将G1的region块大小设为16M,-XX:G1ReservePercent:在G1的老年代中预留25%空闲
内存,这个默认值是10%,RocketMQ把这个参数调大了。-XX:InitiatingHeapOccupancyPercent=30:当堆内存的使用率达到30%之后就会启动G1垃圾回收器尝试回收垃圾,默认值是45%,RocketMQ把这个参数调小了,也就是提高了GC的频率,但是避免了垃圾对象过多,一次垃圾回收时间太长的问题。
然后,后面定制了GC的日志文件,确定GC日志文件的地址、打印的内容以及控制每个日志文件的大小为30M并且只保留5个文件。这些在进行性能检验时,是相当重
要的参考内容。
2、RocketMQ的其他一些核心参数
例如在conf/dleger/broker-n0.conf中有一个参数:
sendMessageThreadPoolNums=16。这一个参数是表明RocketMQ内部用来发送消息的线程池的线程数量是16个,其实这个参数可以根据机器的CPU核心数进行适当调整,例如如果你的机器核心数超过16个,就可以把这个参数适当调大。
3、Linux内核参数定制
我们在部署RocketMQ的时候,还需要对Linux内核参数进行一定的定制。例如
- ulimit,需要进行大量的网络通信和磁盘IO。
- vm.extra_free_kbytes,告诉VM在后台回收(kswapd)启动的阈值与直接回收(通过分配进程)的阈值之间保留额外的可用内存。RocketMQ使用此参数来避免内存分配中的长延迟。(与具体内核版本相关)
- vm.min_free_kbytes,如果将其设置为低于1024KB,将会巧妙的将系统破坏,并且系统在高负载下容易出现死锁。
- vm.max_map_count,限制一个进程可能具有的最大内存映射区域数。RocketMQ将使用mmap加载CommitLog和ConsumeQueue,因此建议将为此参数设置较大的值。
- vm.swappiness,定义内核交换内存页面的积极程度。较高的值会增加攻击性,较低的值会减少交换量。建议将值设置为10来避免交换延迟。
- File descriptor limits,RocketMQ需要为文件(CommitLog和ConsumeQueue)和网络连接打开文件描述符。我们建议设置文件描述符的值为655350。
这些参数在CentOS7中的配置文件都在 /proc/sys/vm目录下。另外,RocketMQ的bin目录下有个os.sh里面设置了RocketMQ建议的系统内核参数,可以根据情况进行调整。
rocketMq相关知识
rocketMq相关知识 :https://blog.csdn.net/qq_42792950/article/details/123590855
1、为什么RocketMQ不用Zookeeper而要自己实现一个NameServer来进行注册?
https://www.codenong.com/js456f9759bb97/
从cap的角度,首先zookeeper满足的是cp,当其中一个节点宕机后,需要一定的时间选举出新的leader来对外提供服务,且zookeeper确定数据接收成功需要一半以上的节点都接收成功才行,耗时更长,就rocketmq应用场景,更适合使用满足cp理论的nameServer,至于为什么不用nacos,相比于nacos提供的众多服务,nameServer是轻量的,更适合rocketmq,如果使用nacos,还需要考虑版本的兼容问题
- 一致性(Consistency):Name Server 集群中的多个实例,彼此之间是不通信的,这意味着某一时刻,不同实例上维护的元数据可能是不同的,客户端获取到的数据也可能是不一致的。
- 可用性(Availability):只要不是所有NameServer节点都挂掉,且某个节点可以在指定之间内响应客户端即可。
- 分区容错(Partiton Tolerance):对于分布式架构,网络条件不可控,出现网络分区是不可避免的,只要保证部分NameServer节点网络可达,就可以获取到数据。具体看公司如何实施,例如:为了实现跨机房的容灾,可以将NameServer部署的不同的机房,某个机房出现网络故障,其他机房依然可用,当然Broker集群/Producer集群/Consumer集群也要跨机房部署。
2、Consumer分组有什么用?Producer分组呢?
Consumer分组,一个分组可能包含多个机器,只要一个机器消费成功,就可以认为消息已经被消费,且消息重试机制,对于同一个消费分组,其中一台机器挂了,下次重试可以发送给另外一台机器
Producer分组更多的作用是用于事务类型的消息,消息被消费后告知消息生产者()
3、RocketMQ如何保证集群高可用?
nameserver 是ap架构,任意节点挂了之后,其他节点照样可以对外提供服务
broker集群部署,可以部署多组主备Broker,可以进行水平扩容-增加一组主备,单个master挂了之后,slave可以保证消息正常被consumer消费,不会影响整个集群对外提供服务,如果需要,可以部署contorller和Dledger ,提供主从自动切换的能力。
关联信息
- 关联的主题:
- 上一篇:
- 下一篇:
- image: 20221021/1
- 转载自: