目标:基于Inception网络实现对危险物品检测,将危险物品图片或视频经过图像预处理后输入模型推理,最后将检测结果进行可视化输出。
一、原理
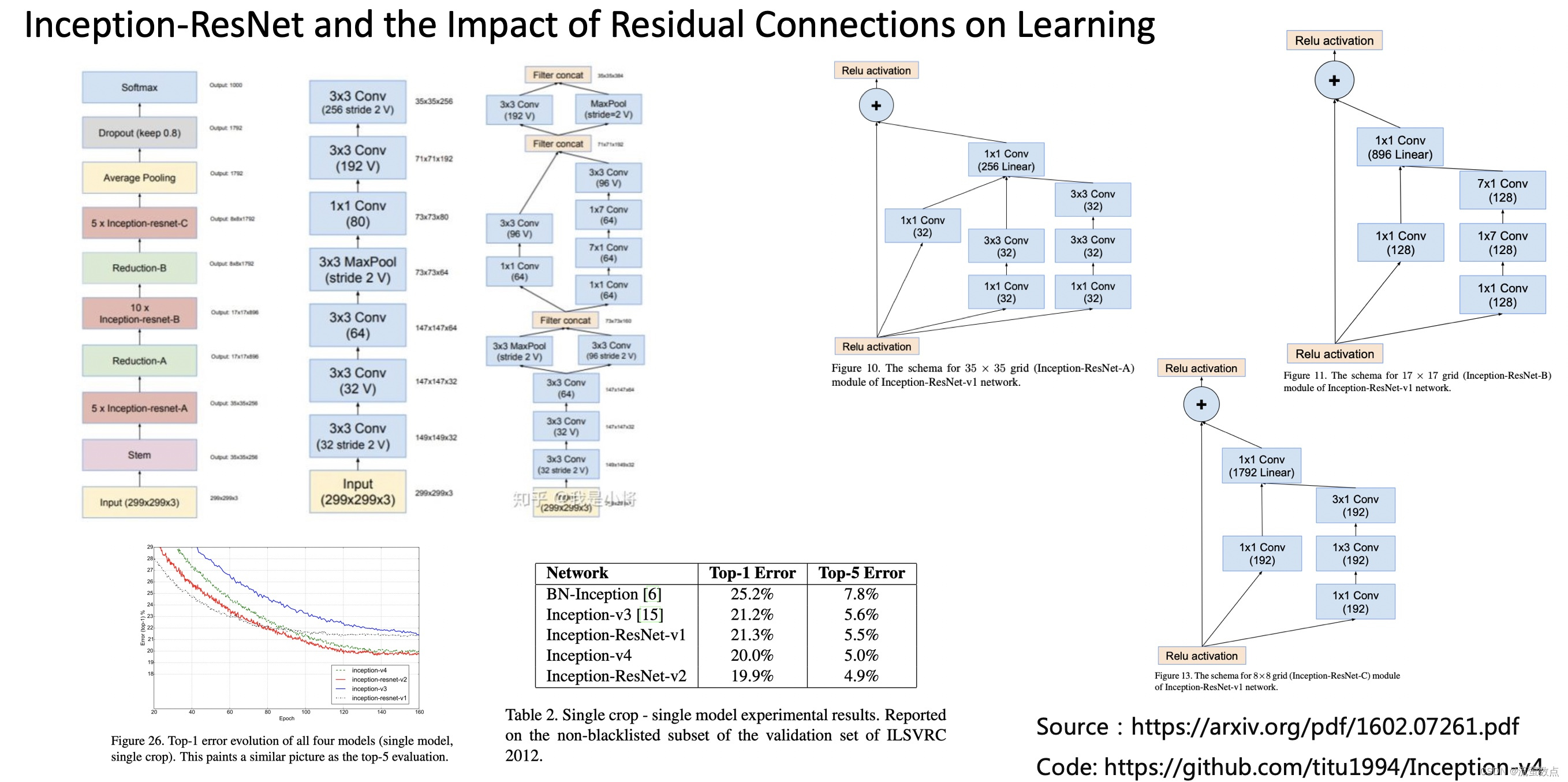
Google的Inception网络介绍
Inception为Google开源的CNN模型,至今已经公开四个版本,每一个版本都是基于大型图像数据库ImageNet中的数据训练而成。因此我们可以直接利用Google的Inception模型来实现图像分类。

二、过程
1.导入库
首先导入需要的组件包,包括tensorflow、keras、IPython等,代码如下:
# 安装完成需要重启kernel
!pip3 install pygame
!pip3 install opencv_python
# !pip3 install tensorflow==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
from PIL import Image
import numpy as np
import cv2
import time
import os
import sys
import logging as log
import pygame
from tensorflow.keras.applications.inception_v3 import decode_predictions
from keras.applications import InceptionV3
from keras.applications import imagenet_utils
from IPython.display import clear_output, Image, display, HTML

2.导入数据
#准备数据,从OSS中获取数据并解压到当前目录:
import oss2
access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', 'LTAI4G1MuHTUeNrKdQEPnbph')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', 'm1ILSoVqcPUxFFDqer4tKDxDkoP1ji')
bucket_name = os.getenv('OSS_TEST_BUCKET', 'mldemo')
endpoint = os.getenv('OSS_TEST_ENDPOINT', 'https://oss-cn-shanghai.aliyuncs.com')
# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行
bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)
# 下载到本地文件
bucket.get_object_to_file('data/c12/danger_detect_data.zip', 'danger_detect_data.zip')
#解压数据
!unzip -o -q danger_detect_data.zip -d danger_detect_input
!rm -rf __MACOSX
!ls danger_detect_input -ilht
3.定义工具方法
#数据预处理
def pre_process_image(image, img_height=299):
n, c, h, w = [1, img_height, img_height,3]
processedImg = image
# 图像归一化处理
processedImg = (np.array(processedImg) - 0) / 255.0
# Change data layout from HWC to CHW
processedImg = processedImg.transpose((2, 0, 1))
processedImg = processedImg.reshape((n, c, h, w))
return image, processedImg
# 视频显示
def arrayShow(imageArray):
ret, png = cv2.imencode('.jpg', imageArray)
return Image(png)
# 将dlib中rect对像转化为(top, right, bottom, left)形式
def _rect_to_css(rect):
return rect.top(), rect.right(), rect.bottom(), rect.left()
# 确保(top, right, bottom, left)在图片内部
def _trim_css_to_bounds(css, image_shape):
return max(css[0], 0), min(css[1], image_shape[1]), min(css[2], image_shape[0]), max(css[3], 0)
4.加载模型
print("[INFO] loading InceptionV3 model...")
model = InceptionV3(weights="imagenet")
Inception-v3:针对Inception-v2的升级,增加了以下内容:(1)RMSProp优化器。(2)分解为7*7卷积。(3)辅助分类BatchNorm。(4)标签平滑(Label Smoothing,添加到损失公式中的正则化组件类型,防止网络过于准确,防止过度拟合)。
5.查看模型信息
#查看模型信息
model.summary()

6.查看模型的输入要求
#查看模型的输入要求
model.input

7.查看模型的输出
#查看模型的输出
model.output

8.初始化参数
#可视化字体颜色
textColor = (255, 0, 0)
#摄像头输入图像宽度
camera_width = 299*2
#摄像头输入图像高度
camera_height = 299*2
#定义模型输入
inputShape = (299, 299)
#图片地址
path = "danger_detect_input/"
#初始化声音报警
pygame.init()
alarm = None
try:
pygame.mixer.init()
pygame.mixer.pre_init(44100, -16, 2, 2048)
alarm = pygame.mixer.music.load('alarm.mp3')
except:
alarm = None
9.危险物品检测
from pygame.locals import *
input_file = "danger_detect_input/input/out1.mov"
video_capture = cv2.VideoCapture(input_file)
video_capture.set(cv2.CAP_PROP_FPS, 10)
video_capture.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
video_capture.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
ret, frame = video_capture.read()
elapsedTime = 0
fps = ""
danger_classes = ["assault_rifle","lighter"]
print("begin process..",ret)
while ret:
t1 = time.time()
ret, frame = video_capture.read()
if not ret: break
frame = cv2.resize(frame, inputShape)
time.sleep(2)
_, image = pre_process_image(frame)
#模型预测
preds = model.predict(image)
#解析识别结果
P = imagenet_utils.decode_predictions(preds)
result = P[0][0]
cv2.putText(frame, fps, (20, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 255), 1, cv2.LINE_AA)
cv2.putText(frame, str(result[1]+" prob:"+str(result[2])), (20, 35), cv2.FONT_HERSHEY_SIMPLEX, 0.5, textColor, 1, cv2.LINE_AA)
if result[1] in danger_classes and alarm:
pygame.mixer.music.play(0)
# 清空绘图空间
clear_output(wait=True)
# 显示处理结果
display(arrayShow(frame))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
elapsedTime = time.time() - t1
fps = "{:.1f} FPS".format(1 / elapsedTime)
cv2.destroyAllWindows()
