Python
Java
PHP
IOS
Android
Nodejs
JavaScript
Html5
Windows
Ubuntu
Linux
宽表, 窄表, 维度表, 事实表的区别
2023-11-18
在数据开发里, 会涉及到一些概念: 宽表, 窄表, 维度表, 事实表
宽表: 把多个维度的字段都放在一张表存储, 增加数据冗余是为了减少关联, 便于查询. 查询一张表就可以查出不同维度的多个字段
窄表: 和我们 mysql 普通表三范式相同, 把相同维度的字段组成一张表, 表和表之间关联查询其他维度数据.
维度表: 包含维度编码和该维度下的多个属性
事实表: 包含一个业务事件的相关属性
举例
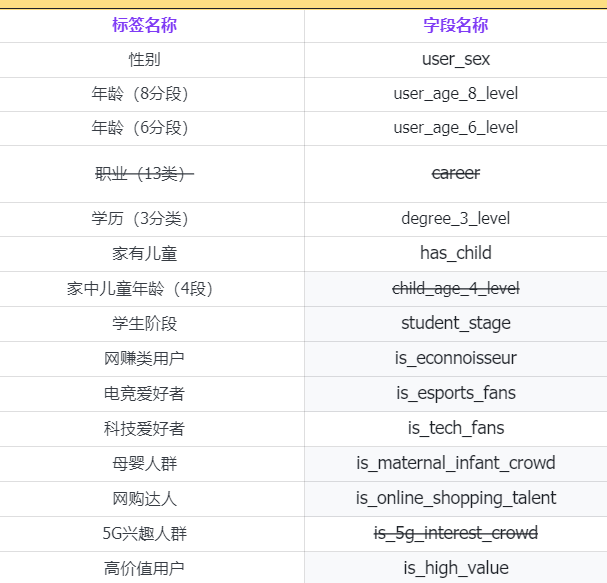
宽表
包含性别, 年龄, 各个用户身份
维度表
事实表
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
Bigdata
数据
宽表, 窄表, 维度表, 事实表的区别 的相关文章
实施 MySQL NDB Cluster 有哪些限制?
我想为 MySQL Cluster 6 实现 NDB Cluster 我想为至少有 200 万条记录的非常庞大的数据结构执行此操作 我想知道实施 NDB cluster 是否有任何限制 例如 RAM 大小 数据库数量或 NDB 集群的数据库
R 向量大小限制:“.C 中不支持长向量(参数 5)”
我有一个非常大的矩阵 我试图在有足够内存的服务器上通过 glmnet 运行 即使在达到某一点的非常大的数据集上它也能正常工作 之后我收到以下错误 Error in elnet x long vectors argument 5 are no
Flume的Spool Dir可以在远程机器上吗?
每当新文件到达特定文件夹时 我就尝试将文件从远程计算机获取到我的 hdfs 我在flume中遇到了spool dir的概念 如果spool dir位于运行flume代理的同一台机器上 那么它工作得很好 有什么方法可以在远程计算机中配置假脱机
Dask 在 Groupby 上复制 Pandas 值
我想做的是在 dask 中复制 panda 的值计数 idxmax 函数 因为我有很多数据 这是一个示例数据框 partner num cust id item id revw ratg num revw dt item qty 0 100
在 MATLAB 中处理大型 CSV 文件
我必须处理一个最大 2GB 的大 CSV 文件 更具体地说 我必须将所有这些数据上传到 mySQL 数据库 但在我必须对此进行一些计算之前 所以我需要在 MATLAB 中完成所有这些操作 我的主管也想在 MATLAB 中完成 因为他熟悉MA
存储大量数据的最智能方式
我想通过 REST 请求访问 flickr API 并下载大约的元数据 1 张 Mio 照片 也许更多 我想将它们存储在 csv 文件中 然后将它们导入 MySQL 数据库以进行进一步处理 我想知道处理如此大数据的最明智的方法是什么 我不确
Flink 中的水印和触发器有什么区别?
我读到 排序运算符必须缓冲它接收到的所有元素 然后 当它接收到水印时 它可以对时间戳低于水印的所有元素进行排序 并按排序顺序发出它们 这是正确 因为水印表明不能有更多元素到达并与已排序元素混合 https cwiki apache org
Hive alter table 更改列名称为重命名的列提供“NULL”
我曾尝试将表中的现有列重命名为新列 但名称更改后 新列只给我 NULL 值 Parquet 中表的存储格式 例如 user 是 Test 表中字符串数据类型的列 插入了值为 John 的示例记录 Select user from Test
将大量数据加载到数组中的最快方法
我在 stackexchange 中广泛搜索了一个将巨大 2GB dat 文件加载到 numpy 数组中的简洁解决方案 但没有找到合适的解决方案 到目前为止 我设法以非常快的方式 list f open myhugefile0 for li
Python + Beam + Flink
我一直在尝试让 Apache Beam 可移植性框架与 Python 和 Apache Flink 一起使用 但我似乎找不到一套完整的指令来让环境正常工作 是否有任何参考资料包含使简单的 python 管道正常工作的先决条件和步骤的完整列表
将 pandas 数据框中的行和上一行与数百万行进行比较的最快方法
我正在寻找解决方案来加速我编写的函数 以循环遍历 pandas 数据帧并比较当前行和前一行之间的列值 例如 这是我的问题的简化版本 User Time Col1 newcol1 newcol2 newcol3 newcol4 0 1 6 c
HDFS 作为 cloudera 快速入门 docker 中的卷
我对 hadoop 和 docker 都很陌生 我一直致力于扩展 cloudera quickstart docker 镜像 docker 文件 并希望从主机挂载一个目录并将其映射到 hdfs 位置 以便提高性能并将数据保存在本地 当我在任
如何在 Elasticsearch 中或在 Lucene 级别进行联接
在 Elasticsearch 中执行相当于 SQL 连接的最佳方法是什么 我有一个包含两个大表的 SQL 设置 Persons 和 Items 一个人可以拥有many项目 人员和项目行都可以更改 即更新 我必须运行根据人和物品的各个方面进
Postgresql - 在大数据库中使用数组的性能
假设我们有一个包含 600 万条记录的表 有 16 个整数列和少量文本列 它是只读表 因此每个整数列都有一个索引 每条记录大约 50 60 字节 表名称为 项目 服务器为 12 GB RAM 1 5 TB SATA 4 核 所有 postg
将 data.frame 转换为 ff
我想将 data frame 转换为 ff 对象 并使用 as ffdf 进行描述here https stackoverflow com questions 15787221 how can i apply ffdf to non ato
在 Spark 中,广播是如何工作的?
这是一个非常简单的问题 在 Spark 中 broadcast可用于有效地将变量发送给执行器 这是如何运作的 更确切地说 何时发送值 我一打电话就发送broadcast 或者何时使用这些值 数据到底发送到哪里 发送给所有执行者 还是只发送给
使用 big.matrix 对象计算欧几里德距离矩阵
我有一个类对象big matrix in R有尺寸778844 x 2 这些值都是整数 公里 我的目标是使用以下公式计算欧几里德距离矩阵big matrix并因此得到一个类的对象big matrix 我想知道是否有最佳方法可以做到这一点 我
为什么 Spark 在字数统计时速度很快? [复制]
这个问题在这里已经有答案了 测试用例 Spark 在 20 秒以上对 6G 数据进行字数统计 我明白映射减少 FP and stream编程模型 但无法弄清楚字数统计的速度如此惊人 我认为这种情况下是I O密集型计算 不可能在20秒以上扫描
计算 HBase 表中列族的记录数
我正在寻找一个 HBase shell 命令来计算指定列族中的记录数 我知道我可以运行 echo scan table name hbase shell grep column family name wc l 然而 这将比标准计数命令运行
hadoop中reducer的数量
我正在学习hadoop 我发现减速器的数量非常令人困惑 1 reducer的数量与partition的数量相同 2 reducer 的数量是 0 95 或 1 75 乘以 节点数 每个节点的最大容器数 3 减速机数量设定为mapred re
随机推荐
关键元器件选型设计指引--通用逻辑器件(逻辑IC)
1 物料分类 标准逻辑器件 标准数字逻辑IC集成电路可以从工艺 功能和电平三个方面划分 列表所示 注 常见的逻辑电路有54军用系列和74商用系列 两者电路功能一致 本文仅讨论74系列 按照制造工艺特点分类 工艺 逻辑器件产品族 优点 不足
sublime-text3-自定义代码补全
自定义代码补全 打开sublime text3 选择菜单栏 工具 gt 新代码段 按以下模板填充 content 在CDATA中填补全内容 tabTrigger 触发代码 scope 文件类型 description 描述信息 下例为 输入
Kafka一致性
一 存在的一致性问题 1 生产者和Kafka存储一致性的问题 即生产了多少条消息 就要成功保存多少条消息 不能丢失 不能重复 更重要的是不丢失 其实就是要确保消息写入成功 这可以通过acks 1来保证 保证所有ISR的副本都是一致的 即一条
CSP 202212-1 现值计算
答题 主要就是 include
“无法从静态上下文中引用非静态变量,非静态方法”原因及解决
1 原因 1 用static修饰的方法为静态方法 修饰变量则为静态变量 又分别叫做类方法或者类变量 这些从属于类 是类本身具备的 没有实例也会存在 2 而非静态方法和变量的存在依赖于对象 是对象的属性 需要先创建实例对象 然后通过对象调用
★SQL注入漏洞(7)SQL注入高级篇
分析目标防火墙并且跳过 1 直接拉黑ip类防火墙 2 过滤删除相应字符的防火墙 1 waf注释符号过滤 例题 Sqli labs T23 特点 注释符 被过滤掉了 绕过方法 逻辑上补全闭合即可 多加一次url编码只是更安全的绕过 selec
Redis系列1——数据类型和常用数据操作
一 redis基础知识 客户端和服务器命令 默认端口号6379 服务器命令 redis server redis windows conf 设置服务一直开启 首先进入redis安装目录 然后执行 redis server service i
android so 调试
安卓调试 环境 tool JDK 8X 之前用15版本的 monitor一直无法启动 链接 https pan baidu com s 12LUwB7ZOVEcblAzkO8hxyA 提取码 5lw0 monitor bat 流程 开启调试
mybatis学习笔记8:注解开发
文章目录 一 基于注解的开发环境搭建以及实现查询所有 1 定义主配置文件 2 准备实体类和Dao接口 3 Dao接口定义findAll方法 以及添加注解 4 测试类定义方法测试 5 注解开发和基于xml的映射配置文件开发对比 6 注解开发的
数据结构练习题——图(含应用题)
1 选择题 1 在一个图中 所有顶点的度数之和等于图的边数的 倍 A 1 2 B 1 C 2 D 4 答案 C 2 在一个有向图中 所有顶点的入度之和等于所有顶点的出度之和的 倍 A 1 2 B 1 C 2 D 4 答案 B 解释 有向图所
黄聪:微信小程序 服务器 TLS1.0 1TLS.2 配置详细教学!
下载IISCrypto exe 点击best 工具自动推荐选中 也可以定义勾选 选择配置完成 然后点击 apply 软件弹窗提醒你 手动重启服务器 重启服务器 搞定 最后 https www ssllabs com ssltest inde
Linux与windows文件上传和下载
在没有安装第三方工具的帮助下 能不能直接完成上传一个文件给服务器上 或者从服务器上下载一个文件下来 当然是可以的 你可以通过rz和sz来完成在自己的windows上上传一个文件给服务器 或者直接从服务器下载一个文件 首先第一步使用rz和sz
三种SQL实现聚合字段合并(presto、hive、mysql)
需求 按照项目名 以逗号合并参与人 presto select item name array join array agg name as group name from test test 04 group by item name o
Java版企业电子招标采购系统源代码Spring Boot + 二次开发 + 前后端分离 构建企业电子招采平台之立项流程图
项目说明 随着公司的快速发展 企业人员和经营规模不断壮大 公司对内部招采管理的提升提出了更高的要求 在企业里建立一个公平 公开 公正的采购环境 最大限度控制采购成本至关重要 符合国家电子招投标法律法规及相关规范 以及审计监督要求 通过电子化
swagger注解之@ApiOperation
swagger注解之 ApiOperation 链接 swagger学习一 链接 swagger学习二 ApiOperation 用于方法 表示一个http请求的操作 ApiOperation value 接口说明 httpMethod 接
【Linux】Argument list too long参数列表过长的办法-四种
1 背景 Linux下使用cp mv rm chmod等命令时经常会碰到 Argument list too long 错误 这主要是因为这些命令的参数太长 即文件个数过多 2 解决方案 方案一 将文件群手动划分为比较小的组合 user l
oracle 聚合函数 LISTAGG ,将多行结果合并成一行
LISTAGG 列名 分割符号 oracle 11g 以上的版本才有的一个将指定列名的多行查询结果 用 指定的分割符号 合并成一行显示 例如 表原始数据 需求 将 mb1 Transport License list 表中的数据 根据 tr
设计师winPE 更新支持Z370/Z390系列网卡 集成鲁大师远程协助QQ、检测工具、修复工具等懒得写自己看吧
设计师winPE 更新支持Z370 Z390系列网卡 集成鲁大师远程协助QQ 检测工具 修复工具等懒得写自己看吧 网络远程版单机极速版 链接 https pan baidu com s 1BEraFYvtKNeqRkGljIbTtQ 提取码
卷积运算转换为矩阵乘法
看卷积神经网络的时候 发现代码中计算卷积是通过矩阵乘法来计算的 搜了一下发现网上这方面的资料很少 刚开始找中文的 找到两个 http blog csdn net anan1205 article details 12313593 http
宽表, 窄表, 维度表, 事实表的区别
在数据开发里 会涉及到一些概念 宽表 窄表 维度表 事实表 宽表 把多个维度的字段都放在一张表存储 增加数据冗余是为了减少关联 便于查询 查询一张表就可以查出不同维度的多个字段 窄表 和我们 mysql 普通表三范式相同 把相同维度的字段组
热门标签
逻辑电路
爬取英雄联盟皮肤
fetch用英语解释
集合类
日常学习记录
JavaSE系列
破解Pycharm
人工智能深度学习杂项
微信退款通知
微信退款
构造器
CPlus
l2行情接口
自定义反序列化
自定义序列化
探探提醒对方账号异常
passlib
内存分页
内存分段
内存原理分析篇