关键词:数据库 迭代 递归 多维
一、两种传统的数据库迭代结构算法
对于数据库的迭代结构,有两种传统的算法:递归算法和边界算法。
比如对于下面图1的结构:
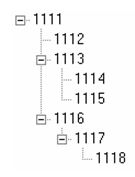
图1
递归算法的数据结构如表1所示:
| 节点id |
节点值 |
父节点id |
| 1 |
1111 |
-2 |
| 3 |
1112 |
1 |
| 4 |
1113 |
1 |
| 5 |
1114 |
4 |
| 6 |
1115 |
4 |
| 7 |
1116 |
1 |
| 8 |
1117 |
7 |
| 9 |
1118 |
8 |
表1
父节点id如为负值,表示这是一个根节点。
从表1可以看出,我们用若干组父-子递归的结构来表达完整的迭代结构。
这种算法很容易理解,但是缺点也很明显:
- 要从任意一个节点展现整个结构时,要从此节点向根节点做一个逆向递归,然后由根节点向所有层的子节点做N次正向递归,数据库的运算开销很大。特别是正向递归到达所有外围节点时要做一个空查询,形成浪费。
- 尽管oracle对递归查询有优化算法,如
select distinct *
from table1
start with 节点值='1111'
connect by prior 节点id=父节点id
这样可以形成以’1111’为根的整个节点树结构。
但是这种优化在统计时是无能为力的,而且此查询返回的结果丢失了很多结构的细节。
下面我们再来分析第二种迭代算法:边界算法。
这种算法有点类似邮递员送信路径的传统数学难题,方法是将节点的边界串起来,同时记录其结构。
对于图1的结构,数据库中记录如表2所示:
| 节点值 |
结构id |
节点顺序 |
节点层次 |
| 1111 |
1001 |
1 |
1 |
| 1112 |
1001 |
2 |
2 |
| 1113 |
1001 |
3 |
2 |
| 1114 |
1001 |
4 |
3 |
| 1115 |
1001 |
5 |
3 |
| 1116 |
1001 |
6 |
2 |
| 1117 |
1001 |
7 |
3 |
| 1118 |
1001 |
8 |
4 |
表2
这里1001是此结构的id。因此我们可以用结构id,仅通过一次查询,就可以将整个结构展现出来。
此算法的缺点是:
- 取子结构麻烦,比如我们要查询1113-1114-1115的子结构,我们要从1113开始将整个结构截取出来,然后分析哪些是它的子结构。
- 数据更新麻烦,在插入或删除某个子结构时,要将节点顺序重新排序。
二、多维迭代算法的原理
所谓多维迭代算法,是指任意一个节点,在继承父节点的特性同时,创建自己的特性维度。
对于图1的结构,其数据库中的记录如表3所示:
| 节点值 |
结构id |
节点维度 |
| 1111 |
1001 |
1 |
| 1112 |
1001 |
1,1 |
| 1113 |
1001 |
1,2 |
| 1114 |
1001 |
1,2,1 |
| 1115 |
1001 |
1,2,2 |
| 1116 |
1001 |
1,3 |
| 1117 |
1001 |
1,3,1 |
| 1118 |
1001 |
1,3,1,1 |
表3
我们可以看出,任意一个节点都有其结构中的唯一维度,而且往左减一个维度就是其父节点的维度。因此我们要取子结构也非常方便,只要对节点维度从左开始截取若干位进行匹配就可以了。这种结构无需递归,因此统计时效率得到级数级的提升。
下面介绍多维迭代的一些扩展算法:
- 查询子结构
如查询1113的子结构,算法是取结构id=1001,且节点2维维度=’1,2’,返回1113、1114、1115共3条数据,且1114和1115是1113的子节点。
2. 插入子结构
如我们要将图2的子结构插入1116这个节点上,即2221为1116的子节点:

图2
则运算方法为:首先获得2221的新维度(1,3,2),然后将整个子结构的第1维度更新为(1,3,2),最后最新子结构的结构id(1001)。
3. 取消子结构
假如我们要取消1116-1117-1118这个子结构,那么首先获得新的结构id,然后用1替换子结构的前2维(1,3)。
4. 替换子结构
假如我们用图2的子结构替换图1中1116-1117-1118的子结构,或者说用2221替换1116,则首先临时记录1116的结构id(1001)和维度(1,3),然后取消1116子结构,然后更新2221子结构的id和维度。
三、多维迭代算法的典型应用
- ERP缺料统计
我们知道ERP的BOM是一个典型的递归结构,在进行缺料统计时,要把最顶层的料号展开成所有底层料号的集合,因此有很多的递归。
如果我们在表3的多维结构上增加数量属性,就可以得到一个类似BOM的结构体。即使我们不改动BOM,也可以通过第三方开发,把BOM结构映射为一个多维结构范式,从而减少递归运算。
2. 包装装配数据统计
生产上的包装和装配数据通常采用递归结构,如果要对多组数据进行统计的话,要进行成千上万次的递归,效率极低。
如果包装和装配数据都采用多维结构存储的话,只要一次查询就可以导出统计报表了,而且报表数据还保留了完整的结构。
3. 数据仓库应用
如果要对递归数据进行数据仓库处理的话,只要将递归结构映射为一个多维结构,就可以方便地储存和统计递归数据,同时保留其结构。
4. 家谱
我们只要在多维结构上分别定义父亲维度和母亲维度,就可以方便地进行多数家谱运算。