提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Shapley交互阶的计算
首先一阶的计算公式

二阶(交互值)计算
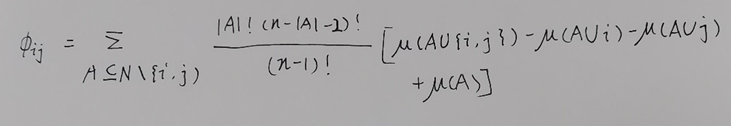
三阶计算
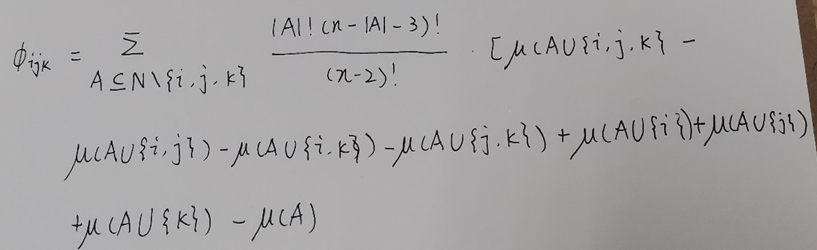
一般式(来源于文章Fuzzy measures and integrals in MCDM)
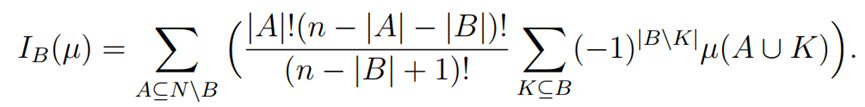
举个例子,设N={1,2,3}

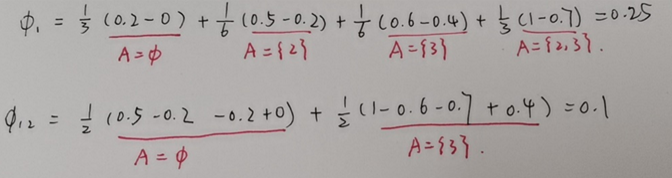
特别地,计算时需要知道所有特征组合,因此复杂度很高,达到指数级别。
关于树结构Shap的计算
如果采用树结构的话,只需要遍历树所有可能的路径上的特征即可
(文章Explainable AI for Trees: From Local Explanations to Global Understanding)
直观例子
如果只有一个特征分裂,即树深度为1,假设特征有10个,如果以标准的计算方法,对于每一条样本,都要计算特征0在各个位置引入时的贡献度,特征1在各个位置引入时的贡献度,以此类推,起码要计算2^10种特征是否引入的可能性,才能最终推算出每个特征的贡献度。但是树的结构仍然深度为1,可能只使用特征0做了一次分裂就结束了。
有了 algorithm 1 之后, 我们可以把不同特征组合方式输入进去来求得各个特征的贡献度, 但特征组合仍然是 2^M 的指数级复杂度. 这里一个很自然的想法就是我们不需要遍历特征组合情况, 而只要遍历树的路径的所有可能即可, 在遍历过程中把计算的 path 信息记录下来, 然后在叶子节点就能计算出这条 path 的特征贡献信息. 这就是作者在文中提出的 Algorithm 2 的大致思路.
例如某个节点 x, 使用了特征 a 来做分裂条件, 那么在经过这个节点时, 不管特征组合如何变化, 只可能有特征 a 的存在与缺失两种情况, 这也是对应到代码中的 one path 和 zero path 的 fraction.
在计算交互值上,原来的公式可以变为
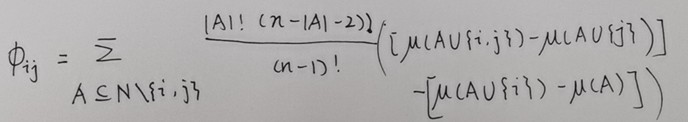
这个公式表示这个SHAP交互作用值可以解释为特征j存在时,特征i的SHAP值和特征j不存在时,特征i的SHAP值之间的差值。
使用Explainable AI for Trees中的算法2两次,一次忽略固定存在的特征j,一次不存在特征j。

x是我们要解释的实例,f(x)是当前实例的模型输出,fx(S) ≈ E[f(x) | xS]是以特征值集合S为条件的模型输出的估计期望值
通过将每个特征一次一个地引入到模型输出的条件期望函数fx(S) ≈ E[f(x) | xS]中,来计算Shapley值,并且将在每个步骤产生的变化归因于所引入的特征;然后在所有可能的特征排序上平均这个过程